Golang基础笔记
Golang基础笔记
1.第一个 Go 程序
1.1 安装 Go
Go语言官网:https://golang.google.cn/doc/install,提供了安装包以及引导流程。
以 Windows 为例,进入windows安装包下载地址:https://golang.google.cn/dl/,选择要下载的 msi 格式的安装包。

下载后,按照引导执行即可,出现如下所示,说明go语言安装完成。
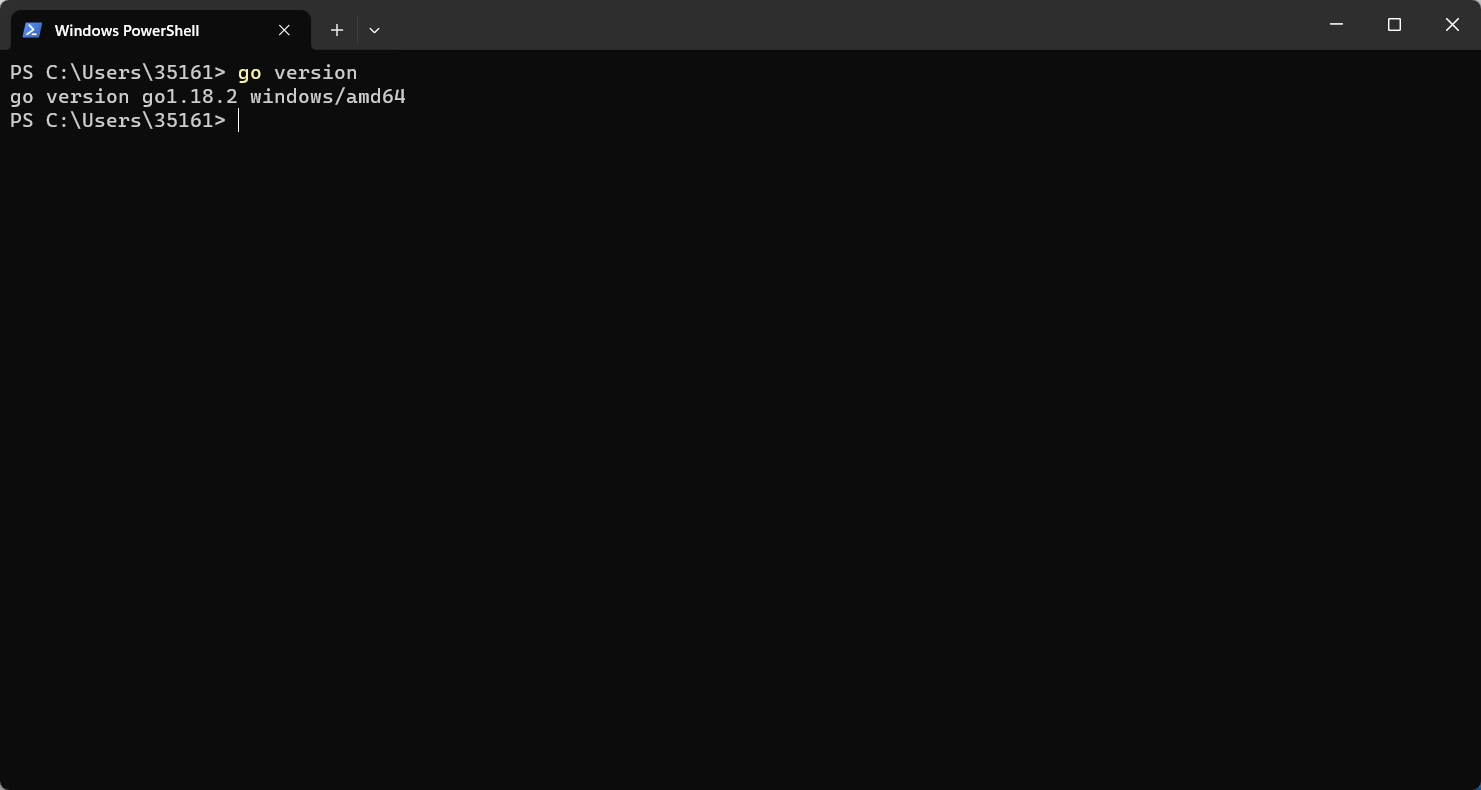
安装完成后,打开windows终端,输入 go version,出现安装的go语言版本信息,安装成功。
1.2 第一个 Go 程序
1.2.1 创建 Go 项目
可以使用 vscode 或者 Goland 进行代码的开发,这里以Go land为例。
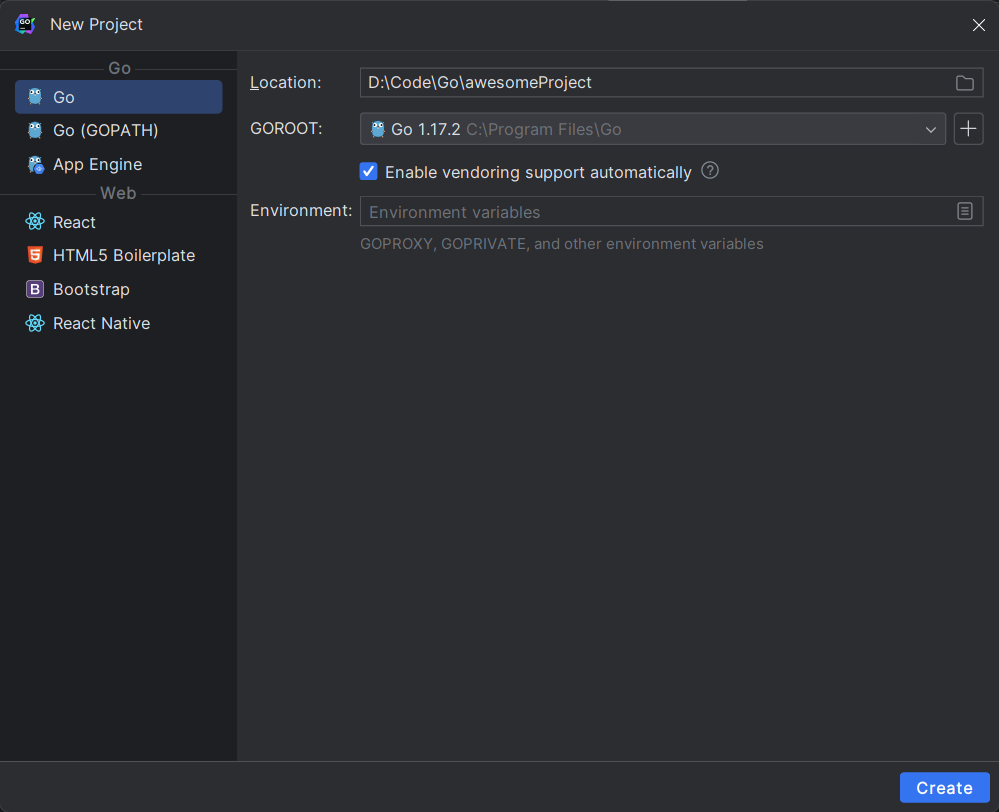
Location也即项目路径,GOROOT也即要使用的Go语言版本,确认后点击 Create 初始化项目,初始化之后打开新项目。
在项目中,新建一个 .go 文件,编写如下go语言代码。
package main
import "fmt"
func main() {
fmt.Println("Hello World!")
}1.2.2 编译&运行
Go语言是编译性的静态语言(和 Java、C 一样),在运行 Go 程序之前,先要将其编译成二进制可执行文件,按照如下步骤对编写的 Go 代码进行编译和执行。
# 编译go语言代码
go build hello.go
# 运行编译后可执行的文件
.\hello.exe
也可以直接使用 go run 命令实现 Go 代码的运行,执行该命令时,Go 编译器会在内存中编译并执行你的程序,而不是生成一个独立的可执行文件。

2.GO 项目工程管理(Go Modules)
Go 1.11 版本开始,官方提供了 Go Modules 进行项目管理,Go 1.13开始,Go项目默认使用 Go Modules 进行项目管理。
使用 Go Modules的好处时不再需要依赖 GOPATH,可以在任意位置进行 Go 项目的创建,还能够通过 GOPROXY 配置镜像源,解决 Go 语言依赖下载慢的问题。
2.1 通过Go Modules创建新项目
该节使用 Go 语言创建项目,实现一个简单的计算器。
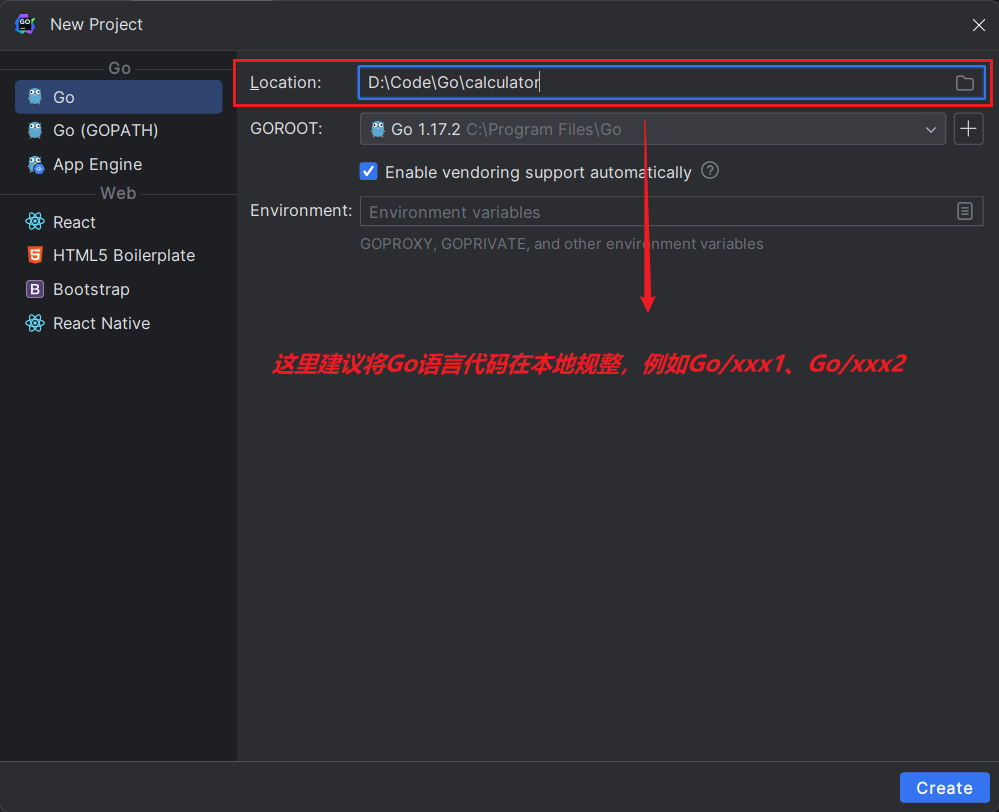
点击 Enviroment 右侧的加号,添加 GOPROXY 变量。
# name
GOPROXY
# value
https://goproxy.io,direct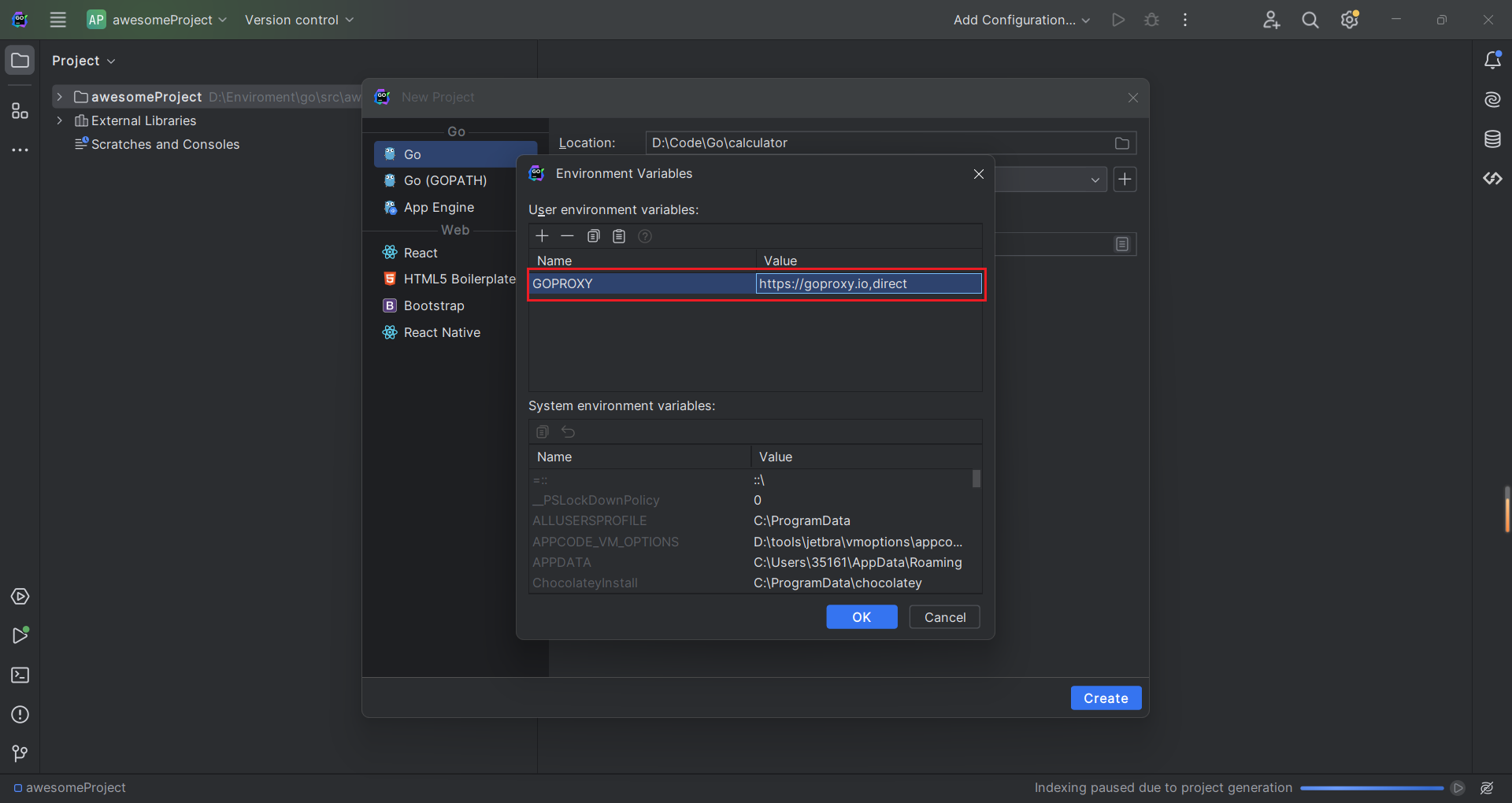
环境变量设置后,点击 OK ,完成后点击 Create 创建 Go 项目。
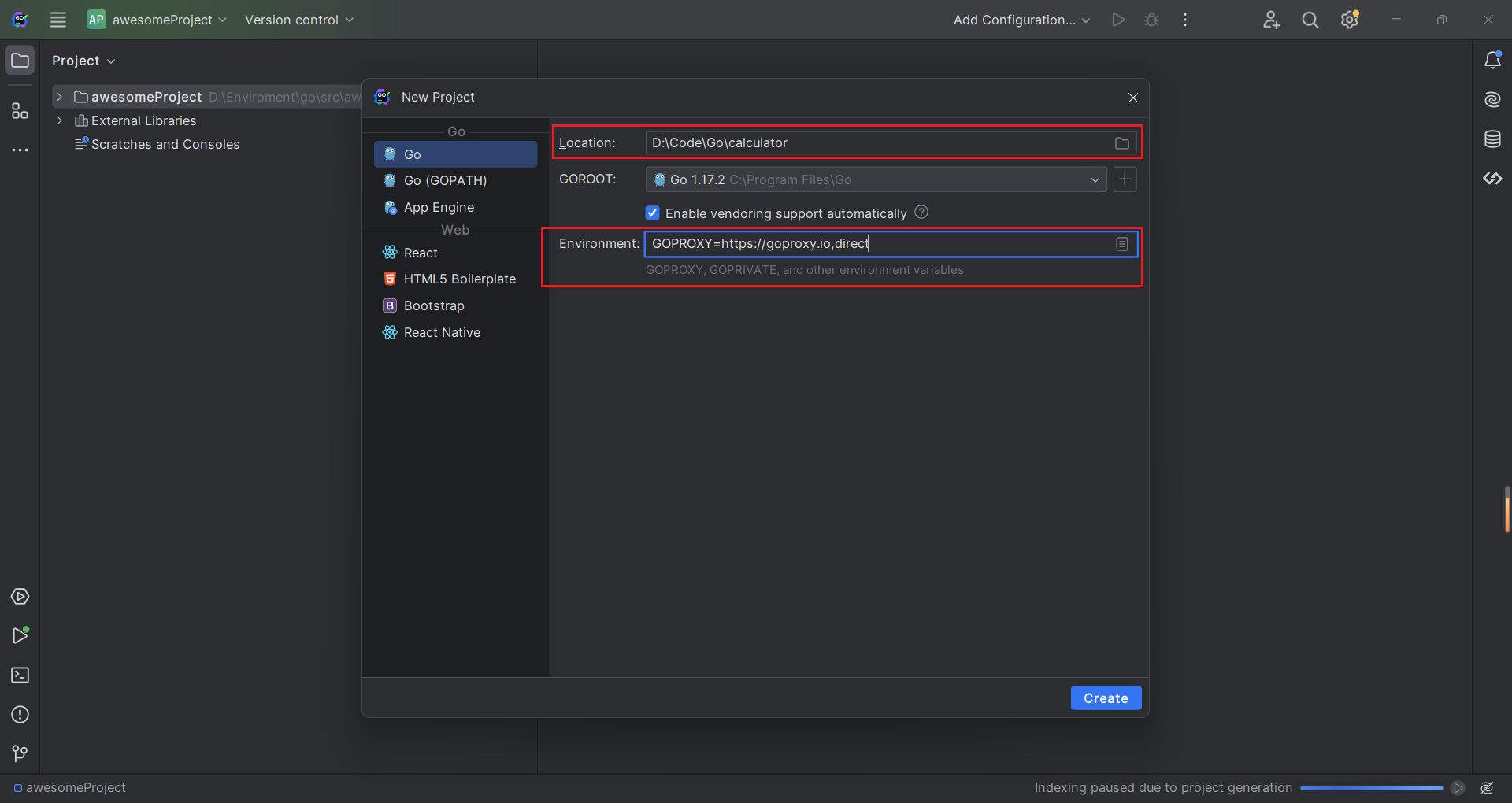
创建的项目结构如下,项目目录下有一个 go.mod 文件用来管理项目中用到的依赖。
2.2 编写计算器工程代码
计算器工程项目分为两部分:
- 项目的入口文件 main.go,该文件最终会被编译成可执行的二进制文件。
- 算法库,名为 custommath,每个计算操作对应一个 Go 文件,例如 add.go 用于加法计算。
首先编写项目的入口文件 main.go,项目代码如下:
package main
// 引入其它包
import (
"calculator/custommath"
"fmt"
"os"
"strconv"
)
// 定义一个用于打印程序使用指南的函数
var Usage = func() {
fmt.Println("USAGE: calc command [arguments] ...")
fmt.Println("\nThe commands are:\n\tadd\t计算两个数值相加\n\tsqrt\t计算一个非负数的平方根")
}
// 程序入口函数
func main() {
/*
* 用于获取命令行参数,注意程序名本身是第一个参数,
* 比如 calc add 1 2 这条指令,第一个参数是 calc
*/
args := os.Args
// 除程序名本身外,至少需要传入两个其它参数,否则退出
if args == nil || len(args) < 3 {
Usage()
return
}
// 第二个参数表示计算方法
switch args[1] {
// 如果是加法的话
case "add":
// 至少需要包含四个参数
if len(args) != 4 {
fmt.Println("USAGE: calc add <integer1><integer2>")
return
}
// 获取待相加的数值,并将类型转化为整型
v1, err1 := strconv.Atoi(args[2])
v2, err2 := strconv.Atoi(args[3])
// 获取参数出错,则退出
if err1 != nil || err2 != nil {
fmt.Println("USAGE: calc add <integer1><integer2>")
return
}
// 从 custommath 包引入 Add 方法进行加法计算
ret := custommath.Add(v1, v2)
// 打印计算结果
fmt.Println("Result: ", ret)
// 如果是计算平方根的话
case "sqrt":
// 至少需要包含三个参数
if len(args) != 3 {
fmt.Println("USAGE: calc sqrt <integer>")
return
}
// 获取待计算平方根的数值,并将类型转化为整型
v, err := strconv.Atoi(args[2])
// 获取参数出错,则退出
if err != nil {
fmt.Println("USAGE: calc sqrt <integer>")
return
}
// 从 simplemath 包引入 Sqrt 方法进行平方根计算
ret := custommath.Sqrt(v)
// 打印计算结果
fmt.Println("Result: ", ret)
// 如果计算方法不支持,打印程序使用指南
default:
Usage()
}
}创建 custommath 目录,在该目录下创建 add.go、sqrt.go 两个文件,分别编写对应的 Add、Sqrt方法。
add.go
package custommath
func Add(a int, b int) int {
return a + b
}sqrt.go
package custommath
import "math"
func Sqrt(i int) int {
v := math.Sqrt(float64(i))
return int(v)
}执行 go build,编写写好的 Go 代码。

通常 Go 代码并非在本地执行,而是要上传到服务器主机,例如 Linux、Unix,在上传 .exe 文件就不可以了,可以执行如下操作,生成 linux 操作系统的可执行文件。
# 设置环境变量
$env:GOOS="linux"
$env:GOARCH="amd64"
# arm
$env:GOARCH="arm"
# 编译
go build -o calculator
go build -o jmxCo这里是在 powershell 执行的,直接在 cmd 设置环境变量,生成的文件显示不是 Linux 下可执行的二进制文件,具体原因暂不清楚,具体的操作以及报错如下:
set GOOS=linux
set GOARCH=amd64
# 编译
go build -o calculator
powershell 中按照如下,可以正常生成 linux 系统下的可执行文件。

上传到 linux 主机能够正常运行。

3.单元测试、问题定位及代码调试
3.1 单元测试
Go 语言中,支持为功能模块编写单元测试代码。
单元测试文件默认以同一目录文件名后缀 _test 作为标识,例如 add.go 的单元测试文件为 add_test.go 文件。
add.go代码如下:
package custommath
func Add(a int, b int) int {
return a + b
}add_test.go代码如下:
package custommath
import "testing"
func TestAdd(t *testing.T) {
r := Add(1, 2)
if r != 3 {
t.Errorf("Add(1, 2) failed. Got %d, expected 3.", r)
}
}测试文件及原文件处于同一目录下。
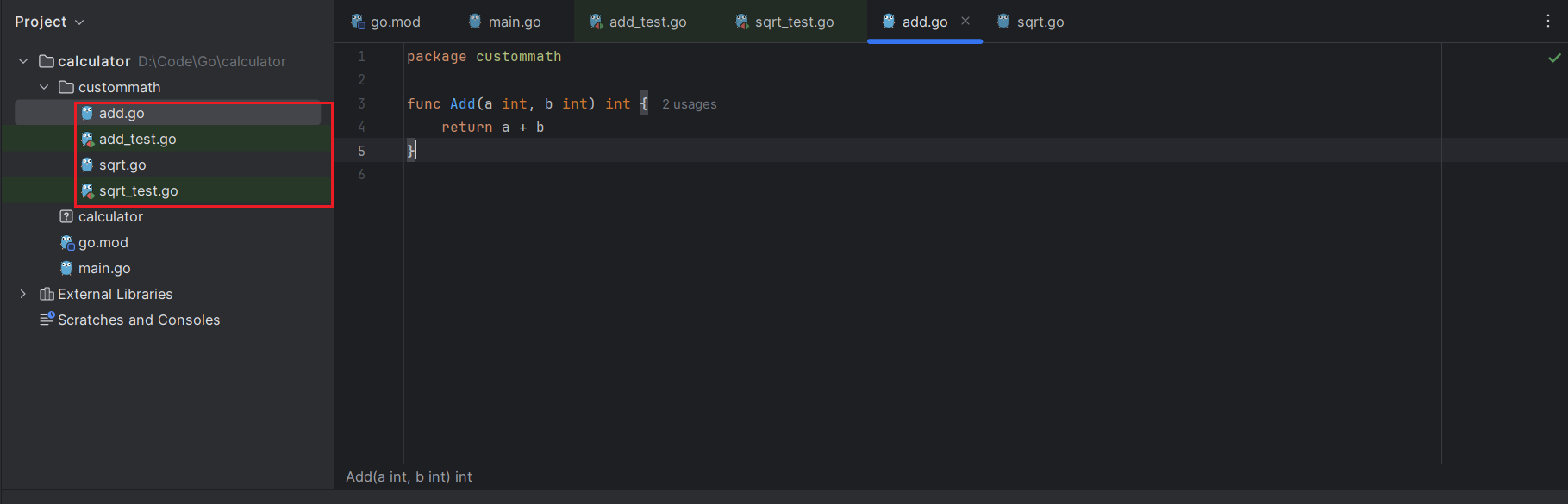
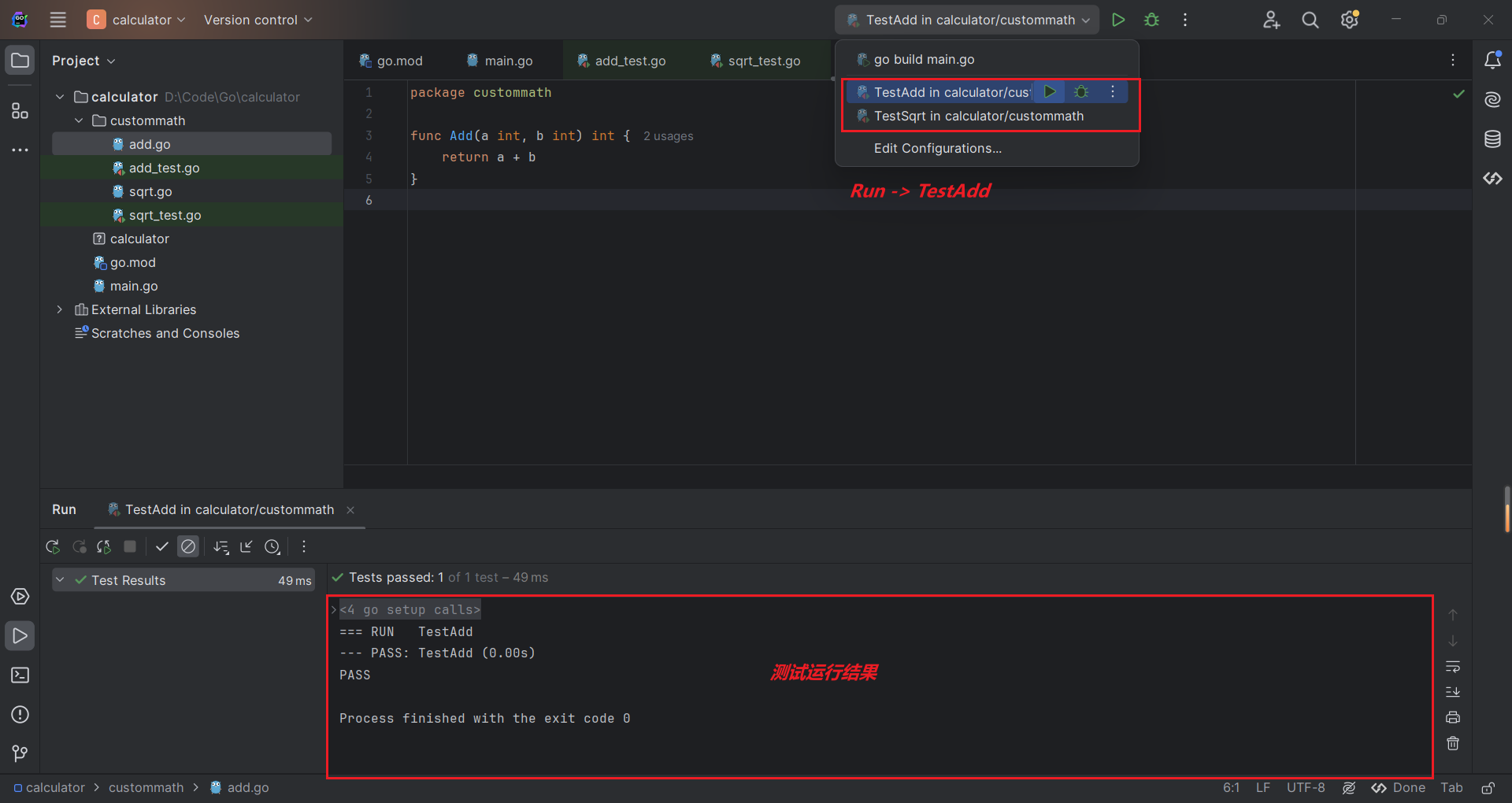
Go Land选择Test模块进行运行,输出运行的结果。
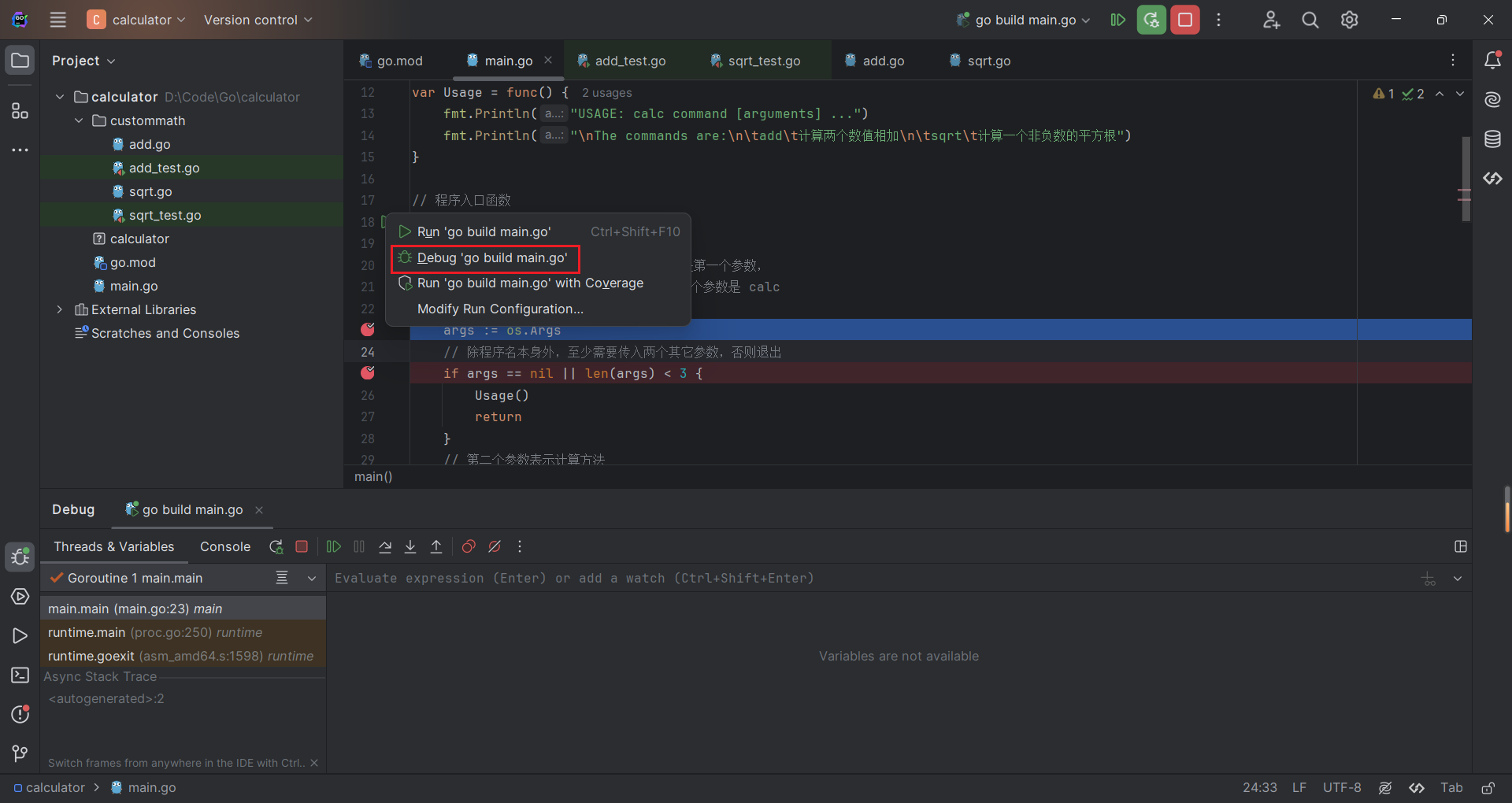
3.2 代码调试
与 C++、Python 一样在代码文件中标记断点即可,执行 Debug 即可。
4.Go 数据类型
4.1 Go语言中的变量和常量
4.1.1 变量
变量相当于是对一块数据存储空间的命名,程序可以通过定义一个变量来申请一块数据存储空间,之后可以通过引用变量名来使用这块存储空间。
Go 语言是强类型静态语言,所以变量的声明与赋值方式与 PHP/Python 等动态语言相比有很大的区别。
**动态语言(弱类型语言)**是运行时才确定数据类型的语言,变量在使用之前无需申明类型,通常变量的值是被赋值的那个值的类型。比如Php、Asp、JavaScript、Python、Perl等等。
**静态语言(强类型语言)**是编译时变量的数据类型就可以确定的语言,大多数静态语言要求在使用变量之前必须声明数据类型。比如Java、C、C++、C#等。
4.1.1.1 变量声明和规则
Go 语言引入了关键字 var,并且将数据类型信息放在变量名之后,此外,变量声明语句不需要使用分号作为结束符,例如声明一个类型为 int 的变量 v1,示例如下:
var v1 int
// 也可以将若干需要声明的变量放置在一起
var (
v1 int
v2 string
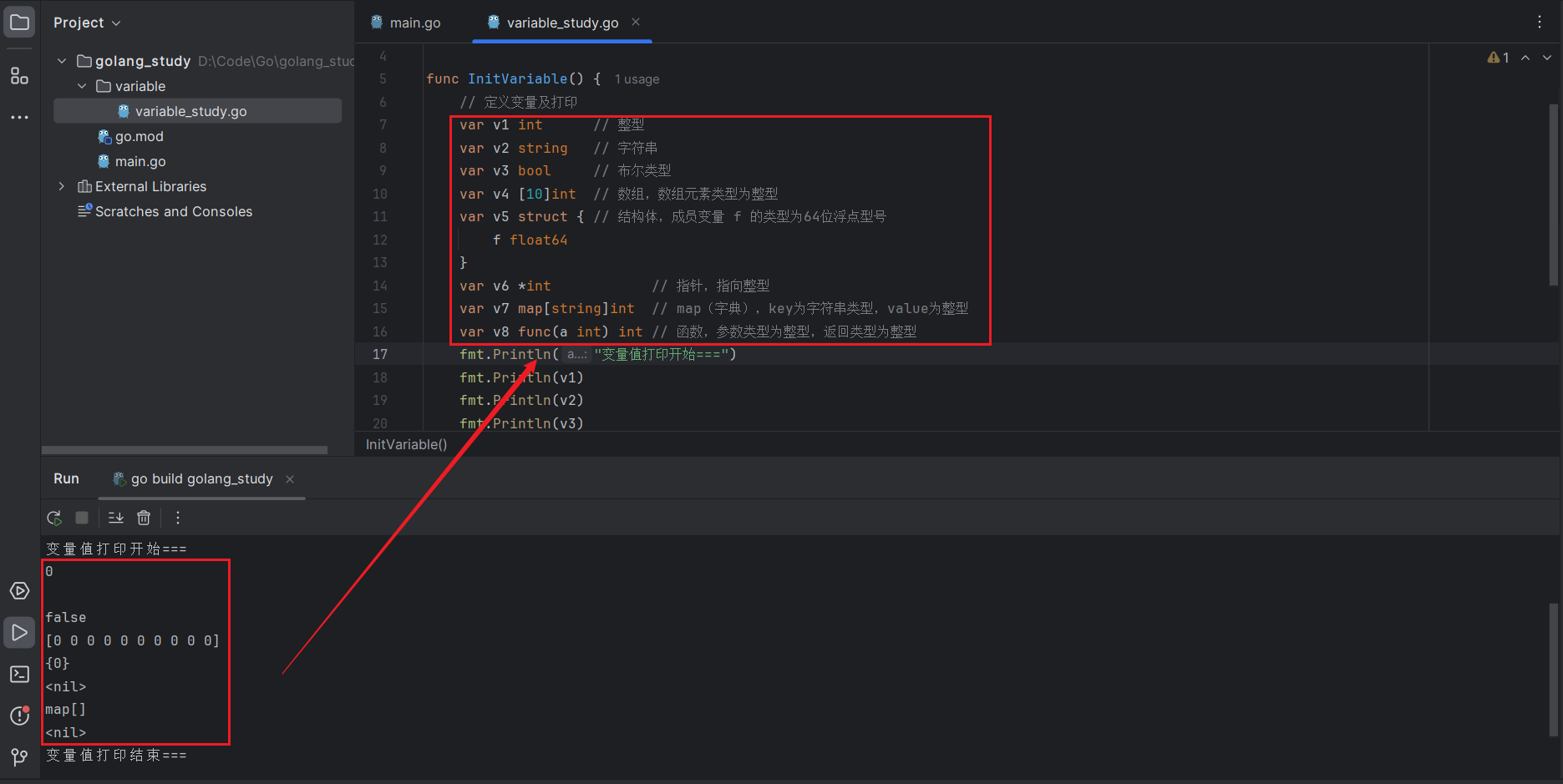
)Go 语言支持多种数据类型,这里先简单展示一下
var v1 int // 整型
var v2 string // 字符串
var v3 bool // 布尔类型
var v4 [10]int // 数组,数组元素类型为整型
var v5 struct ( // 结构体,成员变量 f 的类型为64位浮点型号
f float64
)
var v6 *int // 指针,指向整型
var v7 map[string]int // map(字典),key为字符串类型,value为整型
var v8 func(a int) int // 函数,参数类型为整型,返回类型为整型变量在声明之后,系统会自动将变量值初始化为对应类型的零值,这里输出一下上面定义的变量。
如果变量名包含多个单词,Go 语言变量命名规则遵循驼峰命名法,即首个单词小写,每个新单词的首字母大写,如 userName,但如果你的全局变量希望能够被外部包所使用,则需要将首个单词的首字母也大写。
4.1.1.2 变量初始化
如果声明变量时想要同时对变量值进行初始化,可以通过以下这些方式:
var v1 int = 10 // 方式一,常规的初始化操作
var v2 = 10 // 方式二,此时变量类型会被编译器自动推导出来
v3 := 10 // 方式三,可以省略 var,编译器可以自动推导出v3的类型代码测试如下:
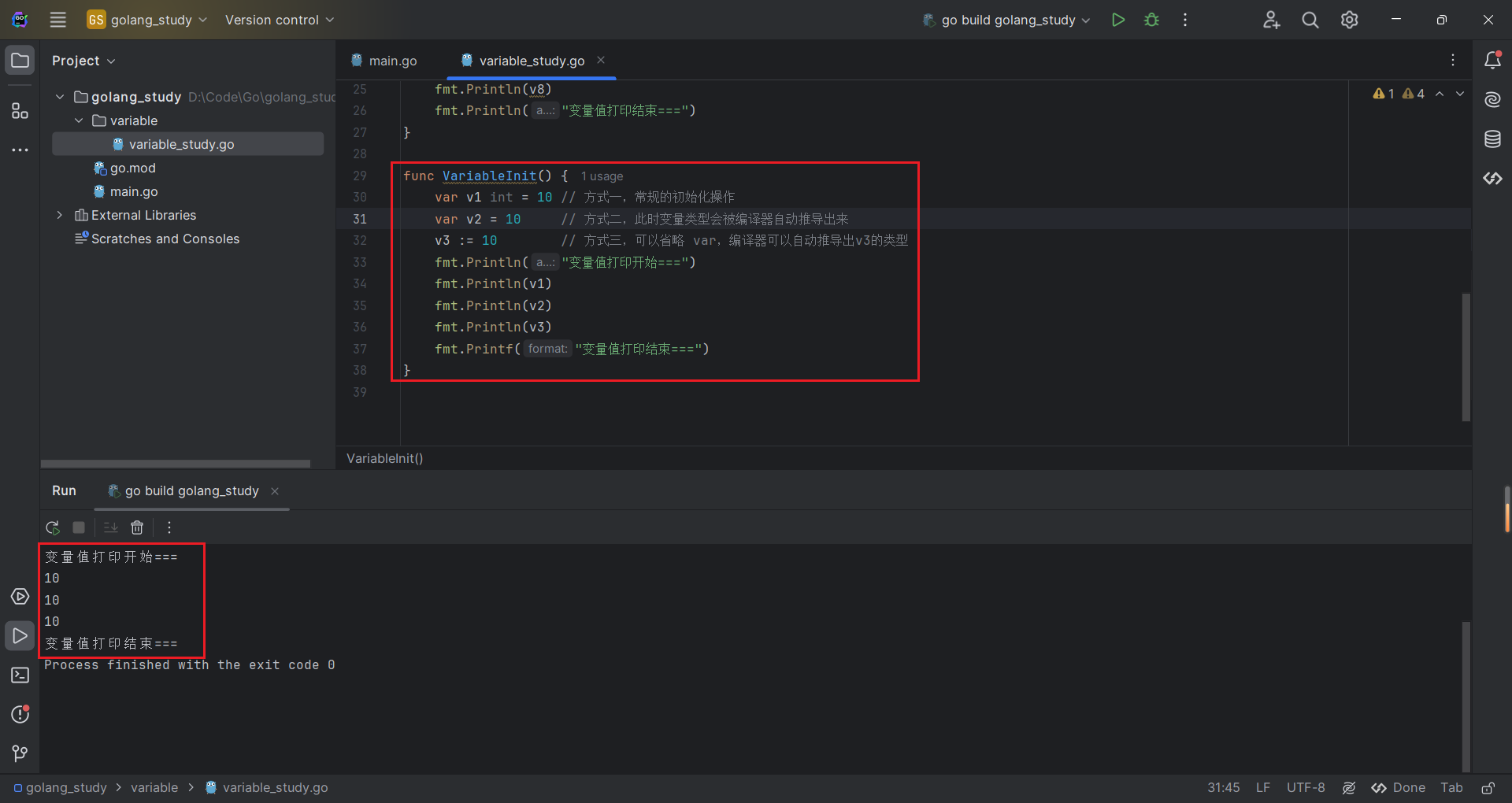
这里注意Go语言变量声明使用的符号是:= ,而不是=。
变量进行初始化时,可以不必指定数据类型,这里让Go看上像是静态类型语言,但是与 PHP/Python/JavaScript 等动态语言不同的是,这个推导是在编译期做的,而不是运行时,因此 Go 语言还是不折不扣的静态语言。
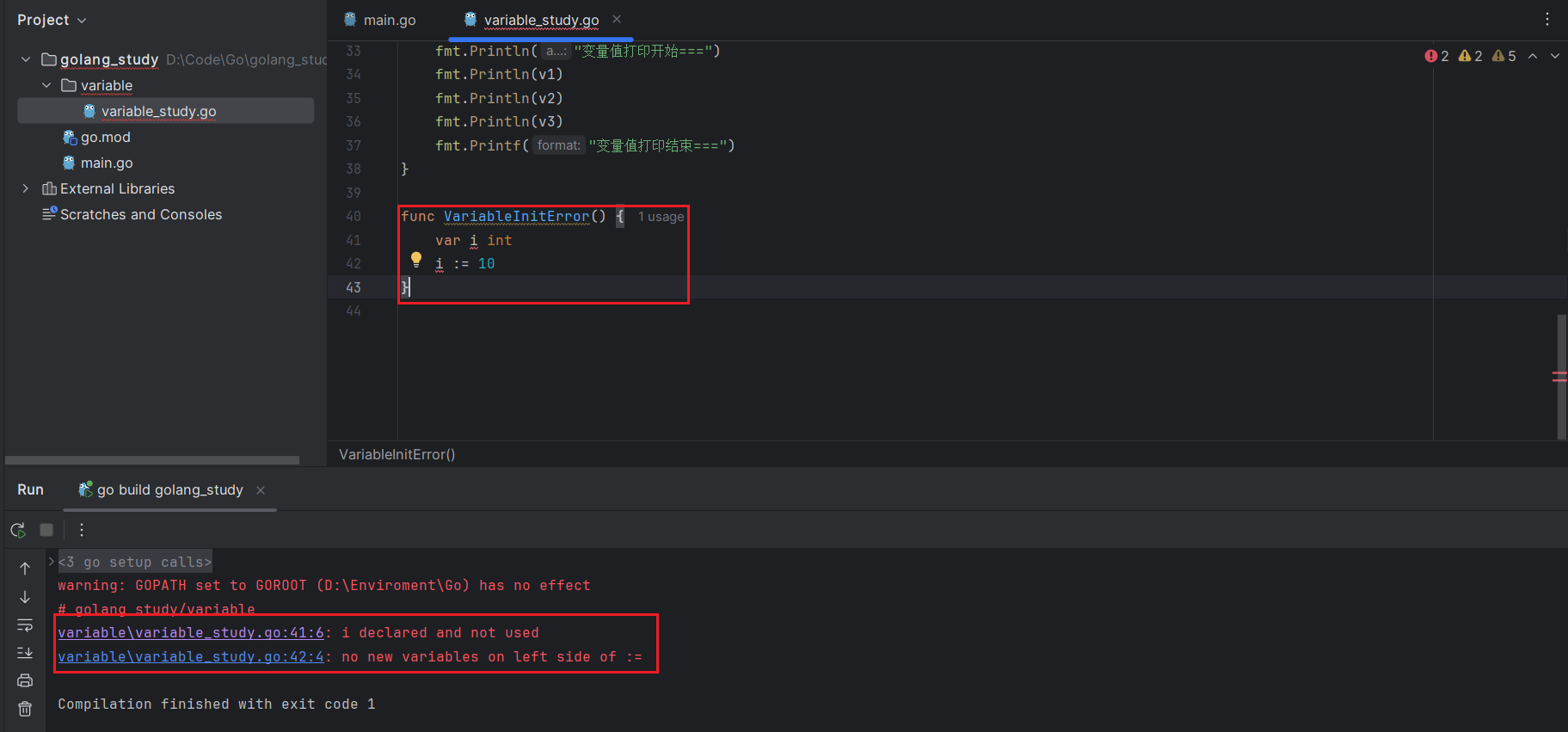
另外,出现在 := 运算符左侧的变量应该是未声明过的,否则会导致编译错误,比如下面这个写法:
var i int
i := 2会出现如下的报错
4.1.1.3 变量赋值与多重赋值
在 Go 语言中,变量初始化和变量赋值是两个不同的概念,变量初始化及变量声明和赋值为一条语句,变量赋值则是先声明变量,再对其进行赋值,初始化只能执行一次,赋值则可以执行多次,下面是变量赋值过程:
// 变量赋值
var v10 int
v10 = 123
// 多重赋值
i,j = j,i代码测试:

4.1.1.4 匿名变量
我们在使用传统的强类型语言编程时,经常会出现这种情况,即在调用函数时为了获取一个值,却因为该函数返回多个值而不得不定义一堆没用的变量。
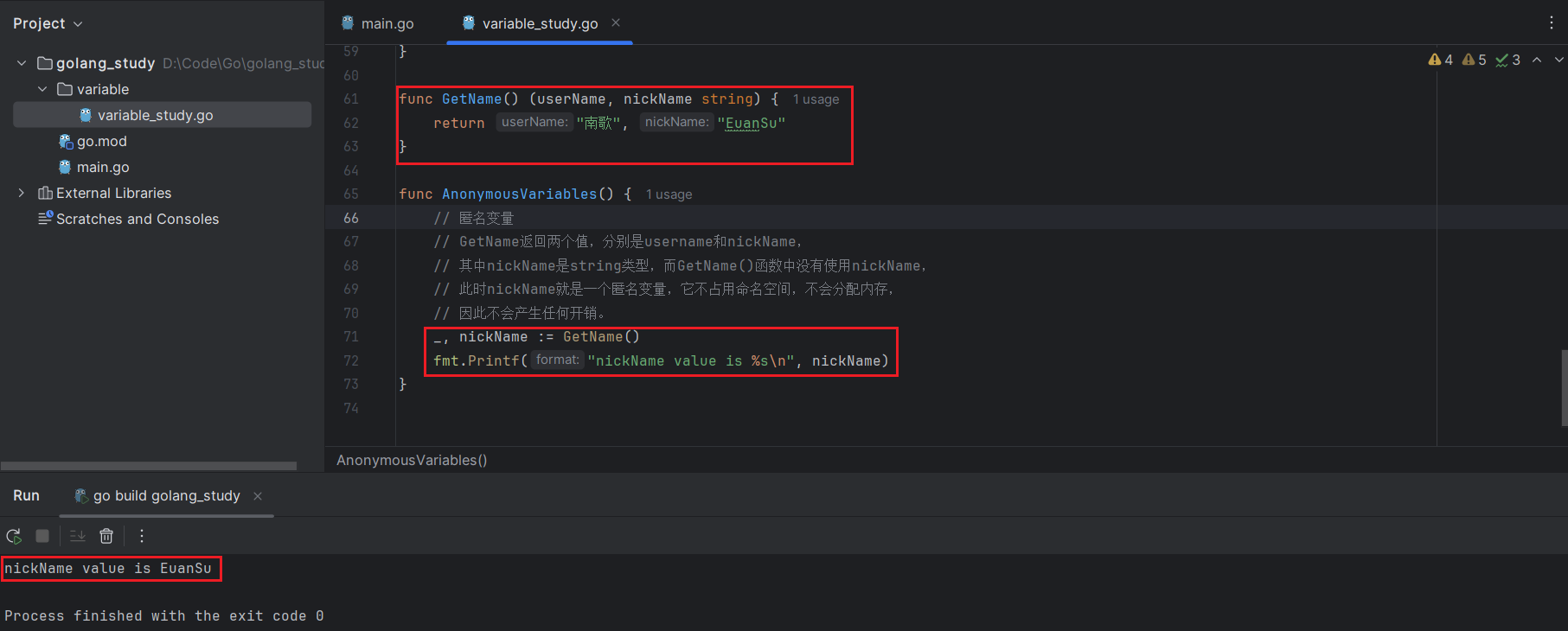
匿名变量语法:
func GetName() (userName, nickName string) {
return "南歌", "EuanSu"
}
func AnonymousVariables() {
// 匿名变量
// GetName返回两个值,分别是username和nickName,
// 其中nickName是string类型,而GetName()函数中没有使用nickName,
// 此时nickName就是一个匿名变量,它不占用命名空间,不会分配内存,
// 因此不会产生任何开销。
_, nickName := GetName()
fmt.Printf("nickName value is %s\n", nickName)
}
4.1.1.5 变量的作用域
每个变量在程序中都有一定的作用范围,称之为作用域。如果一个变量在函数体外声明,则被认为是全局变量,可以在整个包甚至外部包(变量名以大写字母开头)使用,不管你声明在哪个源文件里或在哪个源文件里调用该变量。在函数体内声明的变量称之为局部变量,它们的作用域只在函数体内,函数的参数和返回值变量也是局部变量。
尽管变量的标识符必须是唯一的,但你可以在某个代码块的内层代码块中使用相同名称的变量,此时外部的同名变量将会暂时隐藏(结束内部代码块的执行后隐藏的外部同名变量又会出现,而内部同名变量则被释放),任何的操作都只会影响内部代码块的局部变量。
4.1.2 常量
在 Go 语言中,常量是指编译期间就已知且不可改变的值,常量只可以是数值类型(包括整型、 浮点型和复数类型)、布尔类型、字符串类型等标量类型。Go 语言中,我们可以通过 const 关键字来定义常量(遵循 C 语言的约定)。
4.1.2.1 常量的定义
通过 const 关键字定义常量时,可以指定常量类型,也可以省略(编译时会自动推导),常见的常量定义方式如下:
const Pi float64 = 3.14159265358979323846
const zero = 0.0 // 无类型浮点常量
const ( // 通过一个 const 关键字定义多个常量,和 var 类似
size int64 = 1024
eof = -1 // 无类型整型常量
)
const u, v float32 = 0, 3 // u = 0.0, v = 3.0,常量的多重赋值
const a, b, c = 3, 4, "foo" // a = 3, b = 4, c = "foo", 无类型整型和字符串常量代码执行测试:
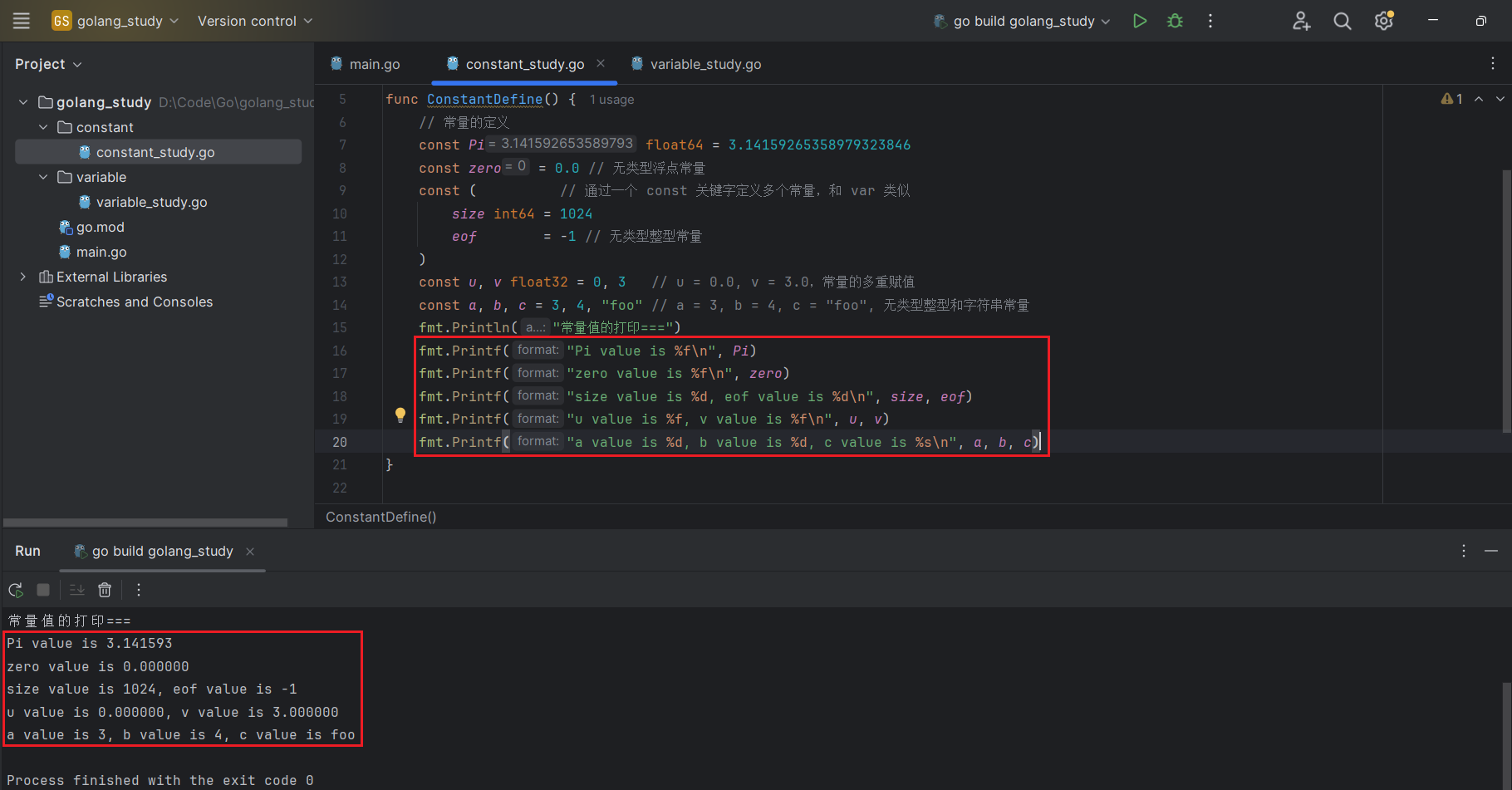
由于常量的赋值是编译时期执行的,因此赋值的操作中不能出现任何需要运行才能得到结果的函数,例如如下语句就会导致编译错误:
func GetNumber() int {
return 100
}
const num = GetNumber()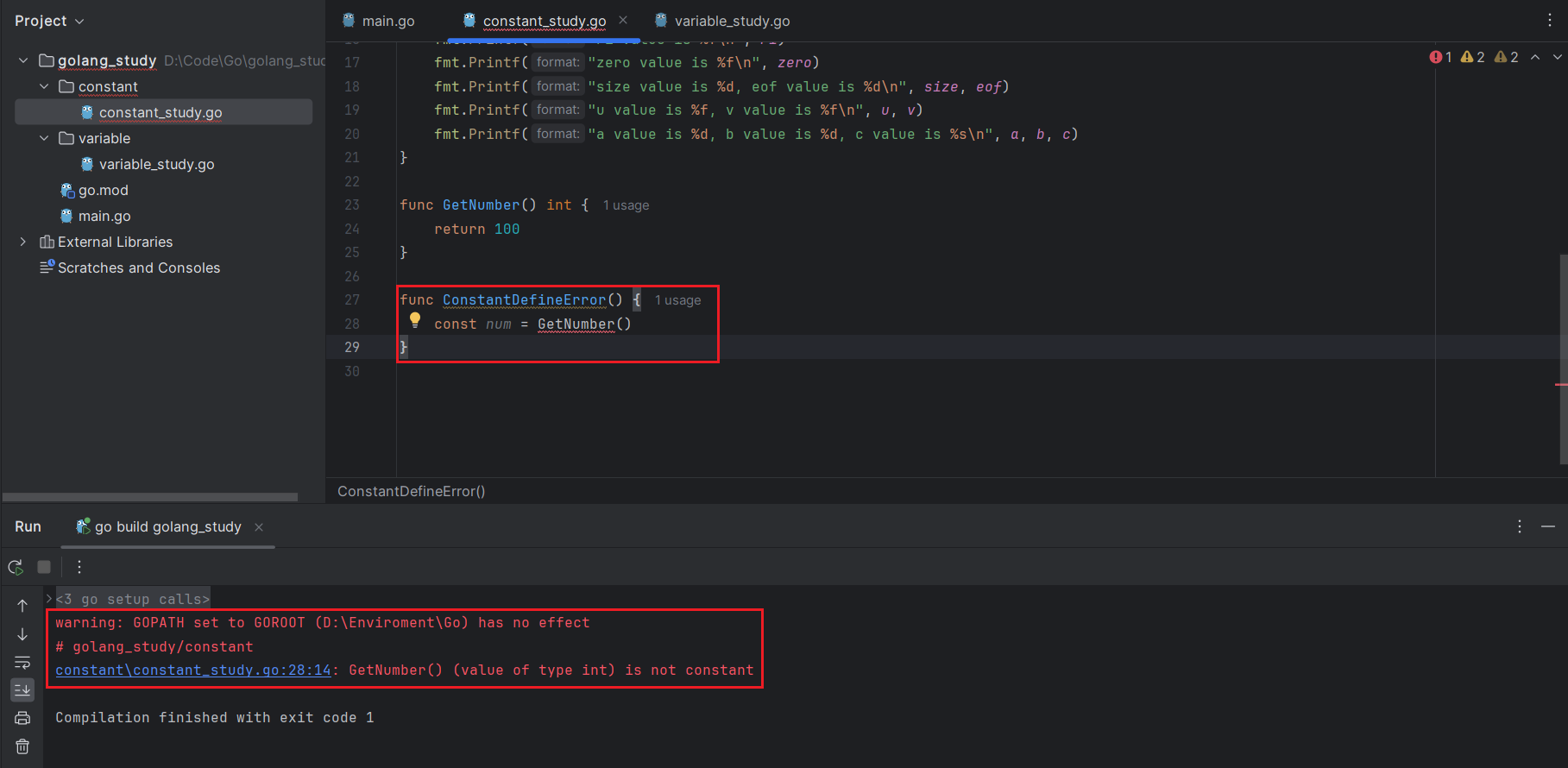
4.1.2.2 预定义常量
GO语言预定义了常量:true、false 和 iota。
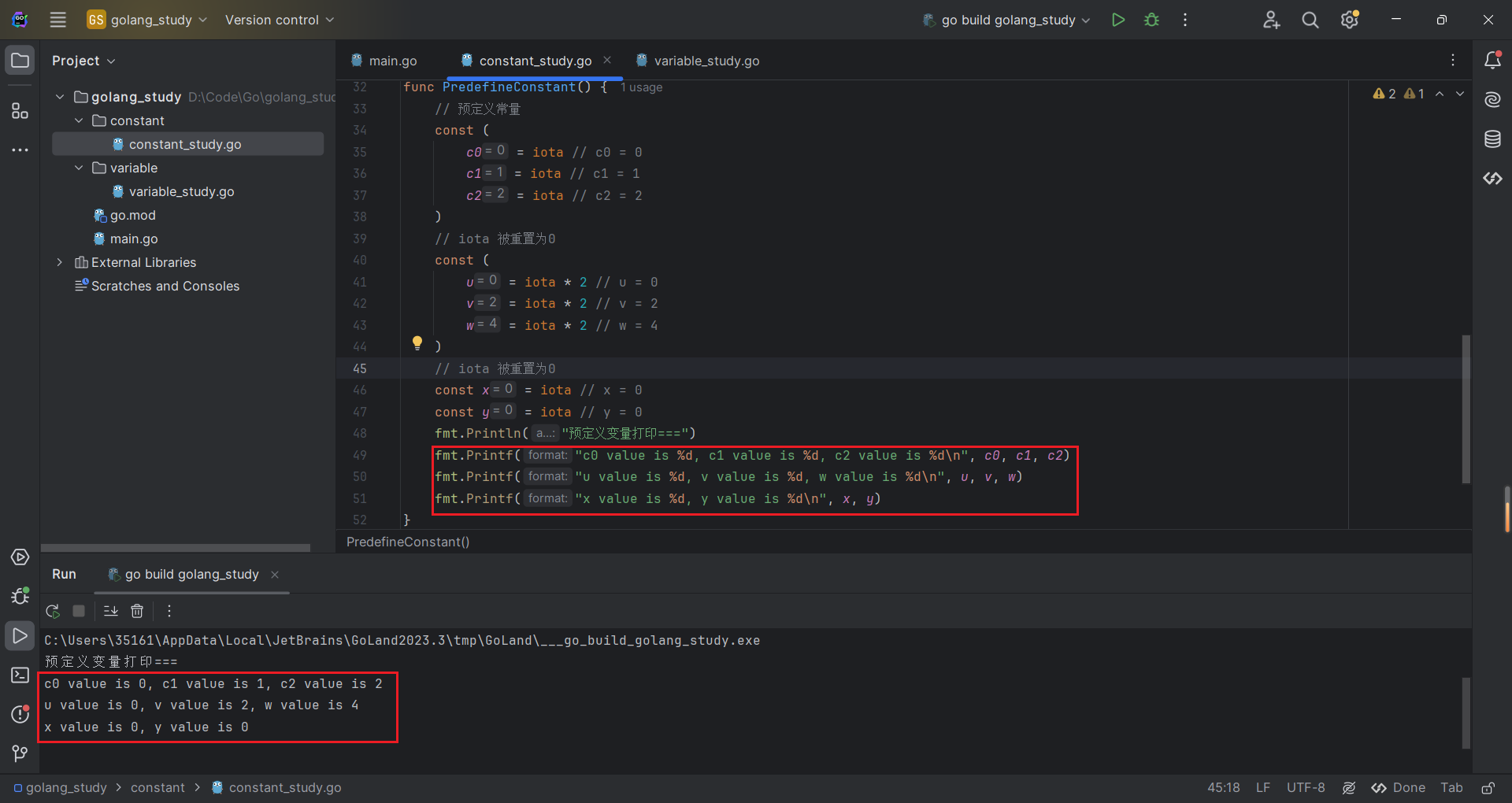
iota 比较特殊,认为是一个能够被编译器修改的常量,每一个 const 关键字出现时被重置为 0,每出现一次 iota,其所代表的数字就会自动加1.
const ( // iota 被重置为 0
c0 = iota // c0 = 0
c1 = iota // c1 = 1
c2 = iota // c2 = 2
)
const (
u = iota * 2; // u = 0
v = iota * 2; // v = 2
w = iota * 2; // w = 4
)
const x = iota; // x = 0
const y = iota; // y = 0代码运行测试:
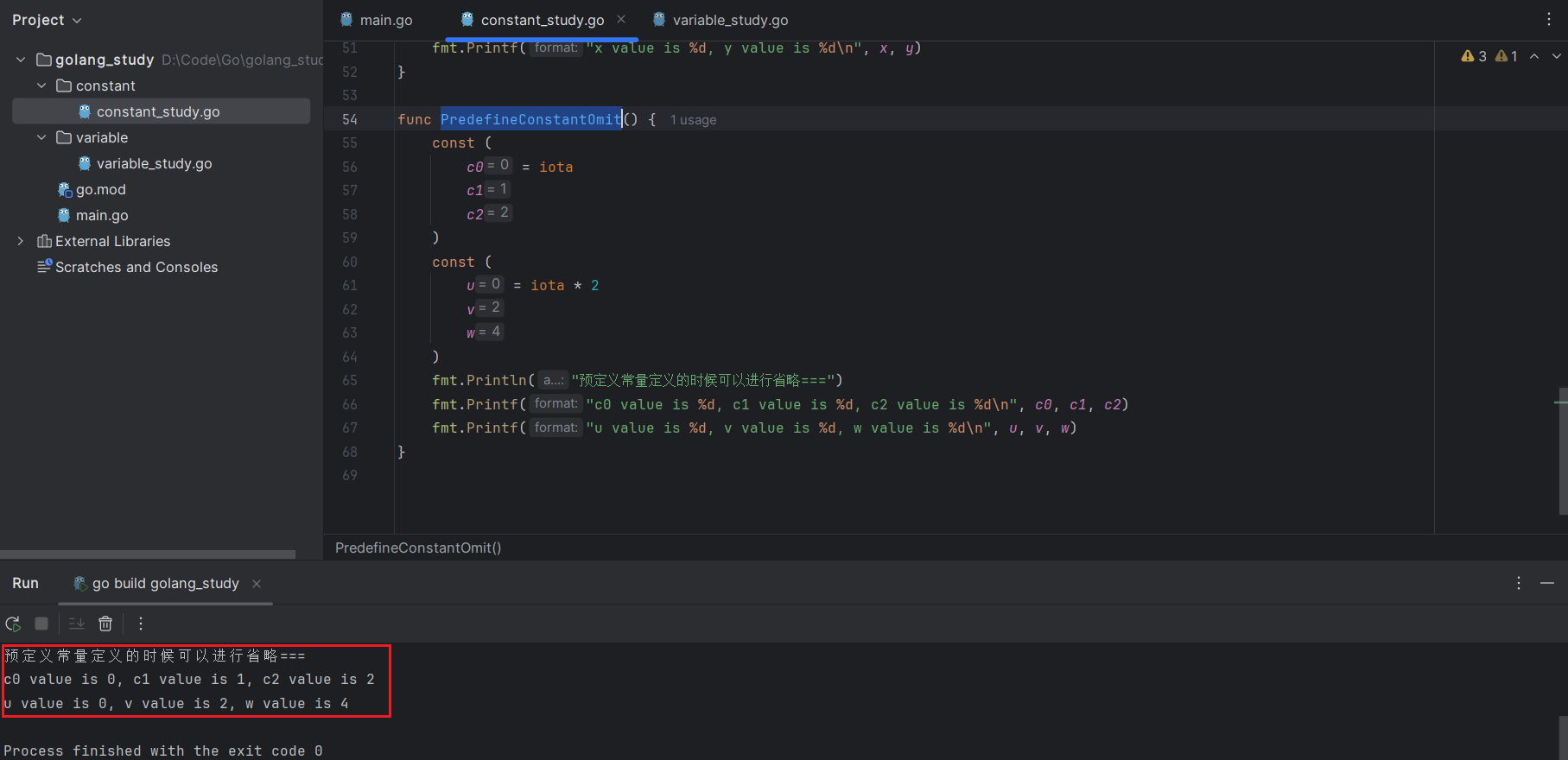
如果两个 const 的赋值语句的表达式是一样的,那么还可以省略后一个赋值表达式。因此,上面的前两个 const 语句可简写为:
const (
c0 = iota
c1
c2
)
const (
u = iota * 2
v
w
)代码运行测试:
4.1.2.3 枚举
此外,常量还可以用于枚举。
枚举中包含了一系列相关的常量,比如下面关于一个星期中每天的定义。Go 语言并不支持其他语言用于表示枚举的 enum 关键字,而是通过在 const 后跟一对圆括号定义一组常量的方式来实现枚举。
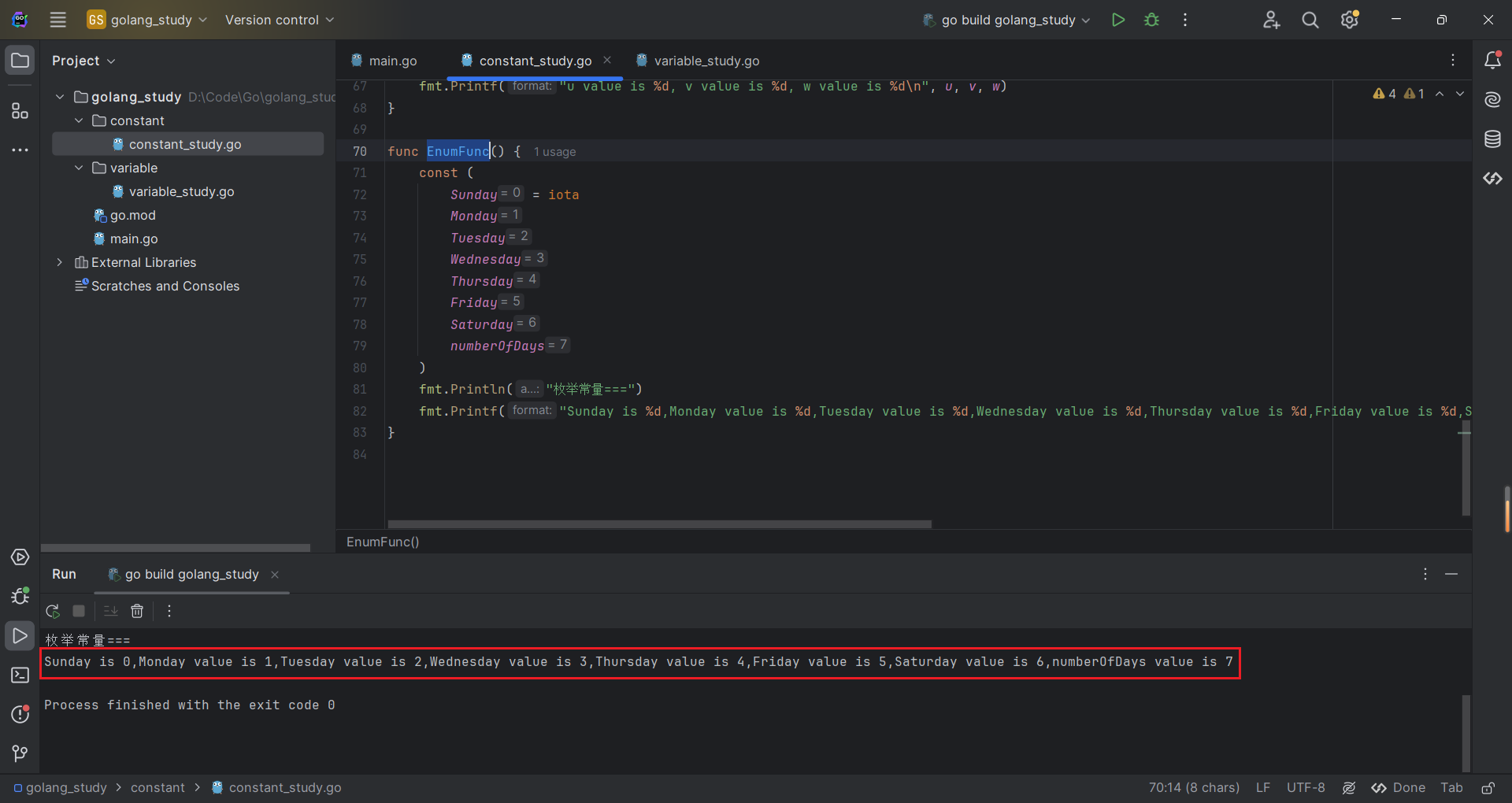
下面是一个常规的 Go 语言枚举表示法,其中定义了一系列整型常量:
const (
Sunday = iota
Monday
Tuesday
Wednesday
Thursday
Friday
Saturday
numberOfDays
)代码运行测试:
4.1.2.4 常量的作用域
和函数体外声明的变量一样,以大写字母开头的常量在包外可见(类似于 public 修饰的类属性),比如上面介绍的 Pi、Sunday 等,而以小写字母开头的常量只能在包内访问(类似于通过 protected 修饰的类属性),比如 zero、numberOfDays 等。
函数体内声明的常量只能在函数体内生效。
4.2 GO 支持的数据类型
Go 语言内置对以下这些基本数据类型的支持:
- 布尔类型:bool
- 整型:int8、byte、int16、int、uint、uintptr 等
- 浮点类型:float32、float64
- 复数类型:complex64、complex128
- 字符串:string
- 字符类型:rune
- 错误类型:error
GO 语言也支持以下复合类型:
- 指针(pointer)
- 数组(array)
- 切片(slice)
- 字典(map)
- 通道(chan)
- 结构体(struct)
- 接口(interface)
与其他静态语言相比,Go语言新增了通道类型,该类型主要用于并发编程时不同协程间的通信。
结构体类似于面向对象编程中的类(class),Go语言沿用了C语言的该语法,Go语言还把接口单独作为一个类型提取出来。
4.2.1 布尔类型
布尔类型的关键字为bool,可赋值且只可以赋值为预定义常量true和false,示例代码如下:
var v1 bool
v1 = true
v2 := (1 == 2) // v2 也会被推导为 bool 类型
fmt.Println("布尔类型初始化打印===")
fmt.Println(v1, v2)代码运行测试

Go语言是强类型语言,变量类型一旦确定,就不能够将其他类型的值赋值给该变量,因此,布尔类型不能接受其它类型的赋值,也不支持自动或强制的类型转换。以下操作会导致Go语言的编译错误:
var b bool
b = 1
b = boo1(1)Go 语言中,不同类型的值不能使用 == 或 != 运算符进行比较,在编译期就会报错,示例代码如下:
b := (false == 0)在编译期报错:

4.2.2 整型和运算符
4.2.2.1 整型
整型是所有编程语言中最基础的数据类型,Go语言默认支持如下整型类型:
| 类型 | 长度(单位:字节) | 说明 | 值范围 | 默认值 |
|---|---|---|---|---|
int8 | 1 | 带符号8位整型 | -128~127 | 0 |
uint8 | 1 | 无符号8位整型,与 byte 类型等价 | 0~255 | 0 |
int16 | 2 | 带符号16位整型 | -32768~32767 | 0 |
uint16 | 2 | 无符号16位整型 | 0~65535 | 0 |
int32 | 4 | 带符号32位整型,与 rune 类型等价 | -2147483648~2147483647 | 0 |
uint32 | 4 | 无符号32位整型 | 0~4294967295 | 0 |
int64 | 8 | 带符号64位整型 | -9223372036854775808~9223372036854775807 | 0 |
uint64 | 8 | 无符号64位整型 | 0~18446744073709551615 | 0 |
int | 32位或64位 | 与具体平台相关 | 与具体平台相关 | 0 |
uint | 32位或64位 | 与具体平台相关 | 与具体平台相关 | 0 |
uintptr | 与对应指针相同 | 无符号整型,足以存储指针值的未解释位 | 32位平台下为4字节,64位平台下为8字节 | 0 |
Go语言针对整型类型划分较多,可以根据需要选择适合的类型以节省内存开支。
注:
如未注明整型的类型,Go语言默认设置
Go语言中,这些整型都是不同的数据类型,例如 int 和 int32 在Go语言中被认为是不同的数据类型,编译器也不会自动进行类型转换,如下类似的操作就会报错:
var intValue1 int8
// Go语言会将未声明的数字默认为int类型
intValue2 := 8
intValue1 = intValue2 // 编译错误,intValue1是int8类型,intValue2是int类型编译运行报错

使用强制类型转换可以解决这个编译错误:
var intValue1 int8
// Go语言会将未声明的数字默认为int类型
intValue2 := 8
intValue1 = int8(intValue2)这里出现了一个错误 intValue1 declared and not used,如果出现该错误,建议在赋值语句前添加 _ 来忽略这个报错。
var intValue1 int8
intValue2 := 8 // Go语言会将未声明的数字默认为int类型
// intValue1 = intValue2 // 编译错误,intValue1是int8类型,intValue2是int类型
_ = intValue1 //忽略 declared and not used 错误
intValue1 = int8(intValue2) // 正确,将intValue2转换为int8类型
fmt.Printf("intValue1:%d, intValue2:%d\n", intValue1, intValue2)我们还可以通过 intValue := uint8(intValue2) 这种方式同时完成类型转化和赋值操作。
4.2.2.2 运算符
4.2.2.2.1 算术运算符
GO 语言支持所有常规的整数四则运算:+、-、*、/ 和 %(取余只能用于整数),由于 GO 语言是强类型语言,不同类型的整型值不能够直接进行运算,否则会报错。
intValue3 := intValue1 + intValue2 // int + int8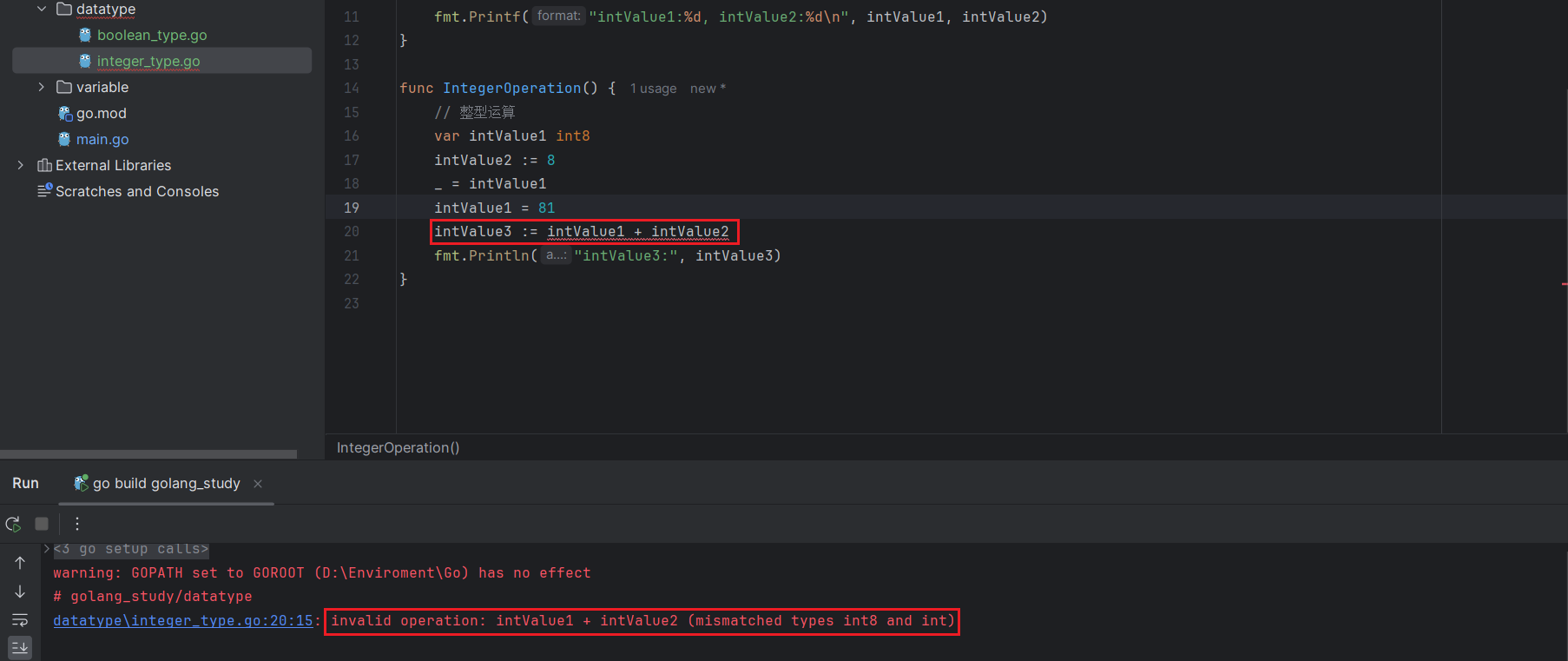
intValue3 := int(intValue1) + intValue2 // 使用强类型进行转换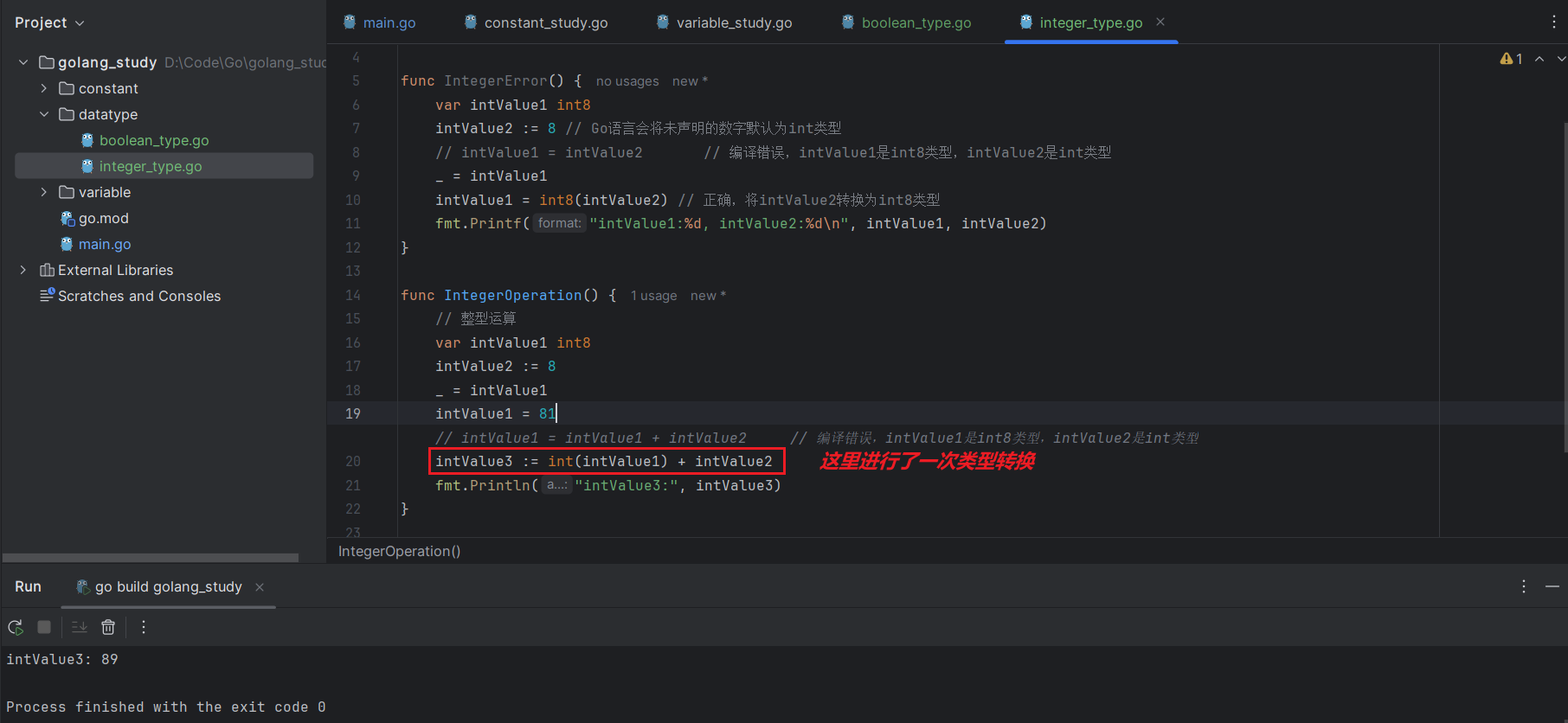
此外,也需要注意整型的溢出
var intValue1 int8
intValue1 = 128 // int8 可取值的范围在 -128~127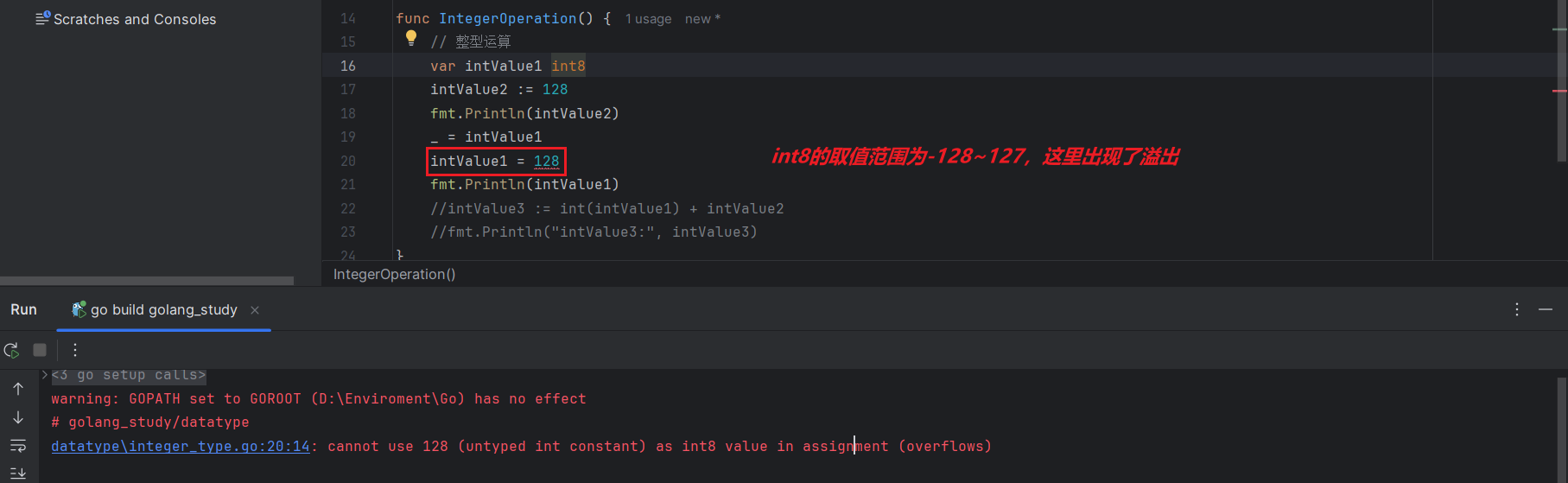
Go 语言中也支持自增/自减运算符,即 ++、--,是只能作为语句,不能作为表达式,且只能用作后缀,不能放到变量前面:
intValue1 := 10
intValue1++ // 有效,intValue1 的值变成 11
intValue1-- // 有效,intValue1 的值变成 10
intValue1 = intValue1++ // 无效,编译报错
--intValue1 // 无效,编译报错同样支持+=、-=、*=、/=、%= 这种快捷写法:
intValue1, intValue2 := 10, 20
intValue1 += intValue2
intValue1 -= intValue2
intValue1 *= intValue2
intValue1 /= intValue2
intValue1 %= 3
4.2.2.2.2 比较运算符
Go 语言支持以下几种常见的比较运算符: >、<、==、>=、<= 和 !=,比较运算符运行的结果是布尔值。
intValue1, intValue2 := 10, 20
if intValue1 <= intValue2 {
fmt.Println("intValue1 <= intValue2")
}需要注意,不同的整型类型同样不能够使用比较运算符,但所有的比较运算都可以直接和数字进行比较。
var intValue3 int8 = 10
if intValue3 == 10 {
fmt.Println("intValue3 == 10")
}
// 需要注意溢出的问题,这里的直接比较是编译自动进行的转换
// 编译报错:128 (untyped int constant) overflows int8
if intValue3 == 128 {
fmt.Println("intValue3 == 128")
}4.2.2.2.3 位运算符
Go 语言支持以下这几种位运算符:
| 运算符 | 含义 | 结果 |
|---|---|---|
x & y | 按位与 | 把 x 和 y 都为 1 的位设为 1 |
| `x | y` | 按位或 |
x ^ y | 按位异或 | 把 x 和 y 一个为 1 一个为 0 的位设为 1 |
^x | 按位取反 | 把 x 中为 0 的位设为 1,为 1 的位设为 0 |
x << y | 左移 | 把 x 中的位向左移动 y 次,每次移动相当于乘以 2 |
x >> y | 右移 | 把 x 中的位向右移动 y 次,每次移动相当于除以 2 |
位运算符代码测试:
var intValue1 uint8
var intValue2 uint8
intValue1 = 255 // 1111 1111
intValue2 = 0 // 0000 0000
fmt.Println("intValue1 & intValue2:", intValue1&intValue2) // 按位与,0
fmt.Println("intValue1 | intValue2:", intValue1|intValue2) // 按位或,255
fmt.Println("intValue1 ^ intValue2:", intValue1^intValue2) // 按位异或,255
fmt.Println("^intValue1:", ^intValue1) // 按位取反 0
fmt.Println("intValue1 << 1:", intValue1<<1) // 左移1位,254
fmt.Println("intValue1 >> 1:", intValue1>>1) // 右移1位,127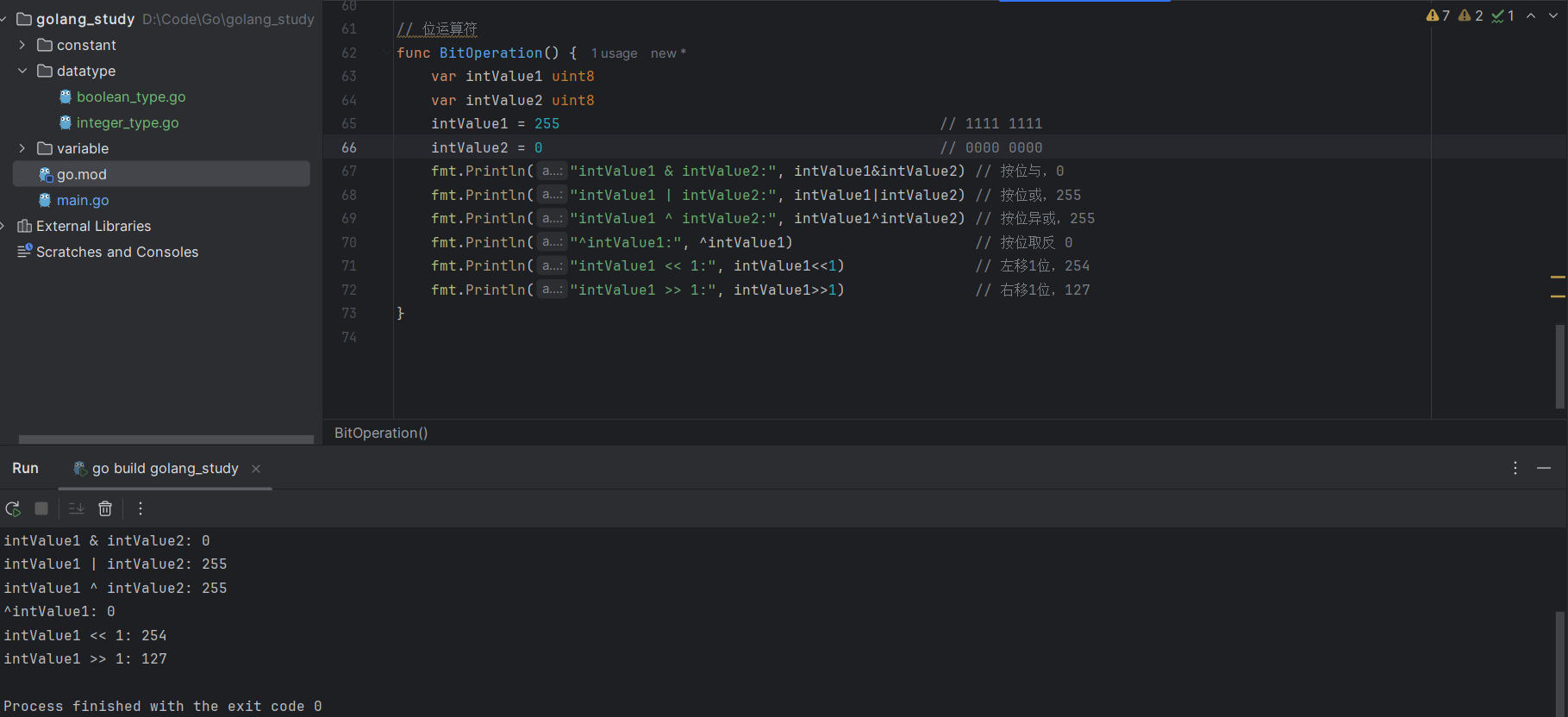
4.2.2.2.3 逻辑运算符
Go语言支持以下逻辑运算符:
| 运算符 | 含义 | 结果 |
|---|---|---|
x && y | 逻辑与运算符(AND) | 如果 x 和 y 都是 true,则结果为 true,否则结果为 false |
| `x | y` | |
!x | 逻辑非运算符(NOT) | 如果 x 为 true,则结果为 false,否则结果为 true |
代码运行测试:
intValue1, intValue2 := 10, 20
if intValue1 > 0 && intValue2 > 0 {
fmt.Println("intValue1 > 0 && intValue2 > 0")
}
if intValue1 > 15 || intValue2 > 15 {
fmt.Println("intValue1 > 15 || intValue2 > 15")
}
fmt.Println("!(intValue1 > 15):", !(intValue1 > 15))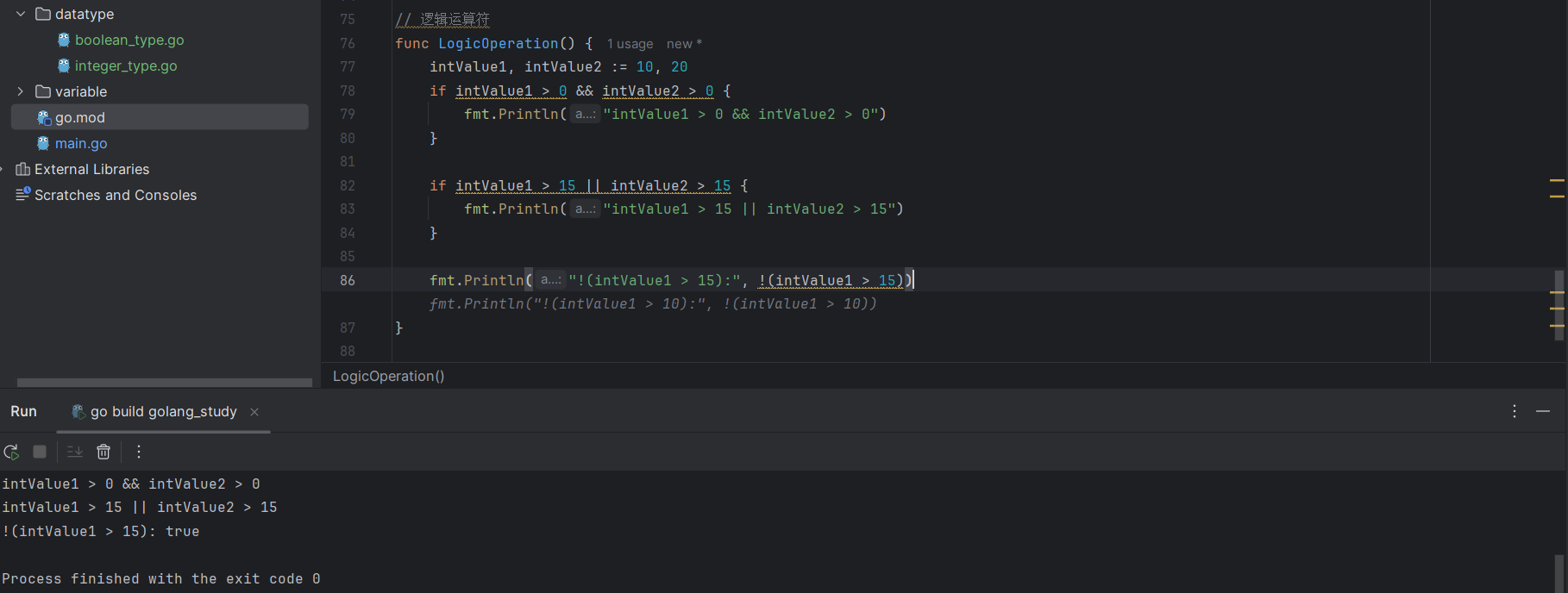
4.2.2.2.3 运算符优先级
// 优先级自高向低进行排列
^(按位取反) !
* / % << >> & &^
+ - | ^(按位异或)
== != < <= > >=
&&
||4.2.3 浮点型与复数类型
4.2.3.1 浮点型
4.2.3.1.1 浮点型的表示
浮点型也叫浮点数,用于表示包含小数点的数据,比如 3.14、1.00 都是浮点型数据。
Go语言中的浮点数采用 IEEE-754 标准的表达式,定义了两个类型:float32 和 float64,其中float32是单精度浮点数,可以精确到小数点后7位(类似于PHP、Java等语言的float类型),float64是双精度浮点数,可以精确到小数点后15位(类似于PHP、Java等语言的double类型)。
Go语言中,定义一个浮点型变量的代码如下:
var floatValue1 float32
floatValue1 = 10
floatValue2 := 10.0 // 如果不加小数点,floatValue2 会被推导为整型而不是浮点型
floatValue3 := 1.1e-10对于浮点类型需要被自动推导的变量,其类型将被自动设置为 float64,而不管赋值给它的数字是否是用 32 位长度表示的。因此,对于以上的例子,下面的赋值将导致编译错误:
floatValue1 = floatValue2
floatValue1 = float32(floatValue2) // 不同浮点类型的赋值,必须要进行类型强制转换在实际的开发中,应该尽可能地使用 float64 类型,因为 math 包中所有有关数学运算的函数都会要求接收这个类型。
4.2.3.1.2 浮点数的精度
浮点数不是一种精确的表达方式,因为二进制无法精确表示所有十进制小数,比如 0.1、0.7 这种,如下代码进行演示:
floatValue4 := 0.1
floatValue5 := 0.7
floatValue6 := floatValue4 + floatValue5 // 浮点数的操作同样严格规范类型,float32 和 float64不能够直接进行计算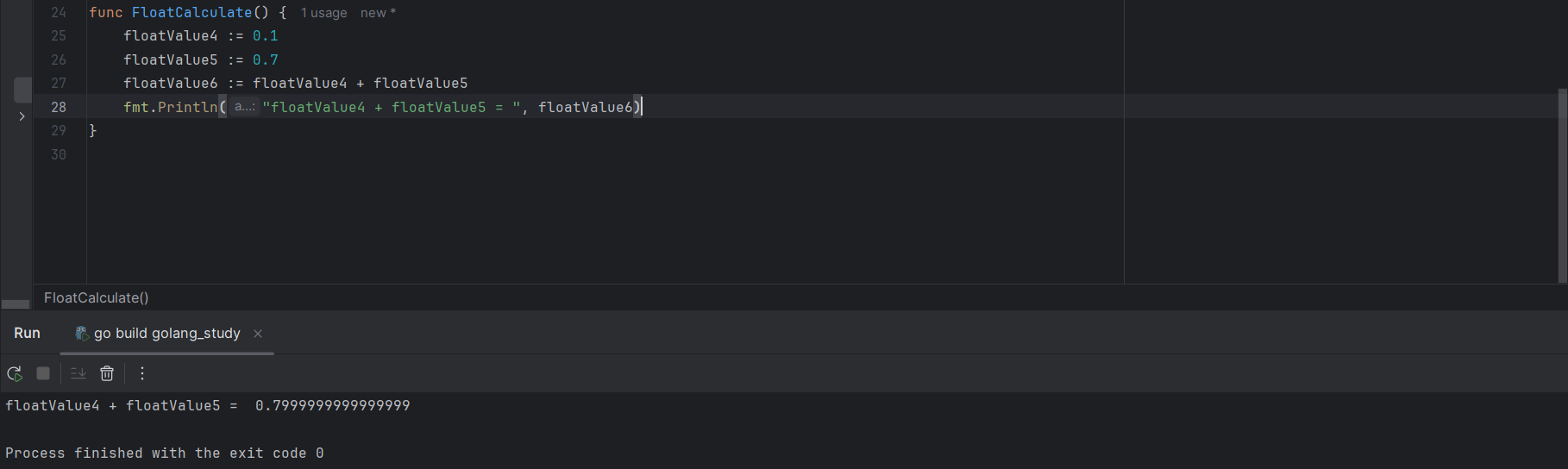
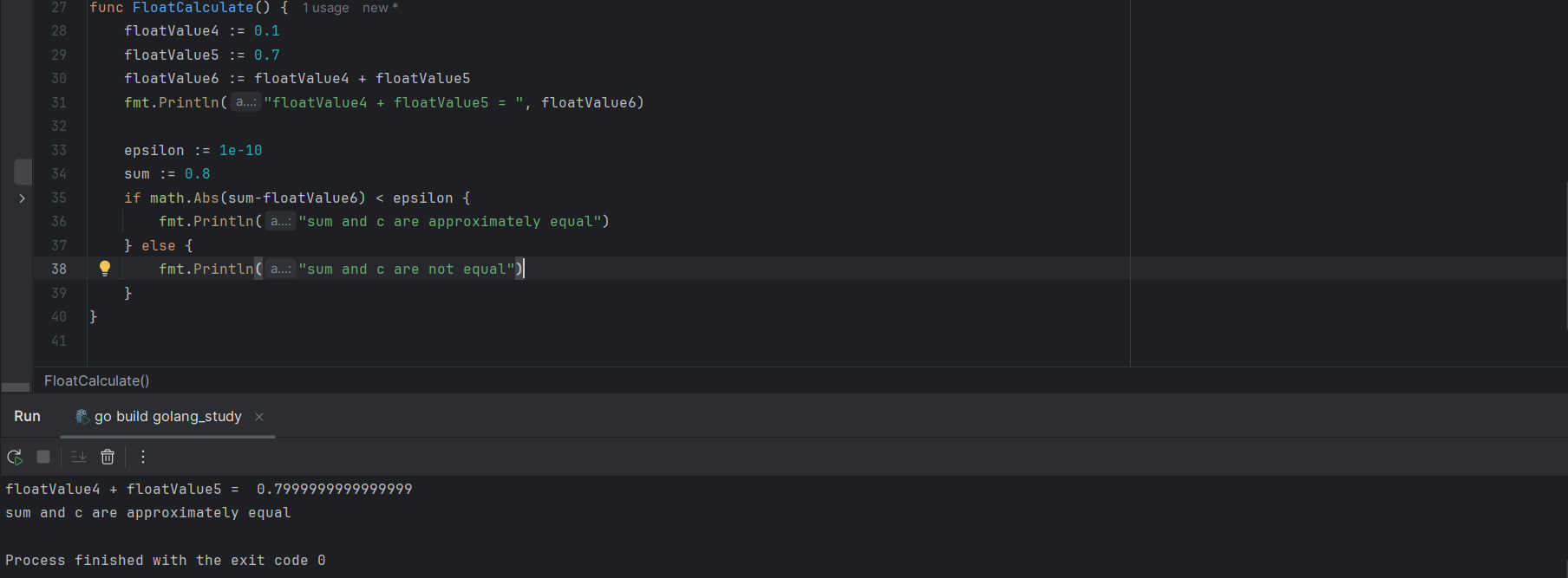
0.1 + 0.7 输出结果并不是我们所想的0.8,这是因为计算机底层将十进制的 0.1 和 0.7 转化为二进制表示时,会丢失精度,因此在实践中,通常会建议避免直接比较浮点数是否相等,而是使用一个小的容忍度(epsilon)来检查它们是否足够接近。
floatValue4 := 0.1
floatValue5 := 0.7
floatValue6 := floatValue4 + floatValue5
epsilon := 1e-10
sum := 0.8
if math.Abs(sum-floatValue6) < epsilon {
fmt.Println("sum and c are approximately equal")
} else {
fmt.Println("sum and c are not equal")
}
4.2.3.1.3 浮点数的比较
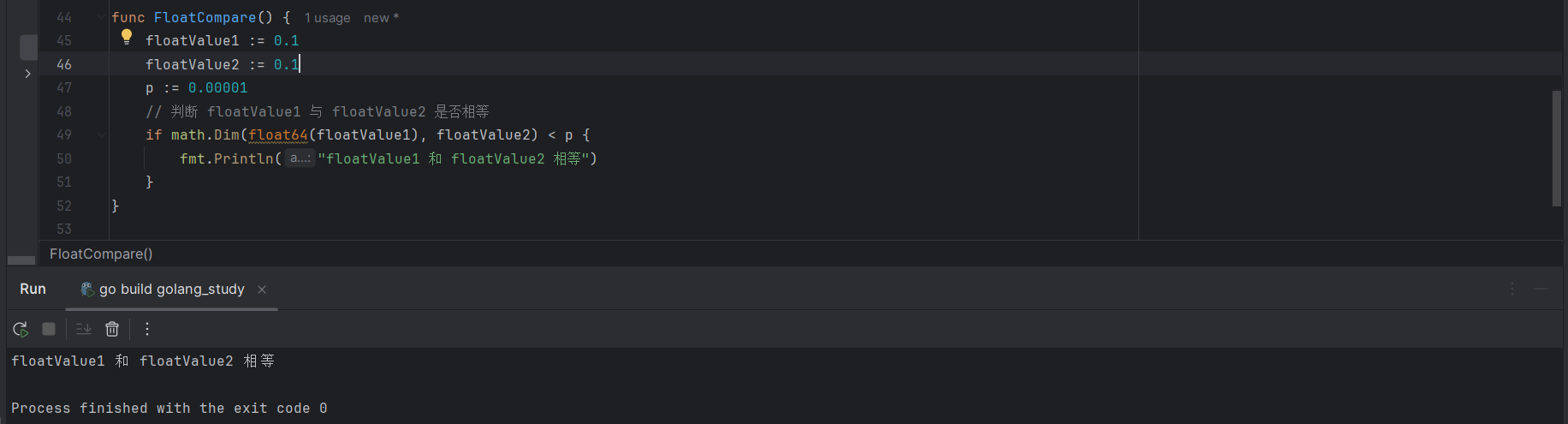
浮点数支持通过算术运算符进行四则运算,也支持通过比较运算符进行比较(前提是运算符两边的操作数类型一致),但是涉及到相等的比较除外,因为我们上面提到,看起来相等的两个十进制浮点数,在底层转化为二进制时会丢失精度,因此不能被表象蒙蔽。
如果一定要判断浮点数的相等,除去上面提到的精度,也可以使用 math.Dim() 方法:
floatValue1 := 0.1
floatValue2 := 0.1
p := 0.00001
// 判断 floatValue1 与 floatValue2 是否相等
if math.Dim(float64(floatValue1), floatValue2) < p {
fmt.Println("floatValue1 和 floatValue2 相等")
}
因此判断两个浮点数是否相同,在Go语言中是通过判断两者相差的精度值,其他语言中的浮点数判断也是如此。
4.2.3.2 复数类型
除了整型和浮点型之外,Go 语言还支持复数类型,与复数相对,我们可以把整型和浮点型这种日常比较常见的数字称为实数,复数是实数的延伸,可以通过两个实数(在计算机中用浮点数表示)构成,一个表示实部(real),一个表示虚部(imag),常见的表达形式如下:
z = a + bi其中 a、b 均为实数,i 称为虚数单位,当 b = 0 时,z 就是常见的实数,当 a = 0 而 b ≠ 0 时,将 z 称之为纯虚数。
在 Go 语言中,复数支持两种类型:complex64(32 位实部和虚部) 和 complex128(64 位实部与虚部),对应的示例如下,和数学概念中的复数表示形式一致:
var complexValue1 complex64
complexValue1 = 1.10 + 10i // 由两个 float32 实数构成的复数类型
complexValue2 := 1.10 + 10i // 和浮点型一样,默认自动推导的实数类型是 float64,所以 complexValue2 是 complex128 类型
complexValue3 := complex(1.10, 10) // 与 complexValue2 等价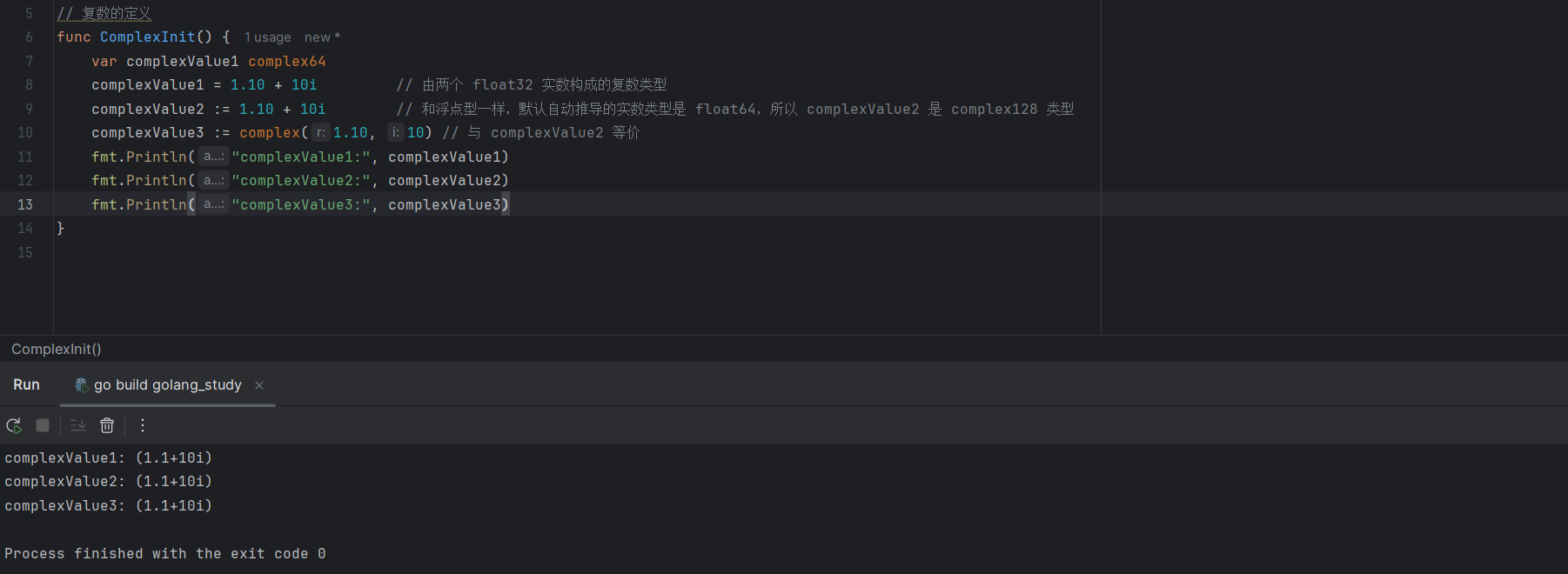
对于一个复数 z = complex(x, y),就可以通过 Go 语言内置函数 real(z) 获得该复数的实部,也就是 x,通过 imag(z) 获得该复数的虚部,也就是 y。
real := real(complexValue1) // 获取复数的实部
imag := imag(complexValue1) // 获取复数的虚部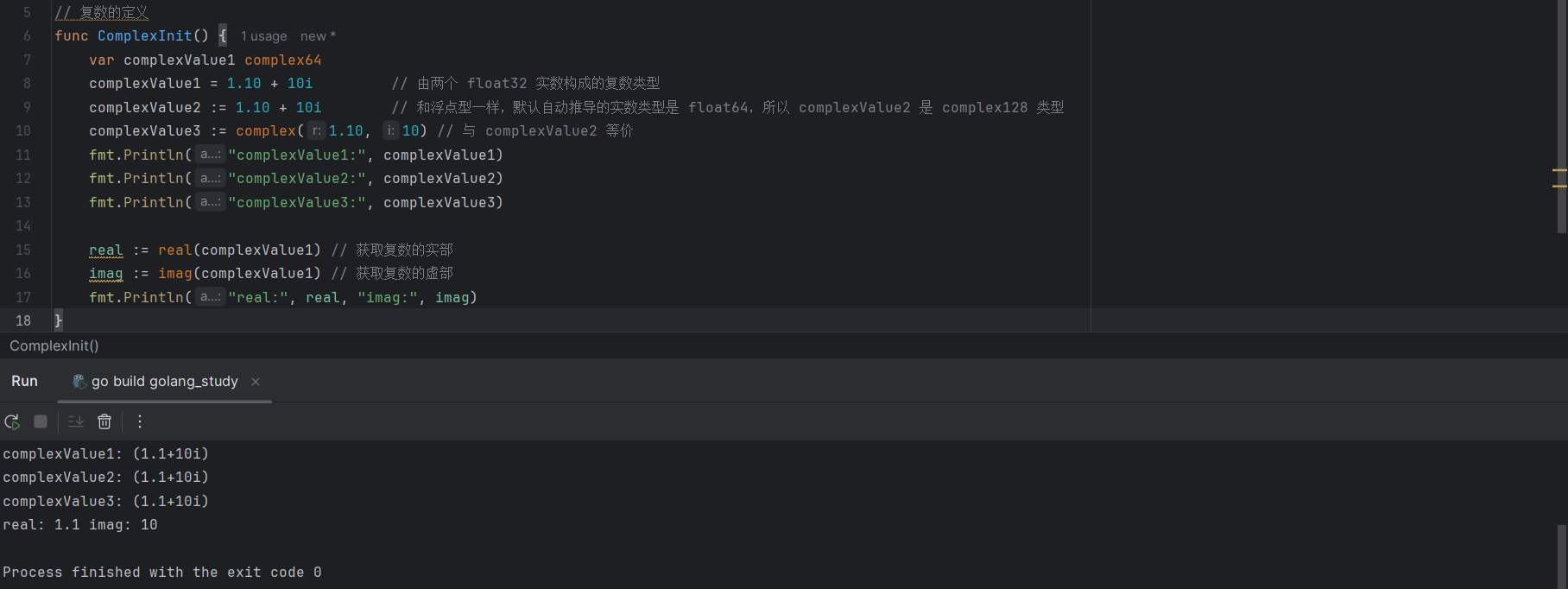
复数支持和其它数字类型一样的算术运算符。当你使用 == 或者 != 对复数进行比较运算时,由于构成复数的实数部分也是浮点型,需要注意对精度的把握。
更多关于复数的函数,请查阅 math/cmplx 标准库的文档。如果你对内存的要求不是特别高,最好使用 complex128 作为计算类型,因为相关函数大都使用这个类型的参数。
4.2.4 字符串及底层字符类型
4.2.4.1 字符串
在 Go 语言中,字符串是一种基本类型,默认是通过 UTF-8 编码的字符序列,当字符为 ASCII 码时则占用 1 个字节,其它字符根据需要占用 2-4 个字节,比如中文编码通常需要 3 个字节。
4.2.4.1.1 声明和初始化:
var str string // 声明字符串变量
str = "Hello World" // 变量初始化
str2 := "Hello World" // 也可以同时进行声明和初始化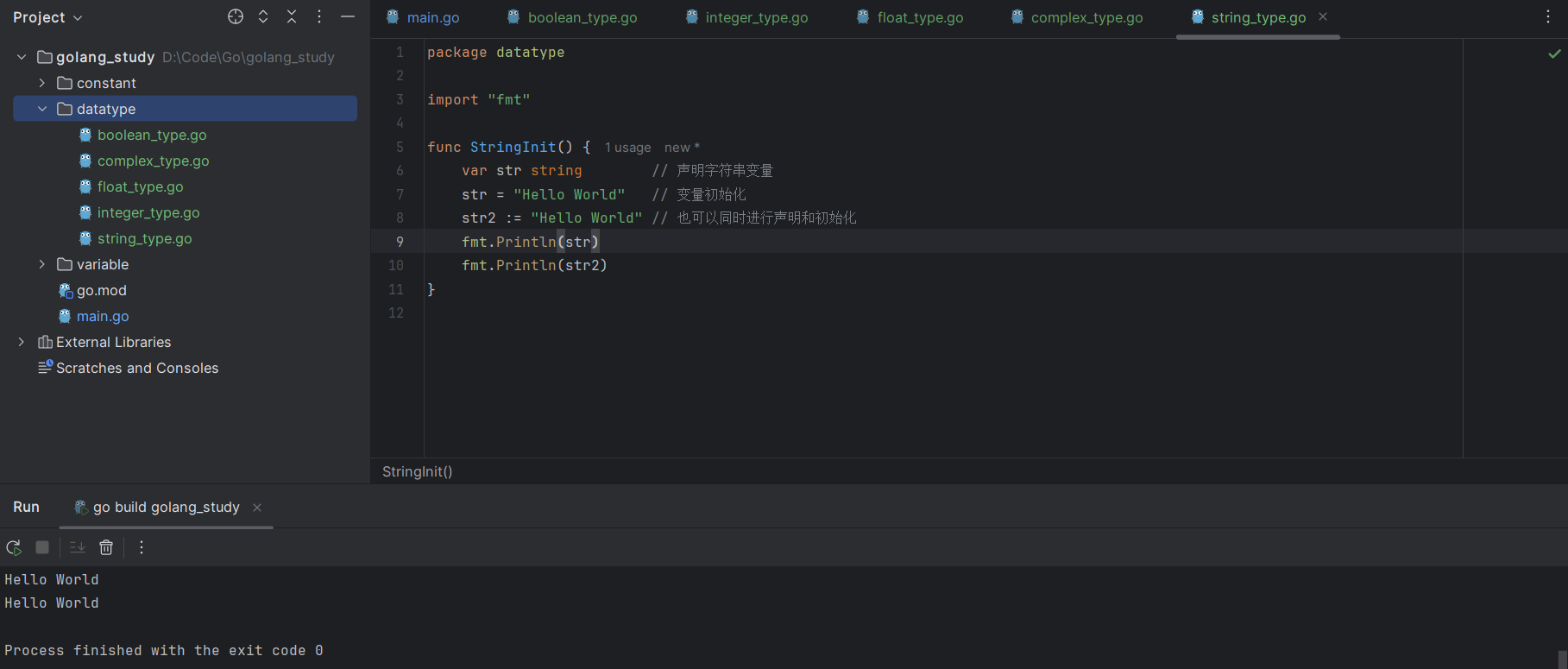
也能够对这些字符串进行格式化输出:
fmt.Printf("The length of \"%s\" is %d \n", str, len(str))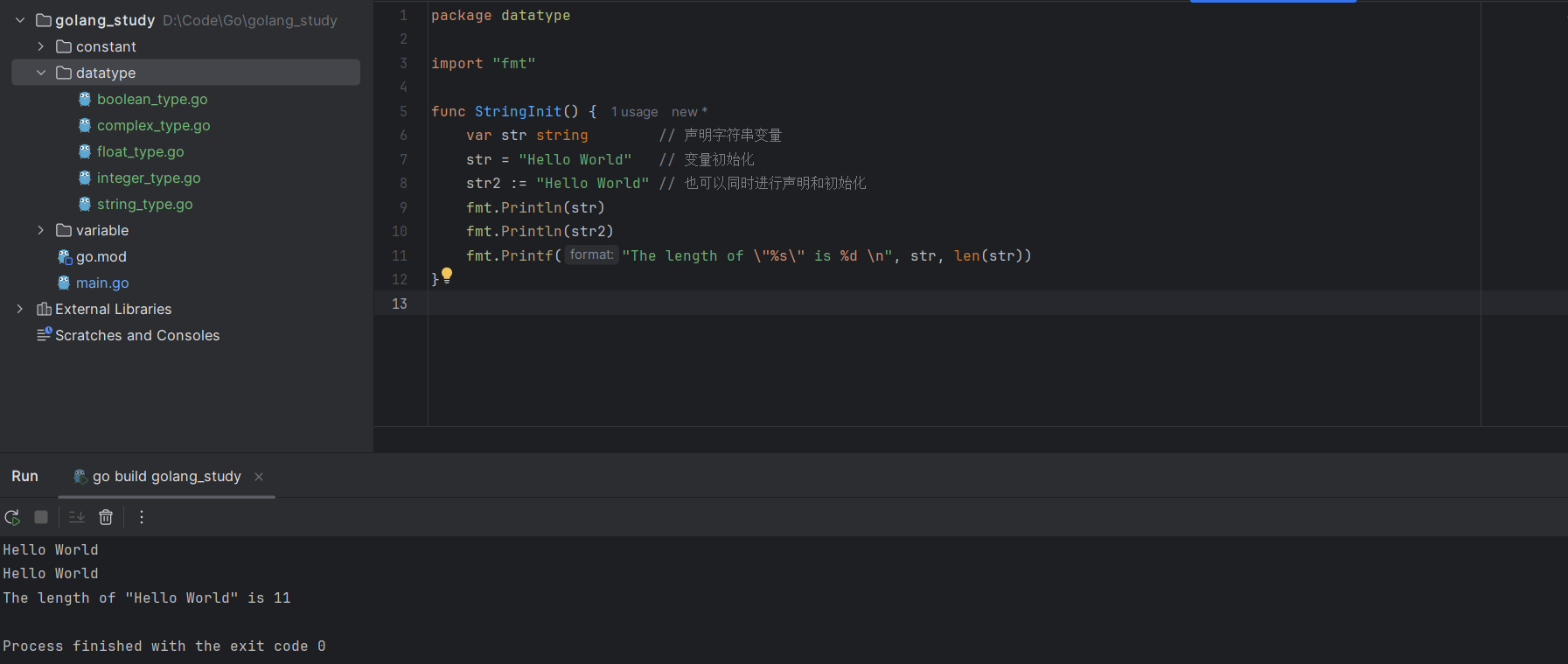
如下表格是格式化所使用的一些参数
| 动词 | 功能 |
|---|---|
| %v | 按值的本来值输出 |
| %+v | 在 % v 基础上,对结构体字段名和值进行展开 |
| %#v | 输出 Go 语言语法格式的值 |
| %T | 输出 Go 语言语法格式的类型和值 |
| %% | 输出 % 本体 |
| %b | 整型以二进制方式显示 |
| %o | 整型以八进制方式显示 |
| %d | 整型以十进制方式显示 |
| %x | 整型以十六进制方式显示 |
| %X | 整型以十六进制、字母大写方式显示 |
| %U | Unicode 字符 |
| %f | 浮点数 |
| %p | 指针,十六进制方式显示 |
虽然可以通过下标访问字符串中的字符,但是和数组不同,在Go语言中,字符串一旦初始化之后,不允许被修改。
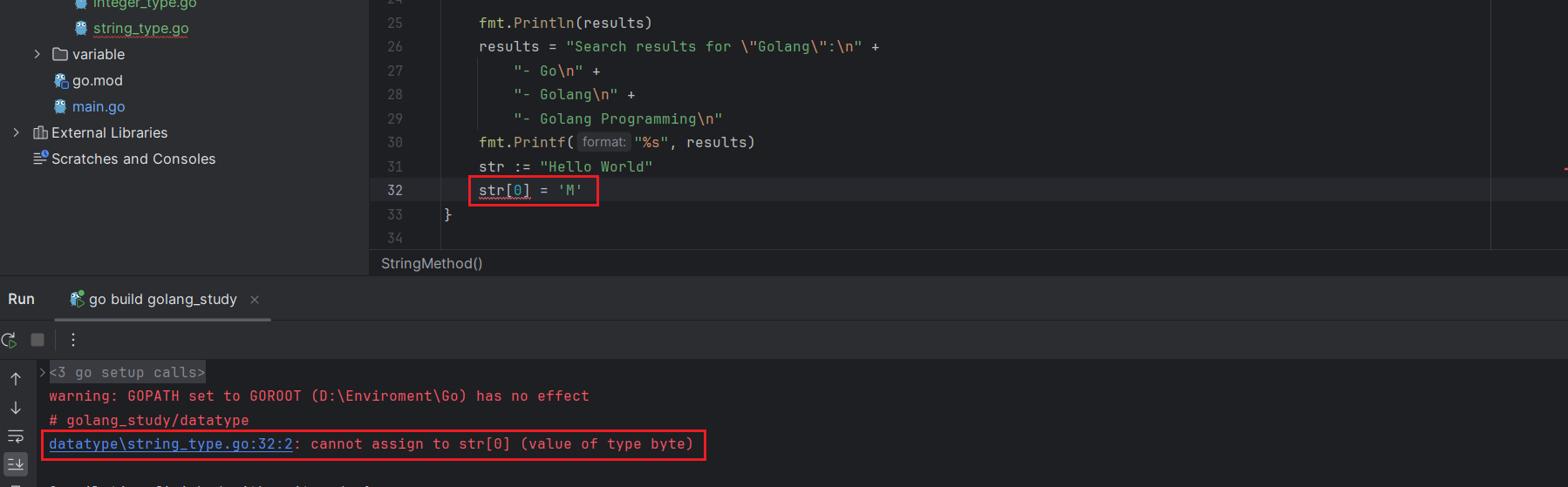
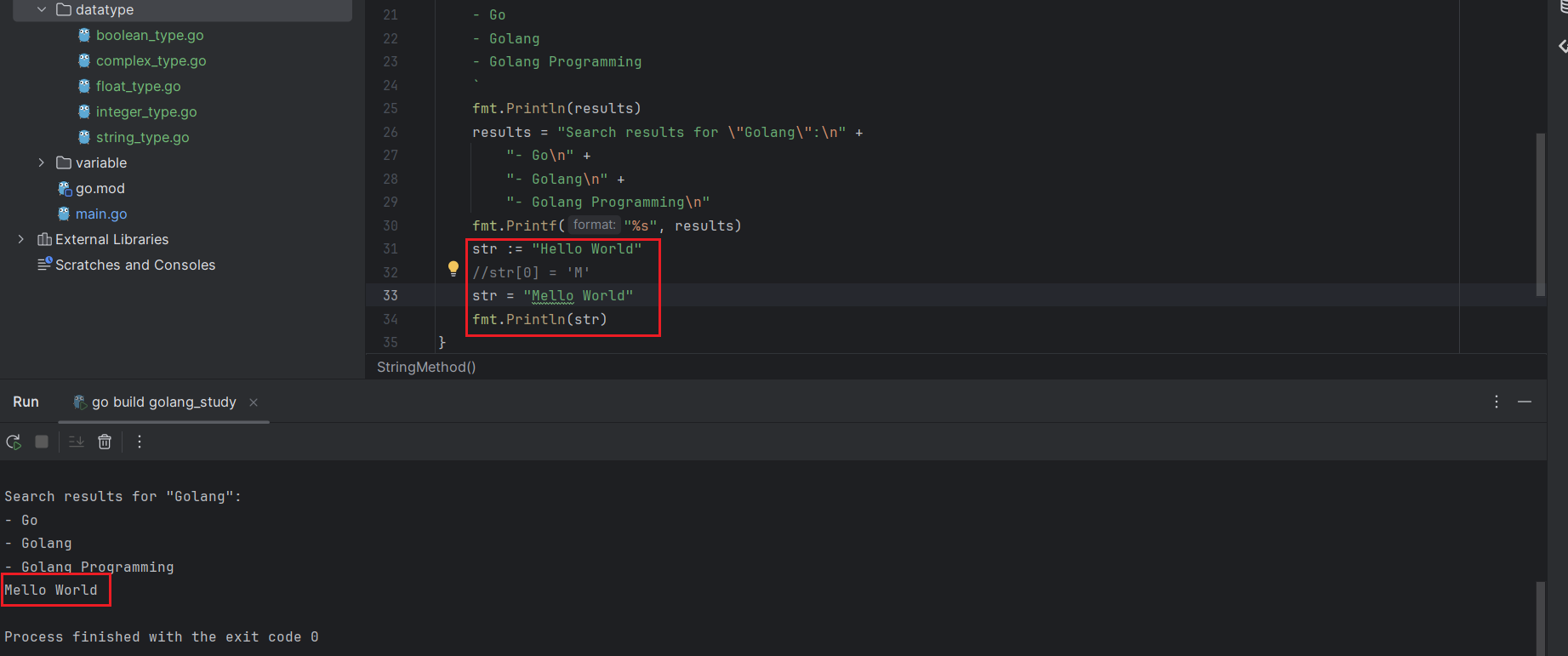
注意,这里只是字符串中的字符不能被修改,你可以整体修改字符串。
4.2.4.1.2 转义字符
Go 语言的字符串不支持单引号,只能通过双引号定义字符串字面值,如果要对特定字符进行转义,可以通过 \ 实现,就像我们上面在字符串中转义双引号和换行符那样,常见的需要转义的字符如下所示:
\n:换行符\r:回车符\t:tab 键\u或 \U :Unicode 字符\\:反斜杠自身
此外,也可以通过如下方法在字符串中包含引号。
label := `'Search' results for "Golang":`
多行字符串,也可以通过``构建。
results := `Search results for "Golang":
- Go
- Golang
- Golang Programming
`
fmt.Println(results)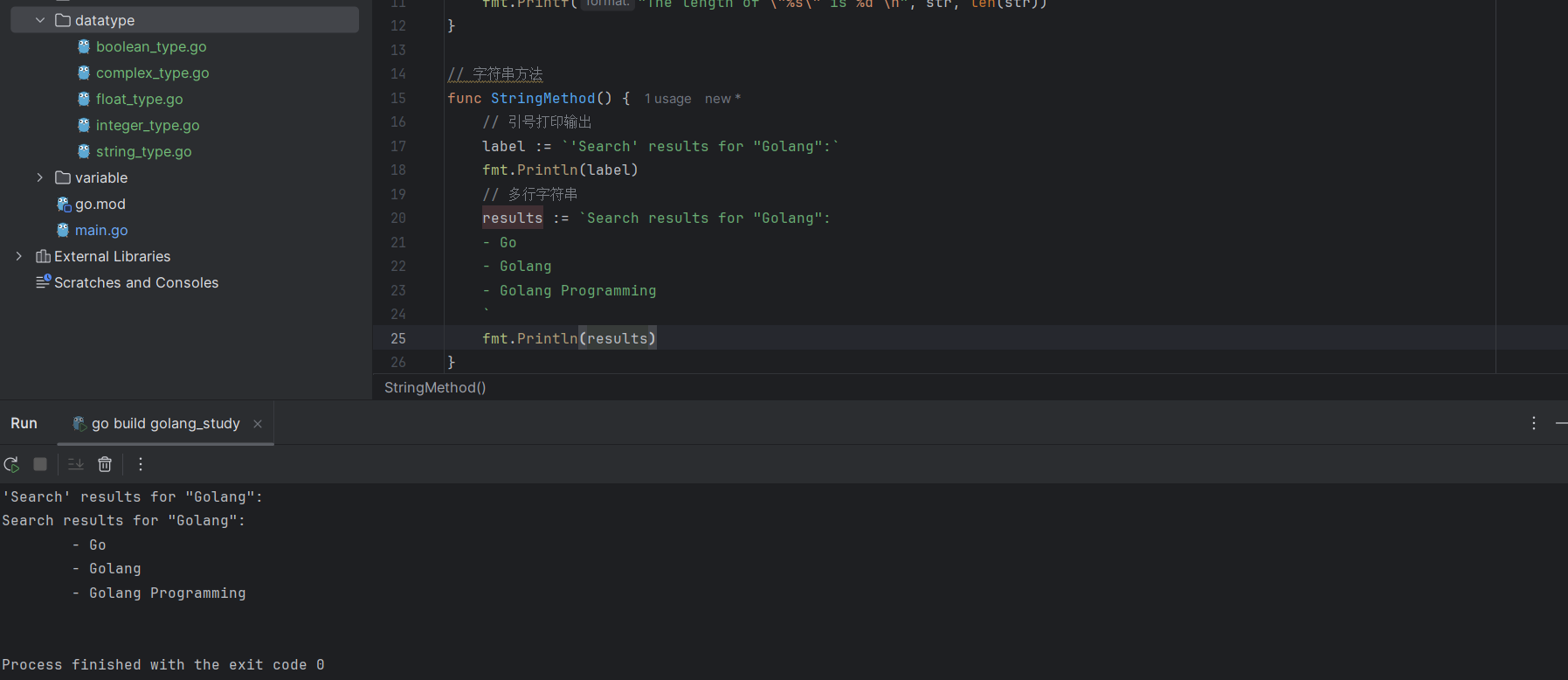
也可以使用 + 进行字符串的拼接
results = "Search results for \"Golang\":\n" +
"- Go\n" +
"- Golang\n" +
"- Golang Programming\n"
fmt.Printf("%s", results)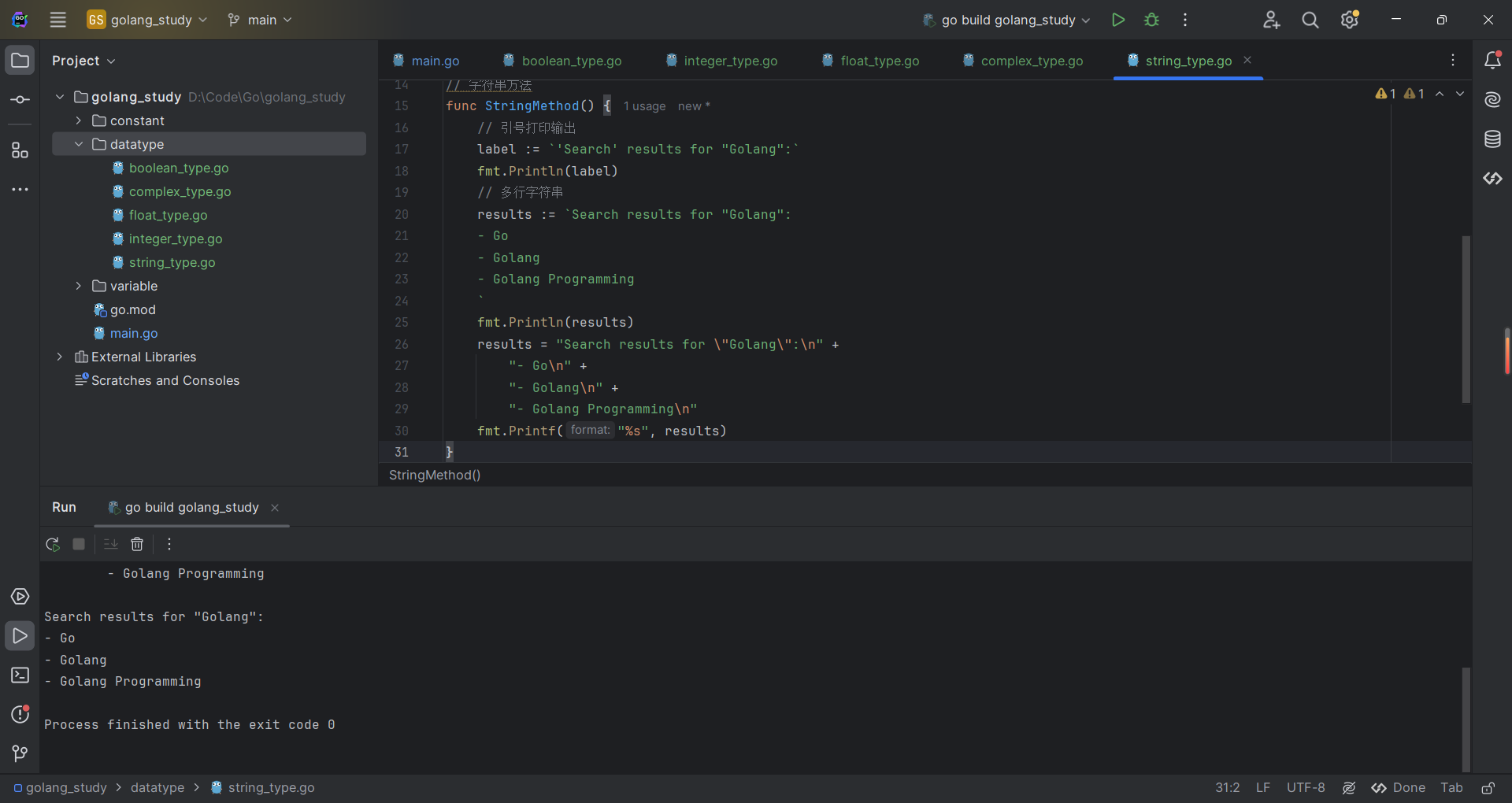
4.2.4.1.3 字符串操作
字符串连接
Go 内置提供了丰富的字符串函数,常见的操作包含连接、获取长度和指定字符,获取长度和指定字符前面已经介绍过,字符串连接只需要通过 + 连接符即可:
str := "Hello"
str = str + ", World"
str += ", World" // 上述语句也可以简写为这样,效果完全一样此外,字符串可能过长,会出现换行的情况,+务必保证出现在上一行。
str = str +
", World"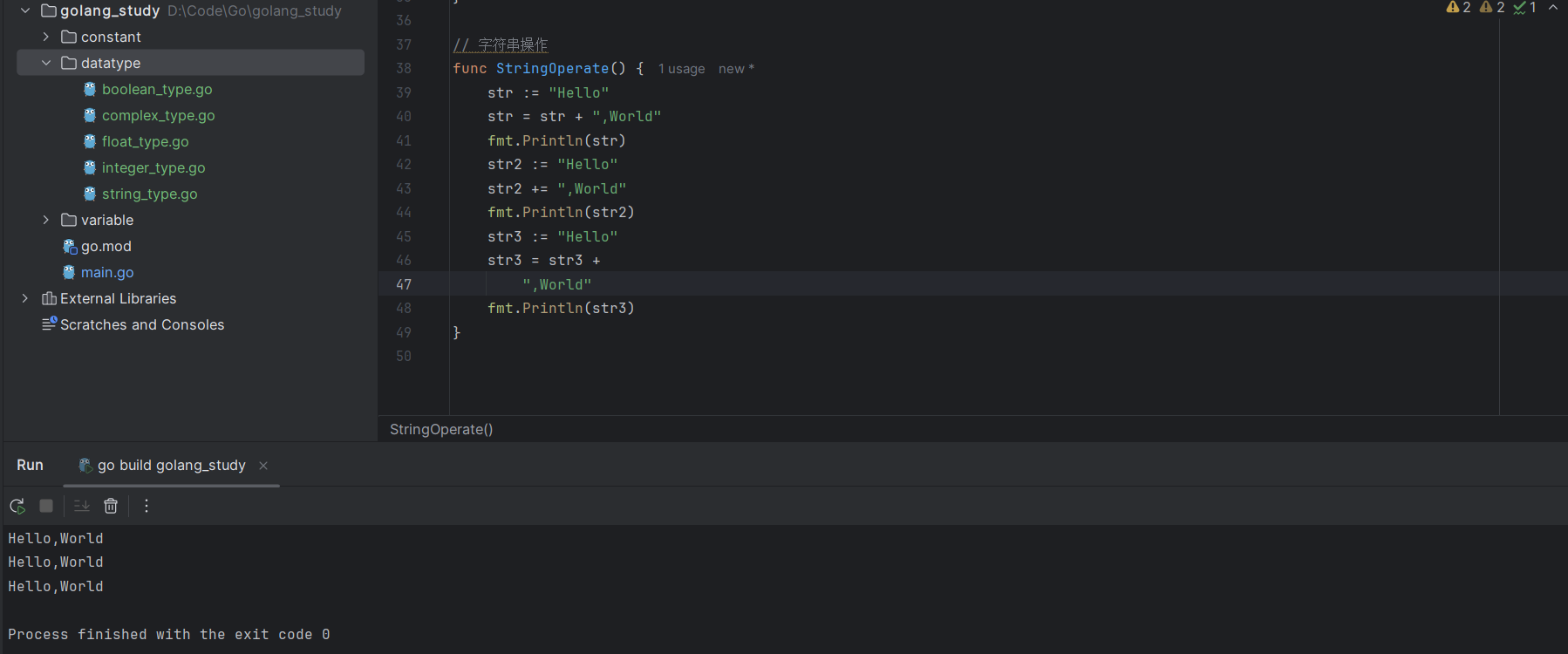
字符串切片
在 Go 语言中,可以通过字符串切片实现获取子串的功能。
str := "hello, world"
str1 := str[:5] // 获取索引5(不含)之前的子串
str2 := str[7:] // 获取索引7(含)之后的子串
str3 := str[0:5] // 获取从索引0(含)到索引5(不含)之间的子串
fmt.Println("str1:", str1)
fmt.Println("str2:", str2)
fmt.Println("str3:", str3)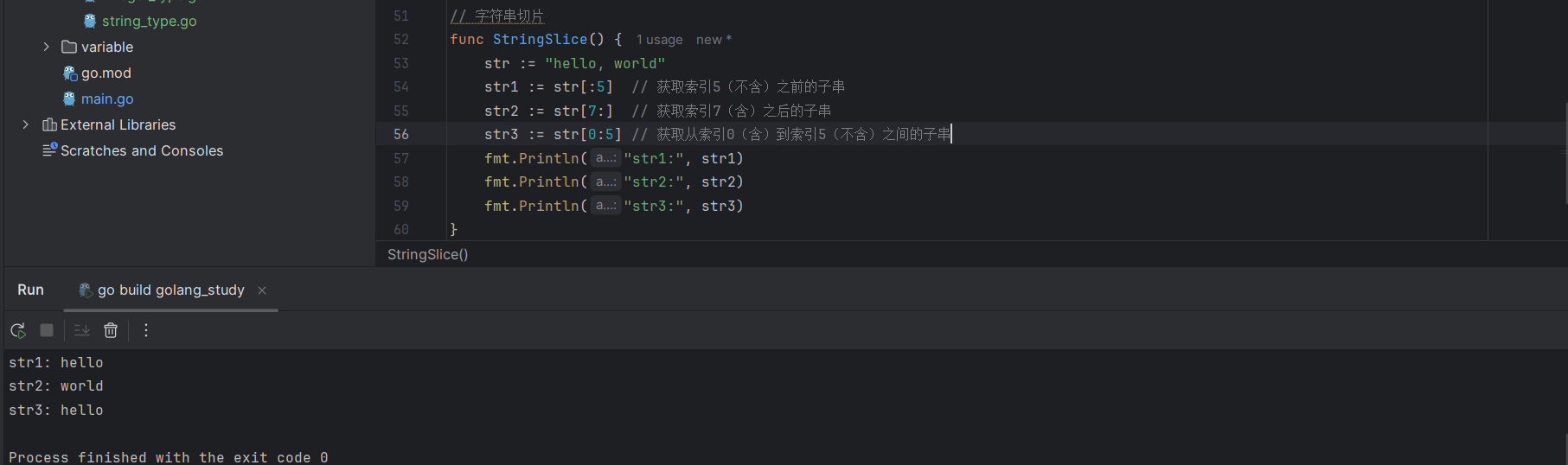
字符串遍历
Go 语言支持两种方式遍历字符串。
// 方式一:字节数组遍历
str := "Hello, 世界"
n := len(str)
for i := 0; i < n; i++ {
ch := str[i] // 依据下标取字符串中的字符,ch 类型为 byte
fmt.Println(i, ch)
}
// 方式二:unicode字符遍历
str := "Hello, 世界"
for i, ch := range str {
fmt.Println(i, ch) // ch 的类型为 rune
}
可以看出,这个字符串长度为 13,尽管从直观上来说,这个字符串应该只有 9 个字符。这是因为每个中文字符在 UTF-8 中占 3 个字节,而不是 1 个字节。

这个时候,打印的就是 9 个字符了,因为以 Unicode 字符方式遍历时,每个字符的类型是 rune,而不是 byte。
这里的 rune 和 byte 也即Go语言底层字符类型。
byte,代表 UTF-8 编码中单个字节的值(它也是uint8类型的别名,两者是等价的,因为正好占据 1 个字节的内存空间);rune,代表单个 Unicode 字符(它也是int32类型的别名,因为正好占据 4 个字节的内存空间)。
4.2.5 基本数据类型之间的转化
4.2.5.1 整型之间的转化
在进行类型转化时只需要调用要转化的数据类型对应的函数即可:
v1 := uint(16) // 初始化 v1 类型为 unit
v2 := int8(v1) // 将 v1 转化为 int8 类型并赋值给 v2
v3 := uint16(v2) // 将 v2 转化为 uint16 类型并赋值给 v3由高向低转换时,需要注意整数的溢出
v1 := uint(-255) // uint 是无符号整型,在编译时这里会产生溢出
v4 := int16(-255) // 这里也要注意溢出,如这里是int8(-255)就会报错4.2.5.2 整型和浮点数之间的转化
v1 := 99.99
v2 := int(v1) // 浮点数转化为整型,小数点后的数字直接被抛弃
v3 := 99
v4 := float64(v3) // 整型转化为浮点数,直接调取对应的类型即可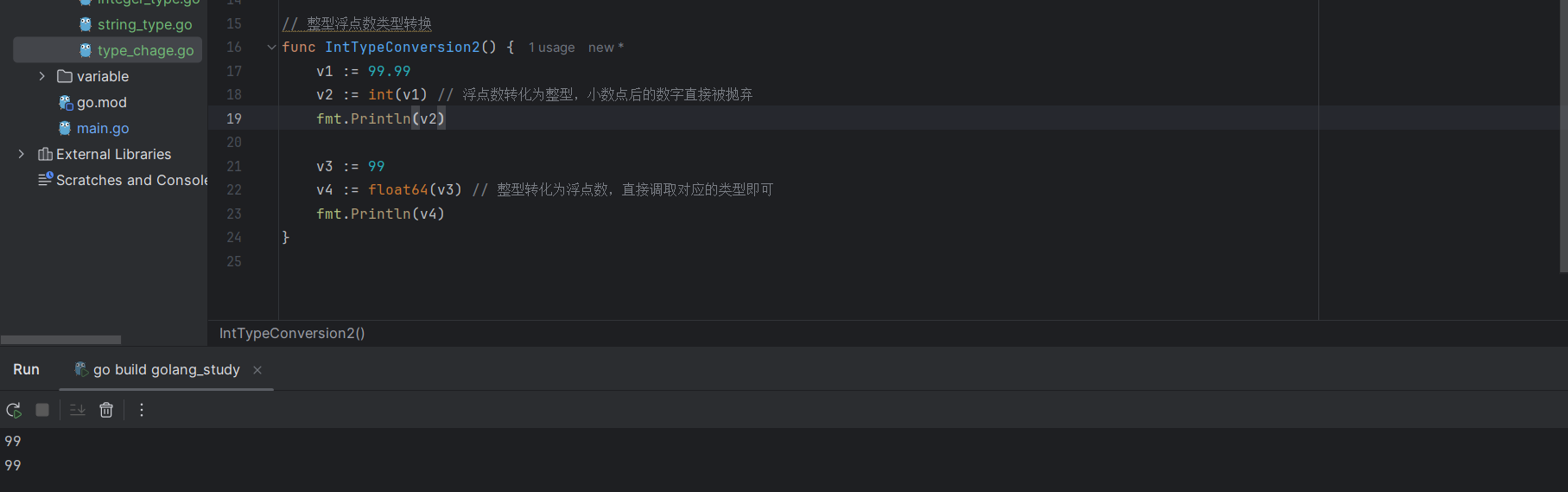
4.2.5.3 数值和浮点数的转换
目前 Go 语言不支持将数值类型转化为布尔型,需要自己根据需求去实现类似的转化。
4.2.5.4 字符串和其他基本类型之间的转化
4.2.5.4.1 整型转化成字符串
整型数据可以通过 Unicode 字符集转化为对应的 UTF-8 编码的字符串:
v1 := 65
v2 := string(v1) // v2 = A
v3 := 30028
v4 := string(v3)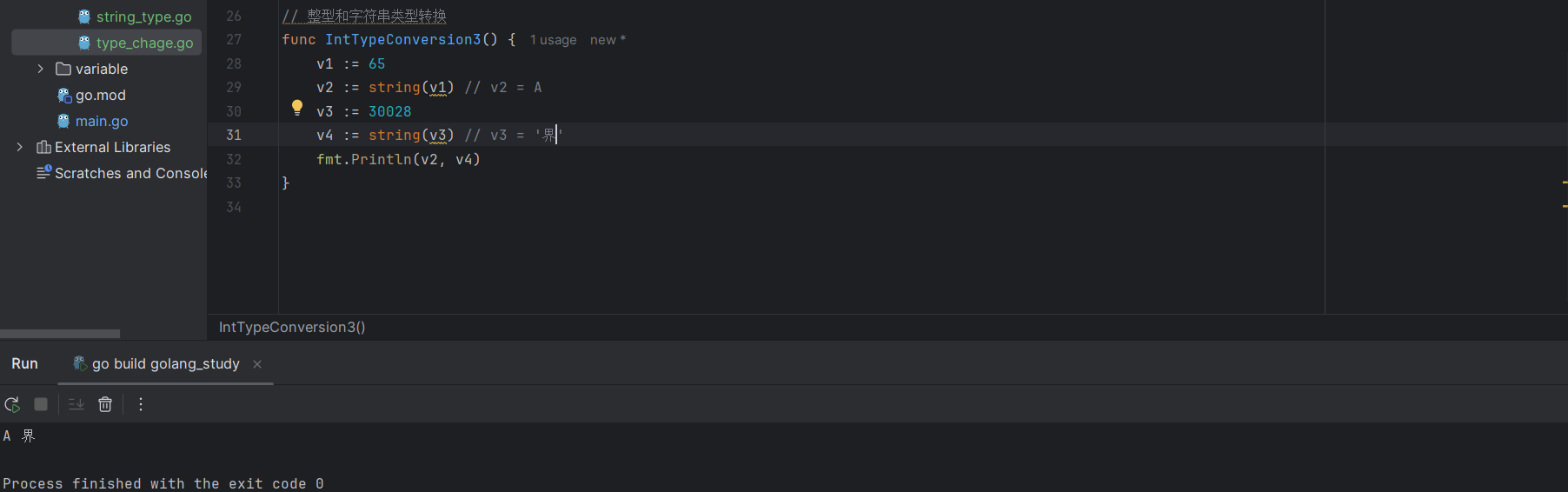
4.2.5.4.2 strconv 包
Go 语言默认不支持将字符串类型强制转化为数值类型,即使字符串中包含数字也不行。
如果要实现更强大的基本数据类型与字符串之间的转化,可以使用 Go 官方 strconv 包提供的函数:
v1 := "100"
v2, _ := strconv.Atoi(v1) // 将字符串转化为整型,v2 = 100
v3 := 100
v4 := strconv.Itoa(v3) // 将整型转化为字符串, v4 = "100"
v5 := "true"
v6, _ := strconv.ParseBool(v5) // 将字符串转化为布尔型
v5 = strconv.FormatBool(v6) // 将布尔值转化为字符串
v7 := "100"
v8, _ := strconv.ParseInt(v7, 10, 64) // 将字符串转化为整型,第二个参数表示进制,第三个参数表示最大位数
v7 = strconv.FormatInt(v8, 10) // 将整型转化为字符串,第二个参数表示进制
v9, _ := strconv.ParseUint(v7, 10, 64) // 将字符串转化为无符号整型,参数含义同 ParseInt
v7 = strconv.FormatUint(v9, 10) // 将无符号整数型转化为字符串,参数含义同 FormatInt
v10 := "99.99"
v11, _ := strconv.ParseFloat(v10, 64) // 将字符串转化为浮点型,第二个参数表示精度
v10 = strconv.FormatFloat(v11, 'E', -1, 64)
q := strconv.Quote("Hello, 世界") // 为字符串加引号
q = strconv.QuoteToASCII("Hello, 世界") // 将字符串转化为 ASCII 编码4.2.6 数组
4.2.6.1 数组的初始化和定义
在 Go 语言中,数组是固定长度的、同一类型的数据集合。数组中包含的每个数据项被称为数组元素,一个数组包含的元素个数被称为数组的长度。
在 Go 语言中,你可以通过 [] 来标识数组类型,但需要指定长度和元素类型。以下是一些常见的数组声明方法:
var a [8]byte // 长度为8的数组,每个元素为一个字节
var b [3][3]int // 二维数组(9宫格)
var c [3][3][3]float64 // 三维数组(立体的9宫格)
var d = [3]int{1, 2, 3} // 声明时初始化
var e = new([3]string) // 通过 new 初始化
数组也可以通过 := 进行一次性声明和初始化,所有数组元素通过 {} 包裹:
array := [5]int{1,2,3,4,5}还可以通过语法糖声明省略数组长度:
array2 := [...]int{1, 2, 3} // 编译时,Go语言会自动计算该数组的长度数组在初始化的时候,如果没有填满,则空位会通过对应元素的零值填满:
array3 := [5]int{1,2,3}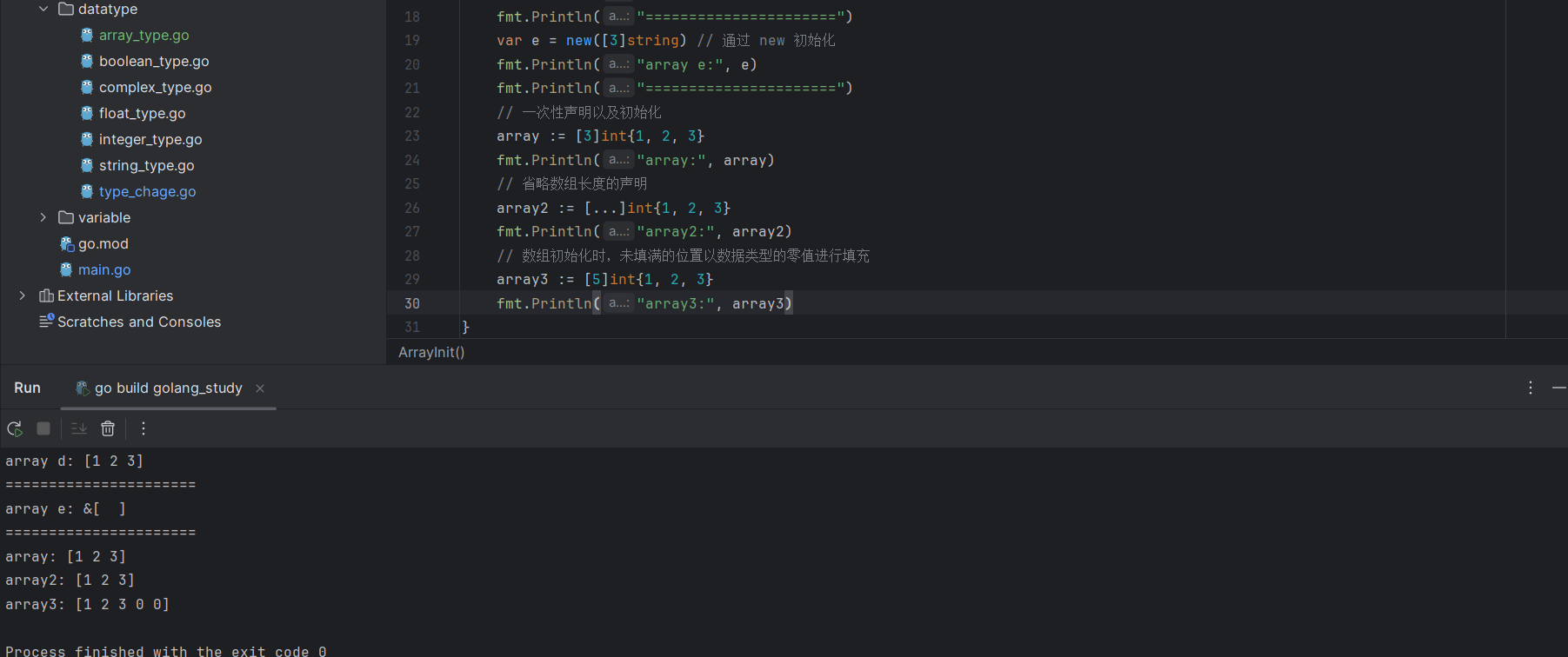
Go语言中,数组初始化时,可以指定下标位置的元素值,未指定的位置,数据元素类型的零值填充:
a := [5]int{1:3, 3:5}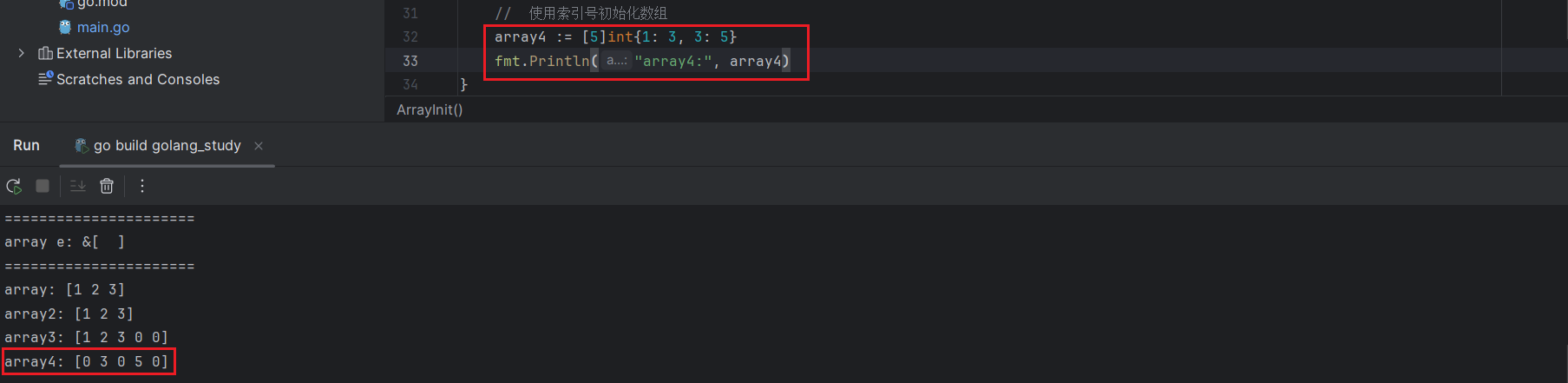
4.2.6.2 数组元素的访问和设置
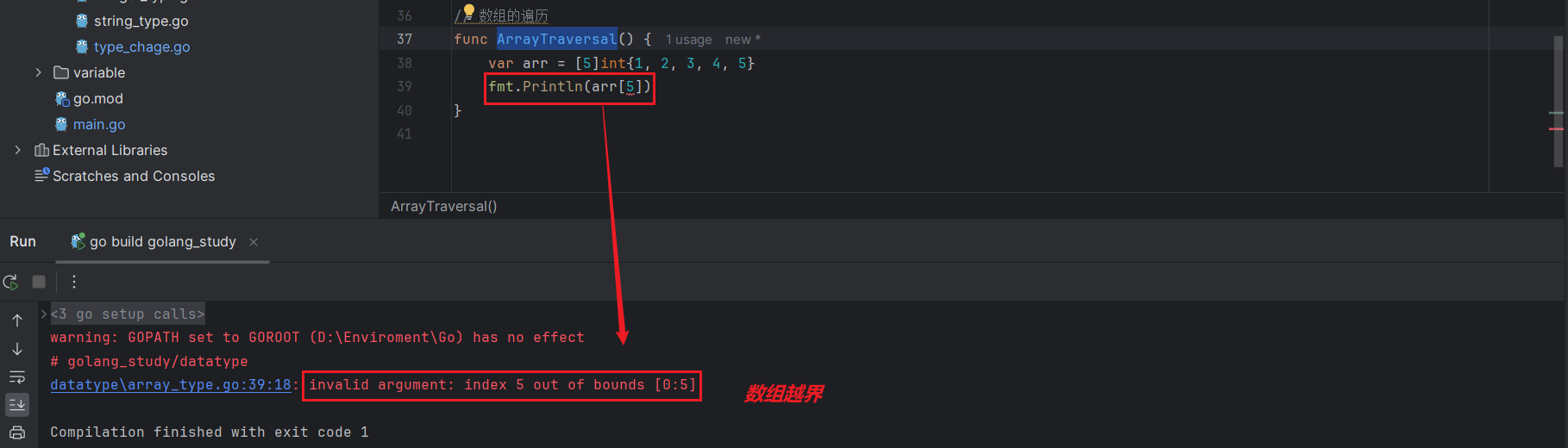
可以使用数组下标来访问 Go 数组中的元素,数组下标默认从 0 开始,len(arr)-1 表示最后一个元素的下标:
arr := [5]int{1,2,3,4,5}
a1, a2 := arr[0], arr[len(arr) - 1]如上数组arr,a1 的值是1,a2是数组的最后一个元素5。
访问数组元素时,下标必须在有效范围内,比如对于一个长度为5的数组,下标有效范围时 [0,4],超出这个范围编译时会报索引越界异常:
和字符串这种不可变值类型不一样,数组除了支持下标访问对应索引的元素值以外,还能够通过下标设置对应索引位置的元素值:
arr[0] = 100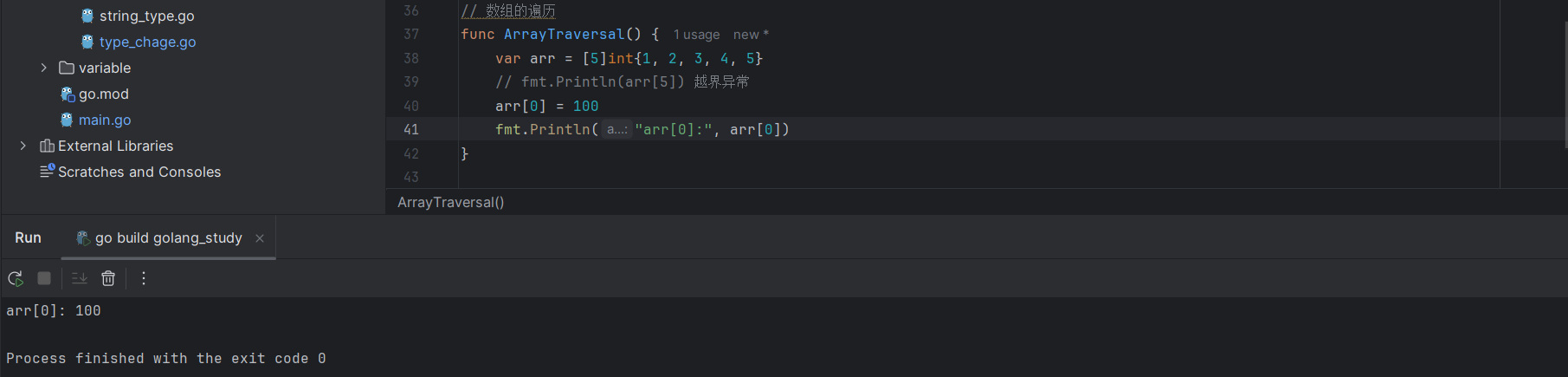
4.2.6.3 数组元素的遍历
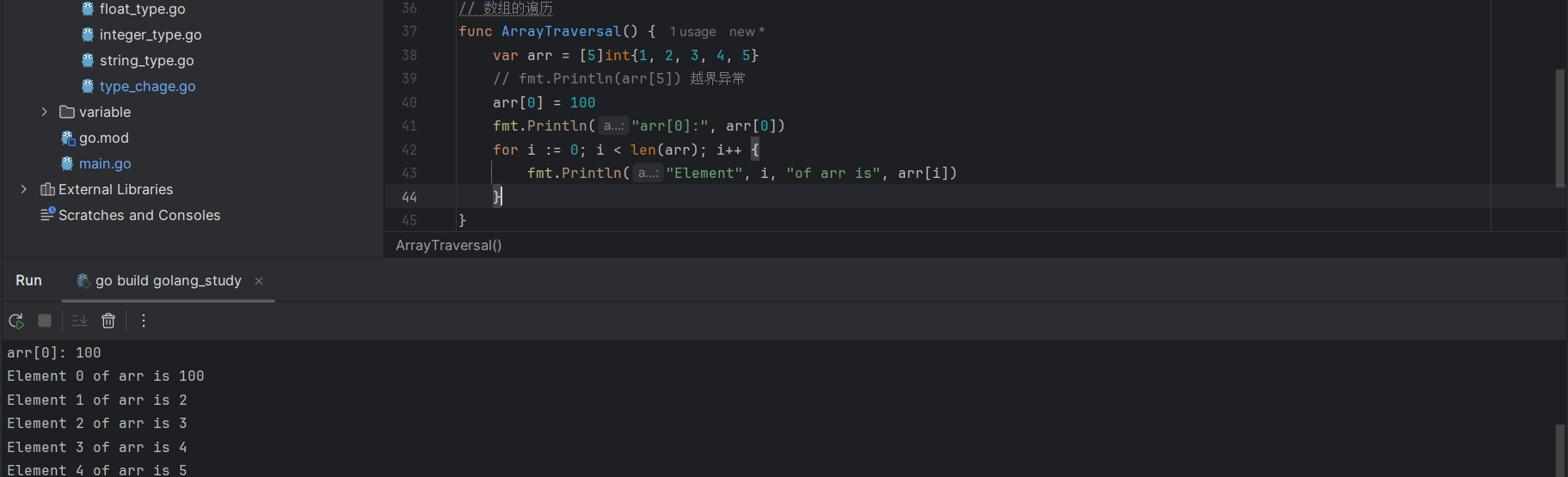
可以通过for循环遍历数组中所有的元素:
for i := 0; i < len(arr); i++ {
fmt.Println("Element", i, "of arr is", arr[i])
}
Go 语言还提供了一个关键字 range,也能够用于遍历数组中的元素:
for i, v := range arr {
fmt.Println("Element", i, "of arr is", v)
}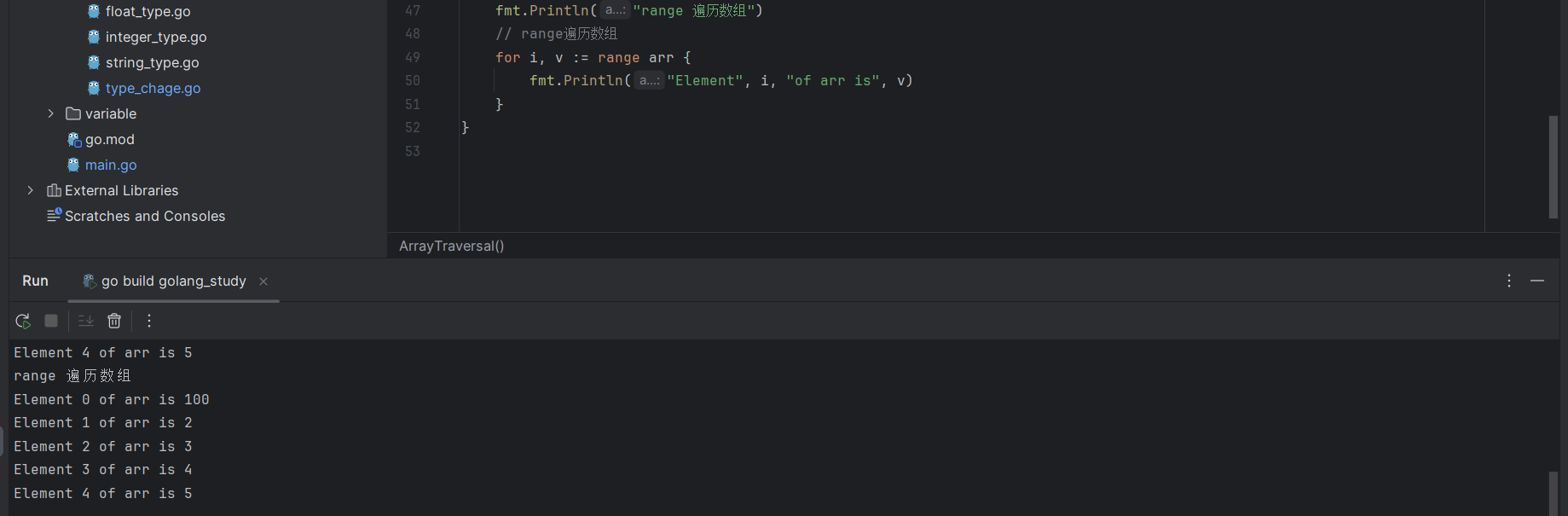
range 表达式返回两个值,第一个是数组下标索引值,第二个是索引对应数组元素值,如果只想获取元素值或者只想获取索引值可以借助匿名变量:
// 只获取索引值
for i, _ := range arr {
fmt.Println("index is ", i)
}
// 只获取元素值
for _, v := range arr {
fmt.Println("value is ", v)
}
4.2.6.4 多维数组
多维数组的操作与一维数组一样,只不过每个元素可能是个数组,在进行循环遍历的时候需要多层嵌套循环,下面是一个多维数组声明、初始化以及使用:
// 声明二维数组
var multi [9][9]string
// 二维数组元素赋值
for i := 0; i < 9; i++ {
for j := 0; j < 9; j++ {
m := i + 1
n := j + 1
if n > m {
// 九九乘法表
// 1*1 = 1
// 1*2 = 2 2*2 = 4
// 1*3 = 3 2*3 = 6 3*3 = 9
// 当n>m,跳出循环
continue
}
multi[i][j] = fmt.Sprintf("%d*%d=%d", n, m, m*n)
}
}
// 二维数组打印
for i := 0; i < 9; i++ {
for j := 0; j < 9; j++ {
if j > i {
continue
}
fmt.Printf(multi[i][j] + " ")
if j == i {
fmt.Println()
}
}
}代码运行,打印的内容如下:

多维数组打印有一个优化的方法,代码如下:
// 打印九九乘法表
for _, v1 := range multi {
for _, v2 := range v1 {
fmt.Printf("%-8s", v2) // 位宽为8,左对齐
}
fmt.Println()
}
4.2.6.5 数组总结
Go语言中的数组类型遍历一旦声明后长度就不能再变,这样就无法动态添加元素到数组中,如果要添加一个元素到数组中,需要将就数组的元素都拷贝过来,最后添加新的元素,如果数组的长度不能确定,我们设置了一个较多元素的数组,这就会影响到程序的性能。
数组是值类型,将数组作为参数传递到函数时,传递的是数组的值拷贝,也即会先将数组拷贝到形参,函数体中引用的是形参而不是原来的数组,当我们在函数中对数组元素进行修改的时候,并不会影响原来数组的值,如果数组很大时,值拷贝也会影响到程序的性能。
因此,Go语言也有一个引用类型的、支持动态添加元素的新“数组”类型,也即切片类型。在Go语言中,实际很少使用数组,大多时间会使用切片取代数组。
4.2.7 切片
4.2.7.1 切片的定义
Go语言中,切片是一个新的数据类型数据类型,与数组最大的区别在于,切片的类型中只有数据元素的类型,而没有长度:
var slice []string = []string{"a", "b", "c"}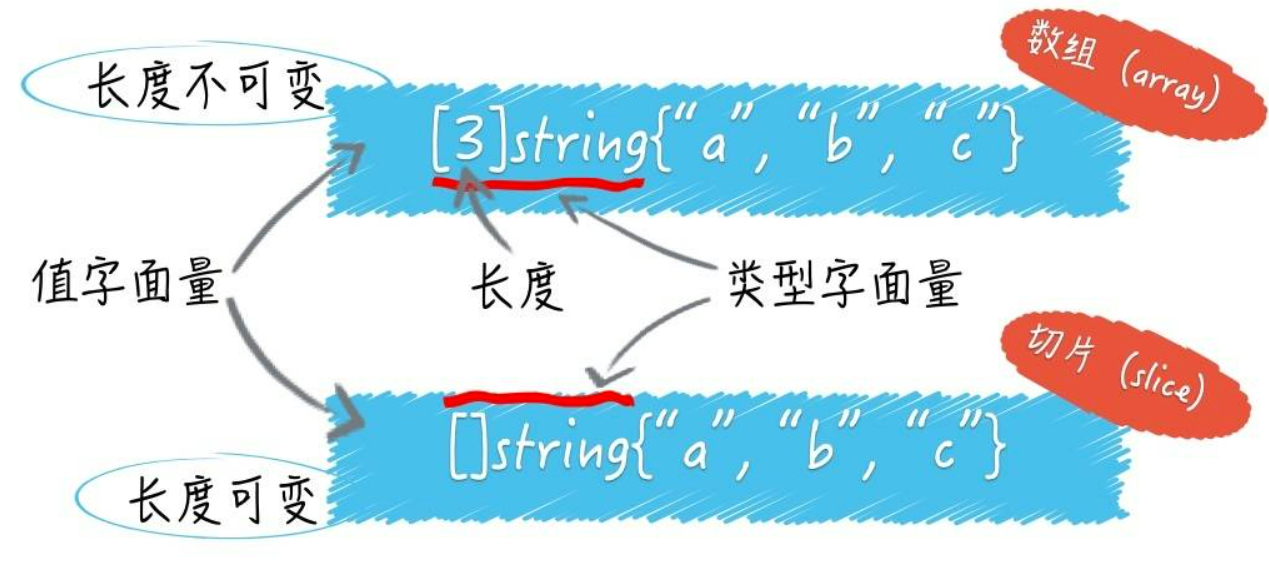
因此,Go语言中的切片是一个可变长度的、同一类型元素集合,切片的长度可以随着元素数量的增长而增长,但不会随着元素数量的减少而减少,但切片底层依然使用数组来管理元素,可以看作是对数组做了一层简单的封装。
创建切片的方法共有三种,分别是基于数组、切片和直接创建。
4.2.7.1.1 基于数组创建切片
切片可以基于一个已存在的数组创建,切片可以只使用数组的一部分元素或者全部元素,甚至可以创建一个比数组更大的切片。
// 先定义一个数组
months := [...]string{"January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December"}
// 基于数组创建切片
q2 := months[3:6] // 第二季度
summer := months[5:8] // 夏季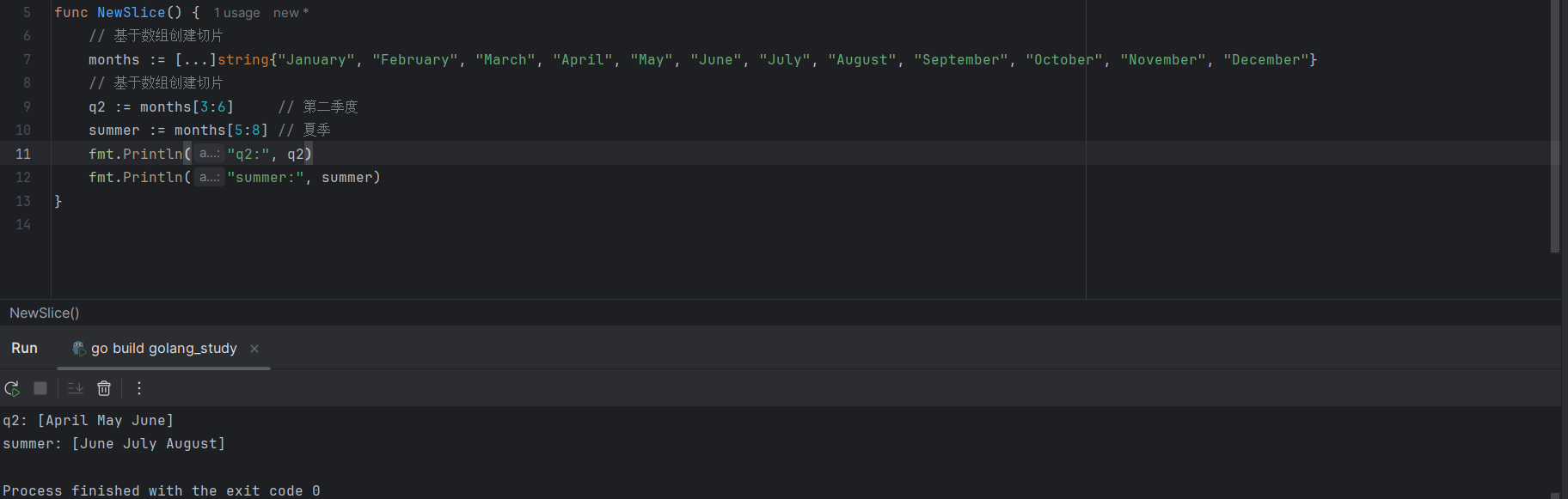
Go语言支持通过 array[start:end]这样的方式基于数组生成一个切片,start表示切片在数组中的下标七点,end表示切片在数组中的下表终点,两者之间的元素就是切片初始化后的元素集合,以下是几种创建切片的示例:
基于months 的所有元素创建切片(全年)
all := months[:]基于 months 的前6个元素创建切片(上半年)
firsthalf := months[:6]基于第6个元素开始的后的后续元素创建切片(下半年)
secondhalf := months[6:]
4.2.7.1.2 基于切片创建切片
类似于切片能够基于一个数组创建,切片也能够基于另一个切片创建:
firsthalf := months[:6]
q1 := firsthalf[:3] // 基于firsthalf的前三个元素构建新切片基于切片创建切片时,选择的元素范围可以超过所包含元素的个数,如下:
// 基于切片创建切片
firsthalf := months[:6]
q1 := firsthalf[:3]
// 可以创建超过切片的元素
q3 := q1[:12]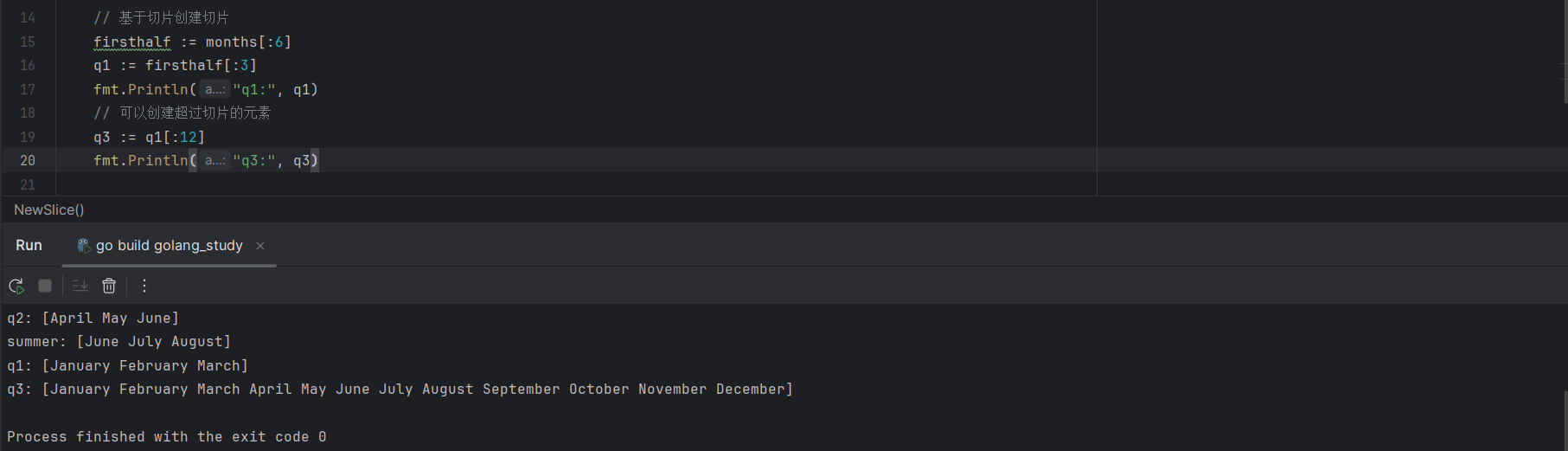
如上图所示,q3长度远超过q1的长度,超出的部分由原数组months中的元素进行补充,那能不能超过这个原数组的长度呢?
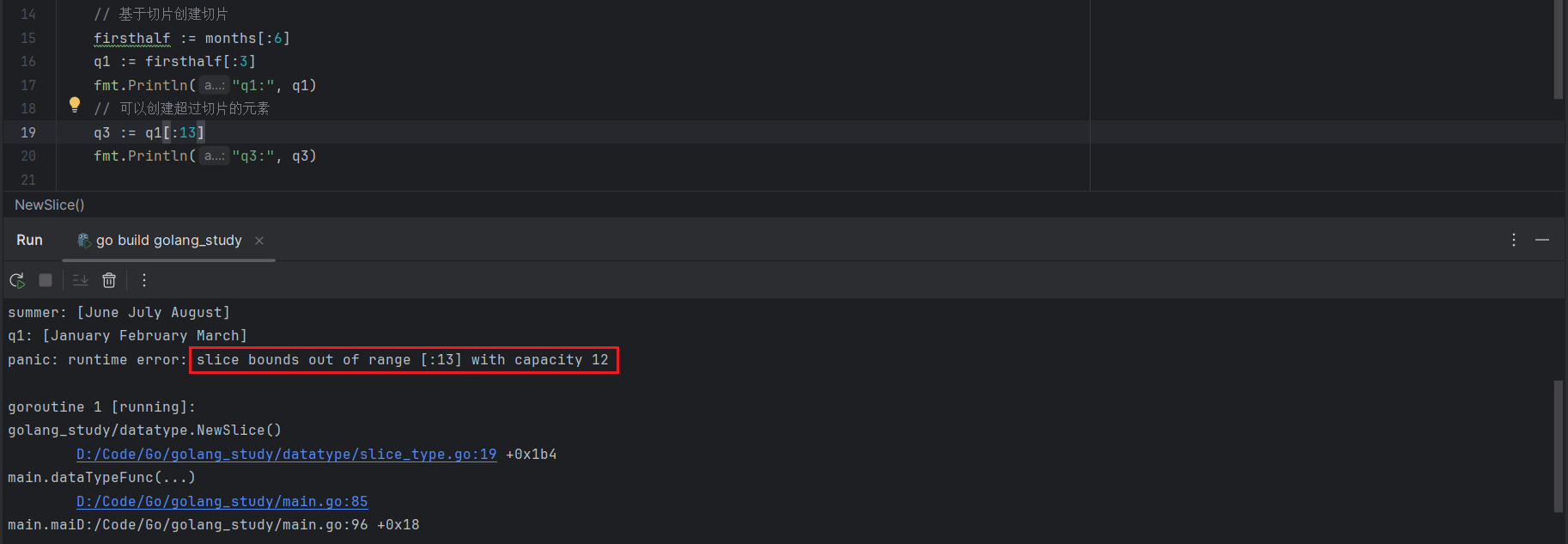
产生了报错,显示切片的长度为13,但是容量是12,因此这里虽然是基于切片创建切片,但其本质依旧是基于数组创建切片。
4.2.7.1.3 直接创建切片
创建切片并不是一定需要一个数组,Go语言的内置函数make()可以灵活地创建切片。
创建一个初始长度位5的整型切片:
mySlice := make([]int, 5)创建一个初始长度为5,容量为10的整型切片:
mySlice2 := make([]int, 5, 10)创建并初始化包含5个元素的数组切片(长度和容量均为5):
// 这个语句容易和数组的初始化语句混淆
// 数组的初始化语句 array := [5]int{1,2,3,4,5}
// 这两个的区别在于切片初始化不需要指定切片长度,而数组需要指定数组长度
mySlice3 := []int{1, 2, 3, 4, 5}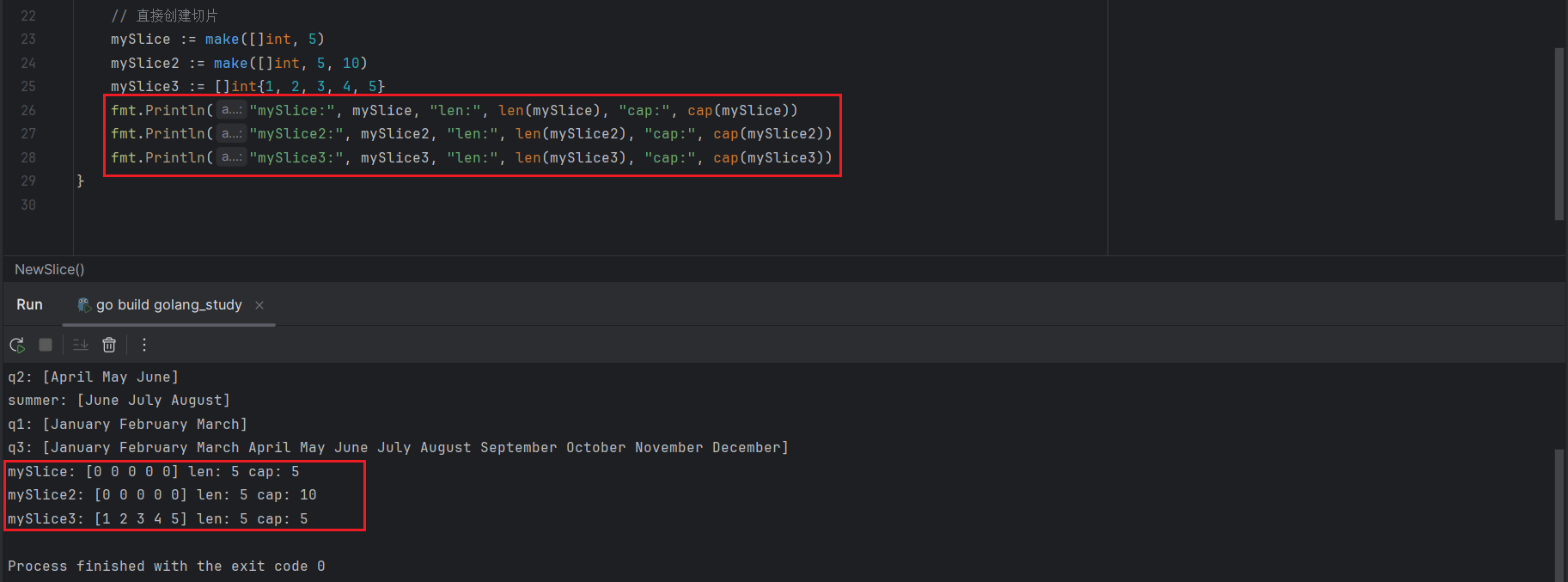
和数组类型一样,所有未初始化的切片,会填充元素类型对应的零值。
实际上,使用直接方式创建切片时,Go底层还是会有一个匿名数组被创建出来,然后调用基于数组创建切片的方式返回切片,只是上层并不需要关心这个匿名数组的操作。因此,最终切片都是基于数组创建的,切片可以看作是操作数组的指针。
4.2.7.2 切片的遍历
前面提到,切片可以看作是数组指针,因此操作数组元素的所有方法也适用于切片,例如切片也能够使用下标获取元素,使用len()函数获取元素个数,并支持使用range关键字来快速遍历所有的元素。
传统的数组遍历方法:
for i := 0; i < len(summer); i++ {
fmt.Println("summer[", i, "] =", summer[i])
}
也可以使用range关键字遍历:
for i, v := range summer {
fmt.Println("summer[", i, "] =", v)
}
4.2.7.3 动态增加元素
切片与数组相比,优势在于支持动态增加元素,甚至能够在容量不足的情况,在切片类型中,元素个数和实际可分配的存储空间是两个不同的值,元素的个数即切片的实际长度,而可分配的存储空间就是切片的容量。
一个切片的容量初始值根据创建方式有以下两种情况:
- 对于基于数组和切片创建的切片而言,默认的容量是从切片起始索引到对应底层数组的结尾索引。
- 对于通过内置make函数创建的切片而言,在没有指定容量参数的情况下,默认容量和切片长度一致。
因此,通常情况下一个切片的长度值小于等于其容量值,能够通过Go语言内置的cap()函数和len()函数来获取某个切片的容量和实际长度:
var oldSlice = make([]int, 5, 10)
fmt.Println("len(oldSlice):", len(oldSlice))
fmt.Println("cap(oldSlice):", cap(oldSlice))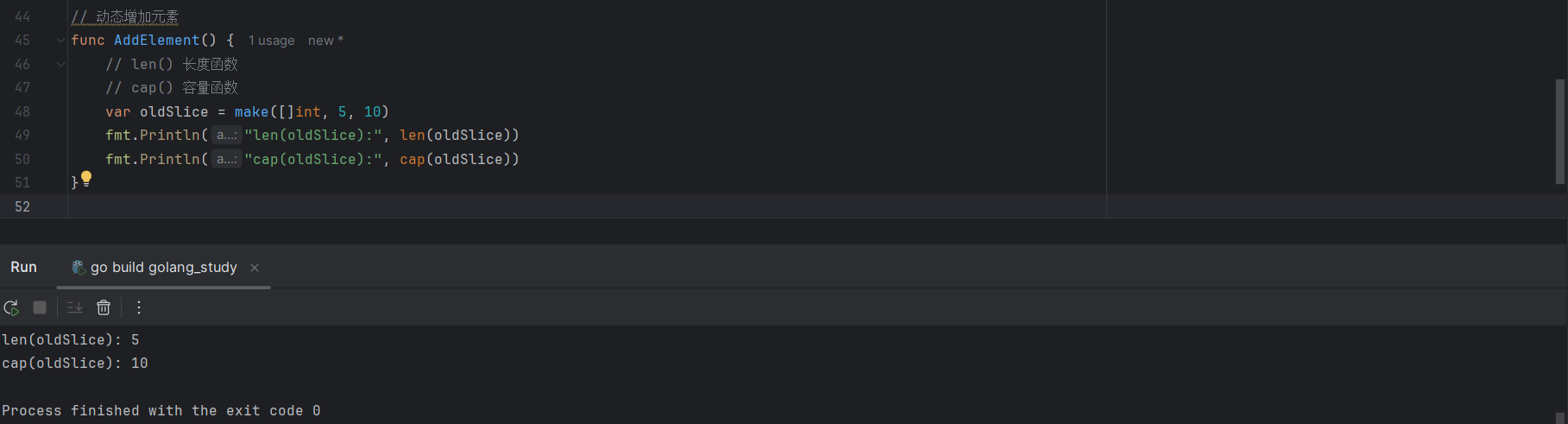
此时,切片 oldSilece 的默认值是 [0,0,0,0,0],可以通过append()函数向切片追加新元素:
newSlice := append(oldSlice, 1, 2, 3)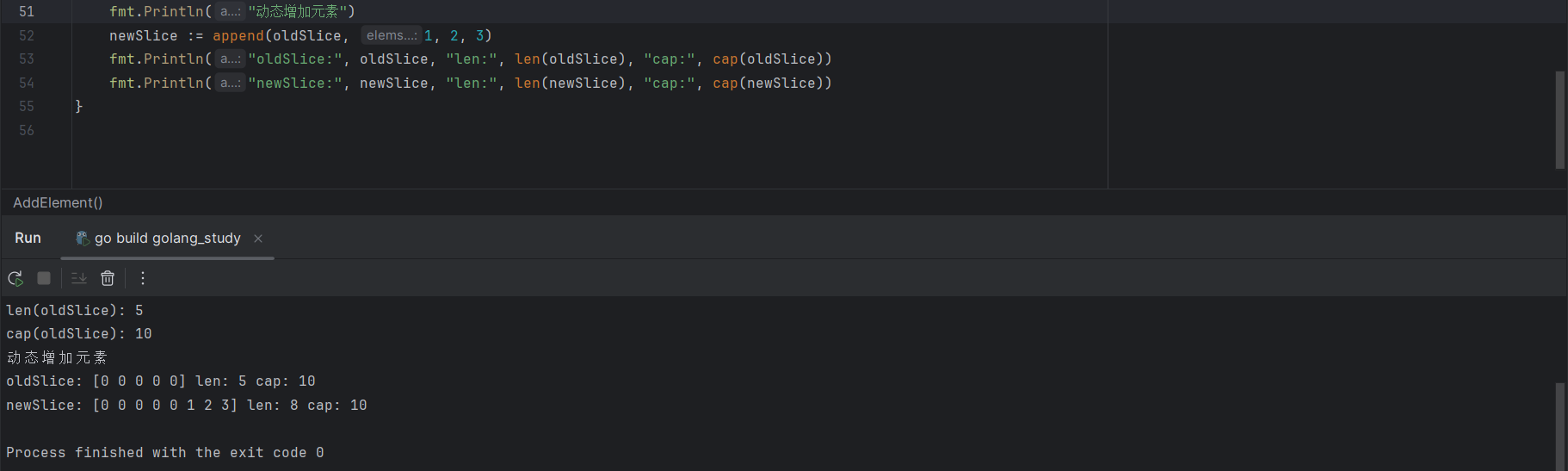
append() 函数的第二个参数是一个不定参数,可以根据自己的需求添加元素(大于等于1个),也可以直接将一个切片追加到另一个切片的末尾:
slice2 := []int{1, 2, 3, 4, 5}
// 注意append()后面的...不能省略
slice3 := append(newSlice, slice2...)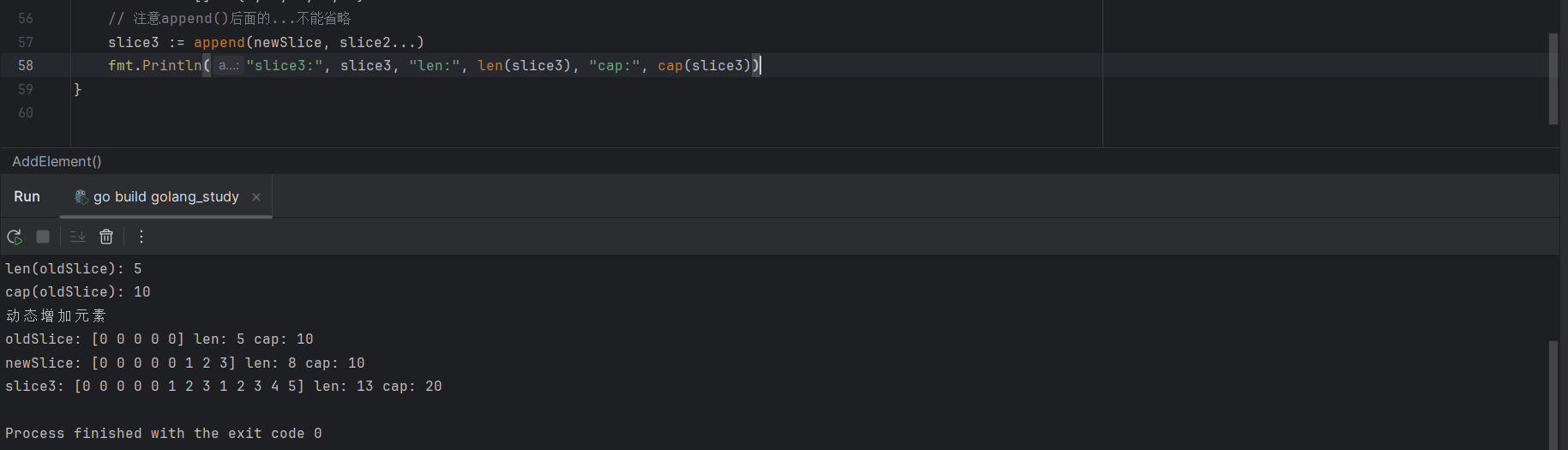
4.2.7.4 自动扩容
如果追加的元素个数超出切片的默认容量,则底层会自动进行扩容:
oldSlice := []int{1, 2, 3, 4, 5}
newSlice := append(oldSlice, 6, 7, 8, 9)
fmt.Println("oldSlice:", oldSlice, "len:", len(oldSlice), "cap:", cap(oldSlice))
fmt.Println("newSlice:", newSlice, "len:", len(newSlice), "cap:", cap(newSlice))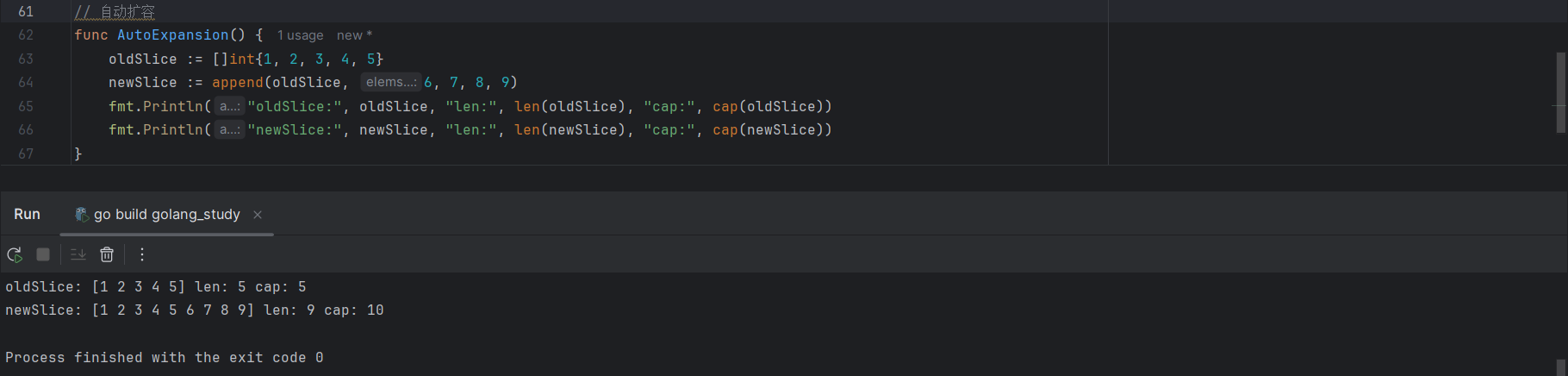
此时,newSlice 的长度变成了9,容量变成了10,需要注意的是 append() 函数并不会改变原来的切片,而是会生成一个容量更大的切片,然后把原有的元素和新元素一并拷贝到新切片中。
默认情况下,扩容后的新切片容量将会是原切片容量的两倍,如果还不能够容纳新元素,则按照同样的操作继续扩容,直到新切片的容量不小于原长度与要追加的元素之和。但是,当原切片的长度大于或等于1024时,Go语言会以原容量的1.25倍作为新容量的基准。
在编码中,如果能够事先预估切片的容量并在初始化时合理地设置容量值,可以大幅降低切片内部重新分配内存和搬送内存块的操作次数,从而提升程序性能。
4.2.7.5 内容赋值
Go语言提供了内置函数copy(),用于将元素从一个切片复制到另一个切片,如果两个切片不一样大,就会按照其中较小的那个切片元素个数进行复制。
slice1 := []int{1, 2, 3, 4, 5}
slice2 := []int{6, 7, 8}
// 复制slice1到slice2,复制slice1的前三个元素到slice2中
copy(slice2, slice1)
fmt.Println("slice1:", slice1, "len:", len(slice1), "cap:", cap(slice1))
fmt.Println("slice2:", slice2, "len:", len(slice2), "cap:", cap(slice2))
slice3 := []int{1, 2, 3, 4, 5}
slice4 := []int{6, 7, 8}
fmt.Println("复制slice4到slice3")
// 复制slice4到slice3,复制slice4的所有元素到slice3的前三个元素
copy(slice3, slice4)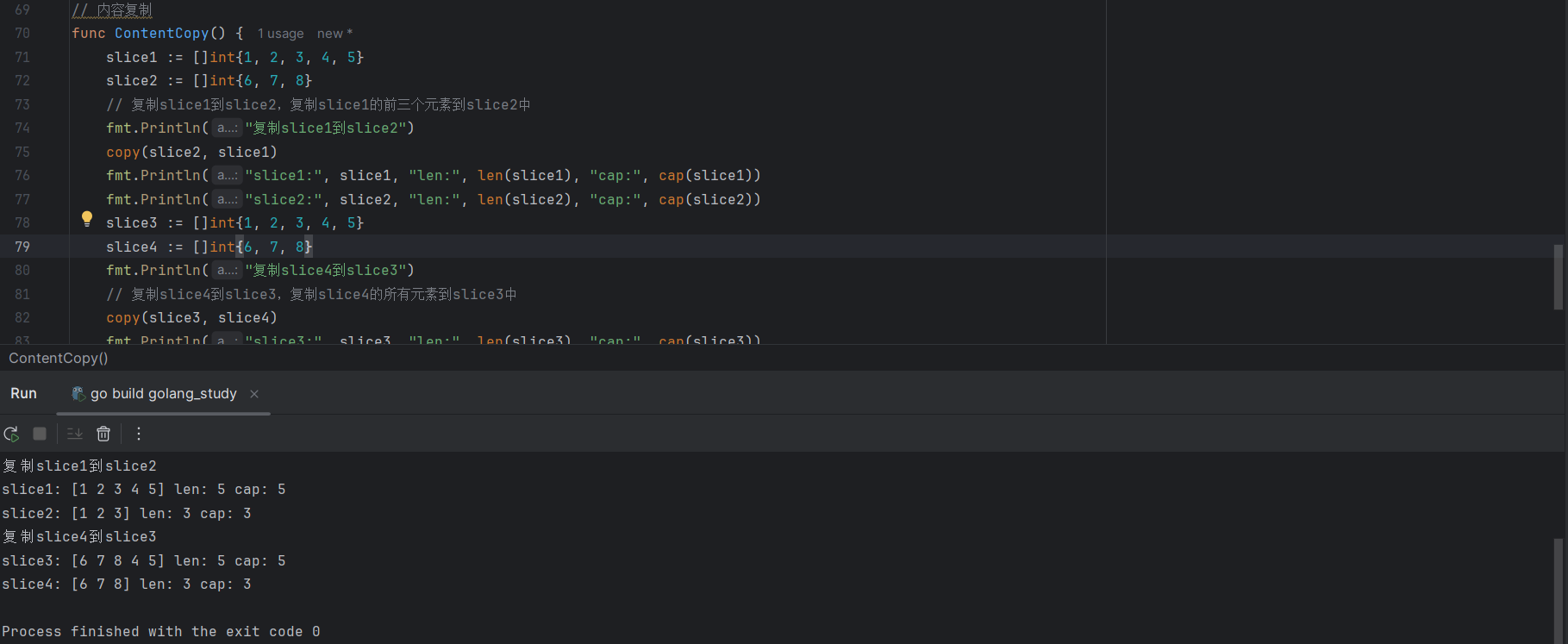
4.2.7.6 动态删除元素
切片除了支持动态增加元素之外,还可以动态删除元素,在切片中动态删除元素可以通过多种方式实现(底层是通过切片的切片实现):
slice1 := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
slice1 = slice1[:len(slice1)-5] // 删除 slice1 尾部 5 个元素
slice2 := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
slice2 = slice2[5:] // 删除 slice2头部 5 个元素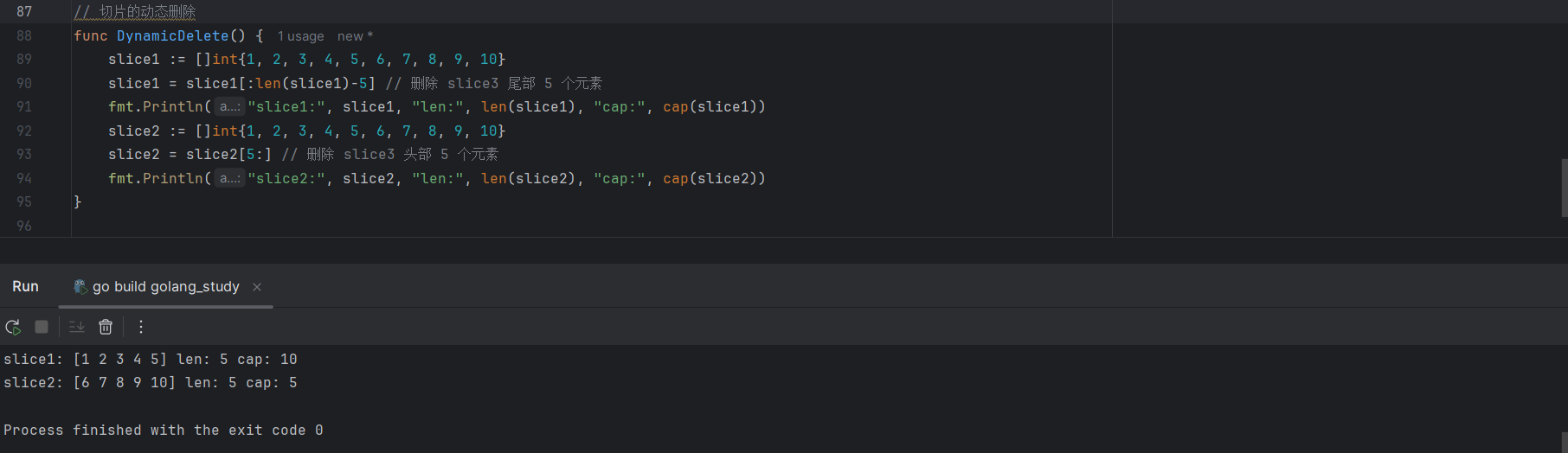
还能够通过 append 实现切片元素的删除:
slice3 := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
slice4 := append(slice3[:0], slice3[3:]...) // 删除开头三个元素
注意append方法的使用, 如 slice4 := append(slice3[:0], slice3[3:]...) 这种方式:
slice3[:0]创建了一个长度为 0 的切片,但底层数组仍然是slice3的底层数组。slice3[3:]创建了一个包含slice3从索引3开始的所有元素的切片。
append 将第一个切片的元素追加到第二个切片中,因此 slice4 包含 slice3 从索引3开始的所有元素。
这里的问题在于,由于slice4最初共享底层数组,对 slice4 的修改实际上也会影响到 slice3,从而导致 slice3 切片也发生了变化。
如果 slice4 由两个切片拼接,也会出现类似的问题,例如:
slice5 := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
slice6 := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
slice7 := append(slice5[:3], slice6[6:]...)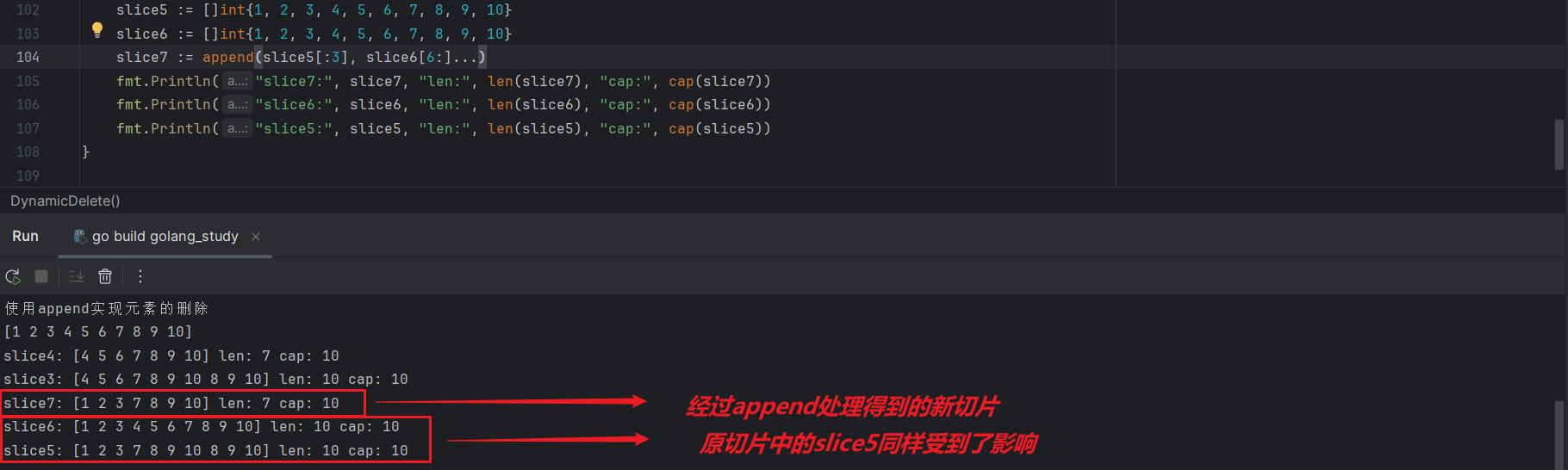
使用 copy 函数进行元素的删除:
slice8 := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
slice9 := make([]int, len(slice3)-3)
copy(slice9, slice3[3:]) // 删除开头前三个元素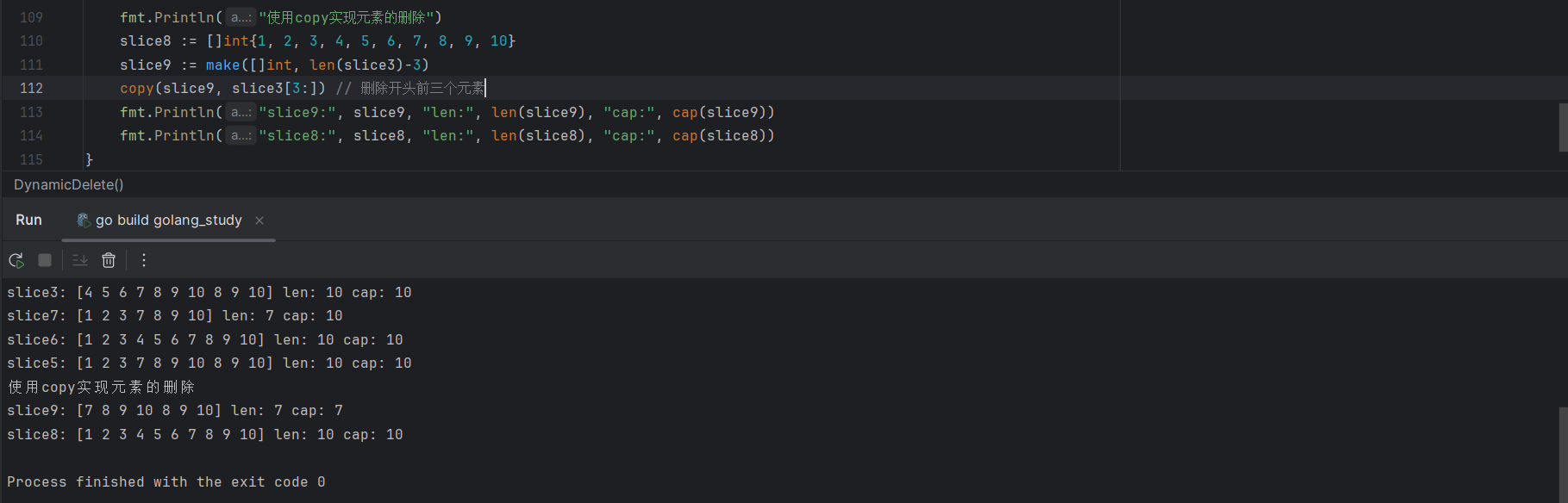
4.2.7.7 数据共享问题
切片底层是基于数组实现的,对应的结构体对象如下所示:
type slice struct {
array unsafe.Pointer //指向存放数据的数组指针
len int //长度有多大
cap int //容量有多大
}在结构体中使用指针存在不同实例的数据共享问题,示例代码如下:
slice1 := []int{1, 2, 3, 4, 5}
slice2 := slice1[1:3]
slice2[1] = 6
fmt.Println("slice1:", slice1)
fmt.Println("slice2:", slice2)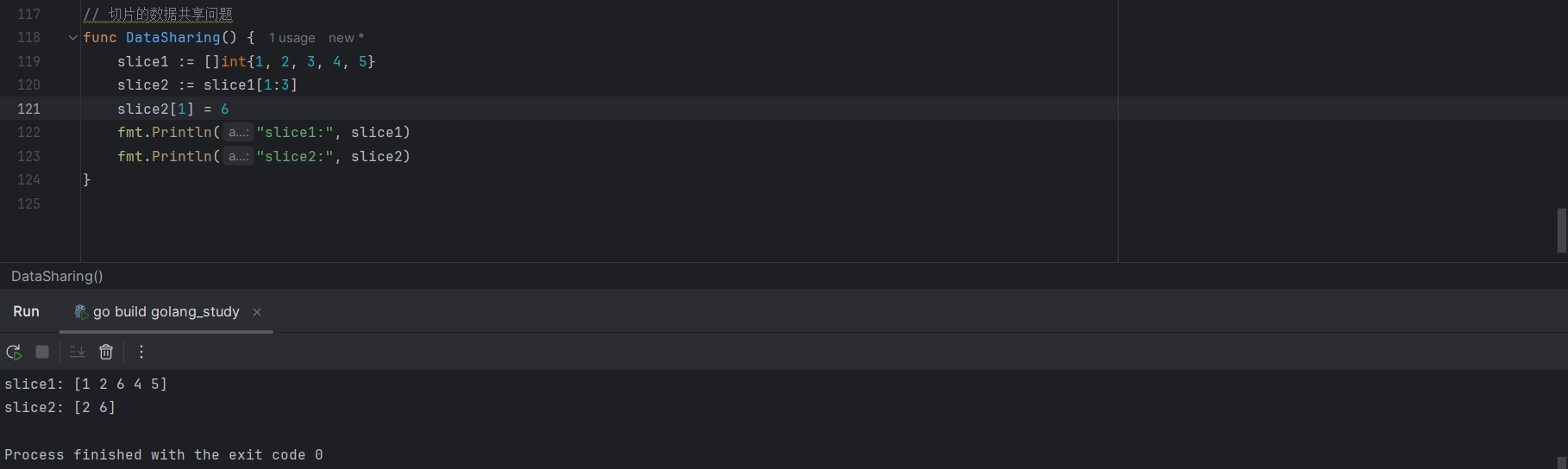
slice2 是基于 slice1 创建的,它们的数组指针指向了同一个数组,因此,修改 slice2 元素会同步到 slice1,因为修改的是同一份内存数据,这就是切片的数据共享问题。
可以按照如下方式,避免切片的数据共享问题。
slice3 := make([]int, 4)
slice4 := slice3[1:3]
slice3 = append(slice3, 0)
slice3[1] = 2
slice4[1] = 6
fmt.Println("slice3:", slice3)
fmt.Println("slice4:", slice4)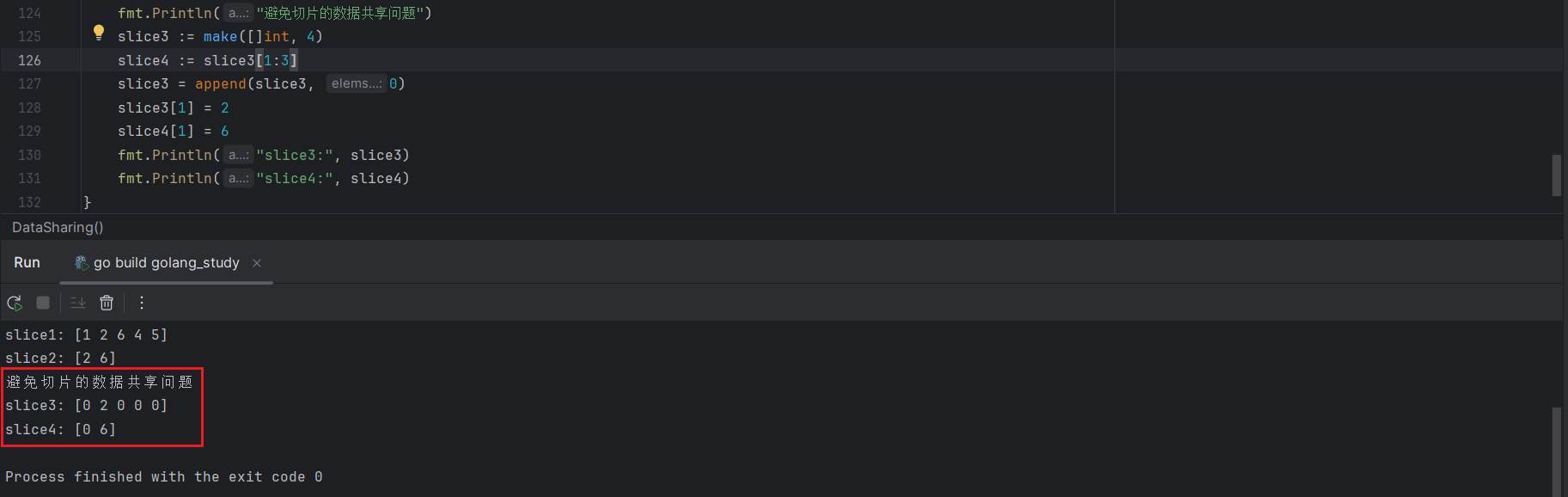
虽然 slice2 是基于 slice1 创建的,但是修改 slice2 不会再同步到 slice1,因为 append 函数会重新分配新的内存,然后将结果赋值给 slice1,这样一来,slice2 会和老的 slice1 共享同一个底层数组内存,不再和新的 slice1 共享内存,也就不存在数据共享问题了。
如下代码,虽然使用了append函数,但是没有重新分配内存空间,仍然存在数据共享问题。
slice5 := make([]int, 4, 5)
slice6 := slice5[1:3]
slice5 = append(slice5, 0)
slice5[1] = 2
slice6[1] = 6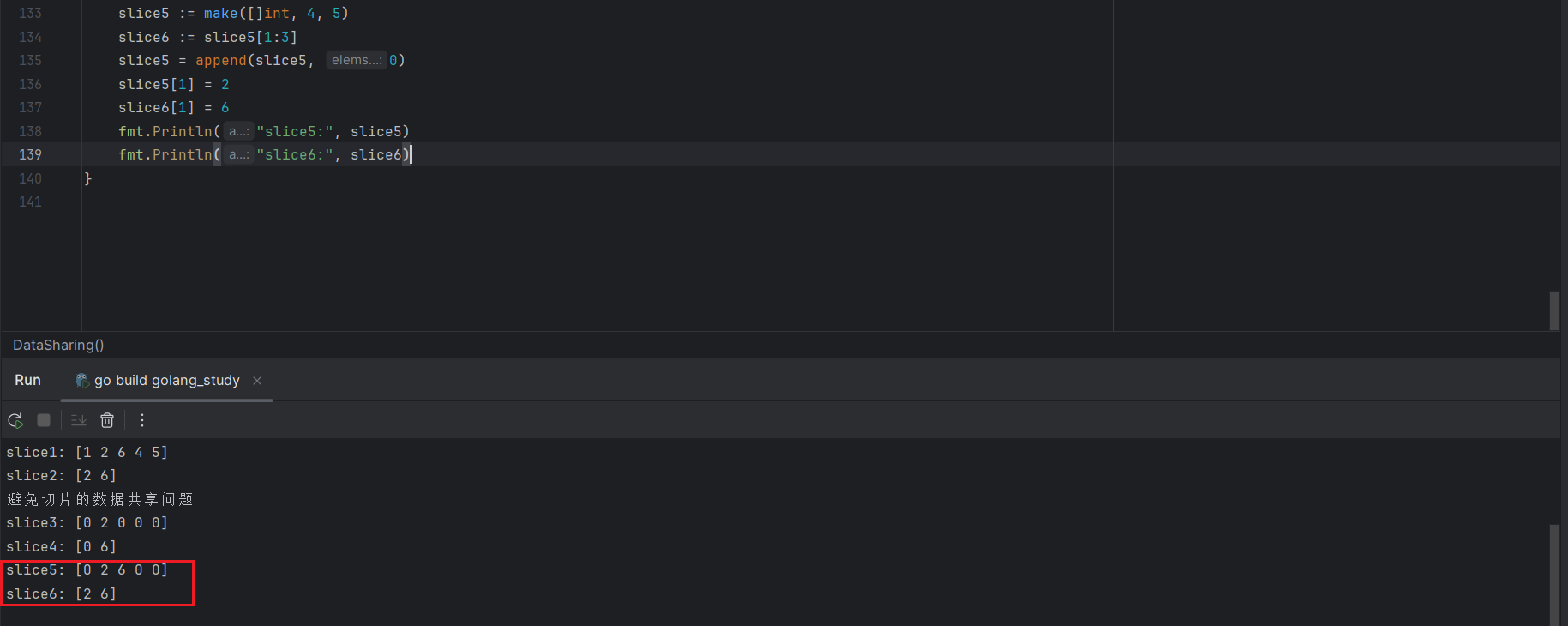
slice5 容量为5,执行 append 没有进行扩容操作。
4.2.8 字典
字典就是存储键值对映射关系的集合,在Go语言中,需要在声明时指定键和值的类型,此外Go语言中的字典是个无序集合,底层不会按照元素添加顺序维护元素的存储顺序。
如下所示,Go语言中字典的简单示例:
func DictExample() {
var tempMap map[string]int
tempMap = map[string]int{
"one": 1,
"two": 2,
"three": 3,
}
k := "two"
v, ok := tempMap[k]
// ok,如果key存在,则ok为true,否则ok为false
if ok {
fmt.Printf("the element of key %q:%d", k, v)
} else {
fmt.Println("Not found!")
}
}4.2.8.1 字典声明
字典的声明基本上没有多余的元素,例如:
var tempMap map[string]int
// tempMap:声明的字典变量名
// string:字典键的类型
// int:字典值的类型4.2.8.2 字典初始化
Go语言中,可以先声明再初始化变量,也可以通过 := 将字典的声明和初始化合并为一条语句:
testMap := map[string]int{
"one": 1,
"two": 2,
"three": 3,
}打印字典testMap,发现其并没有按照存储的顺序进行打印,这是因为Go语言中字典是个无序集合。
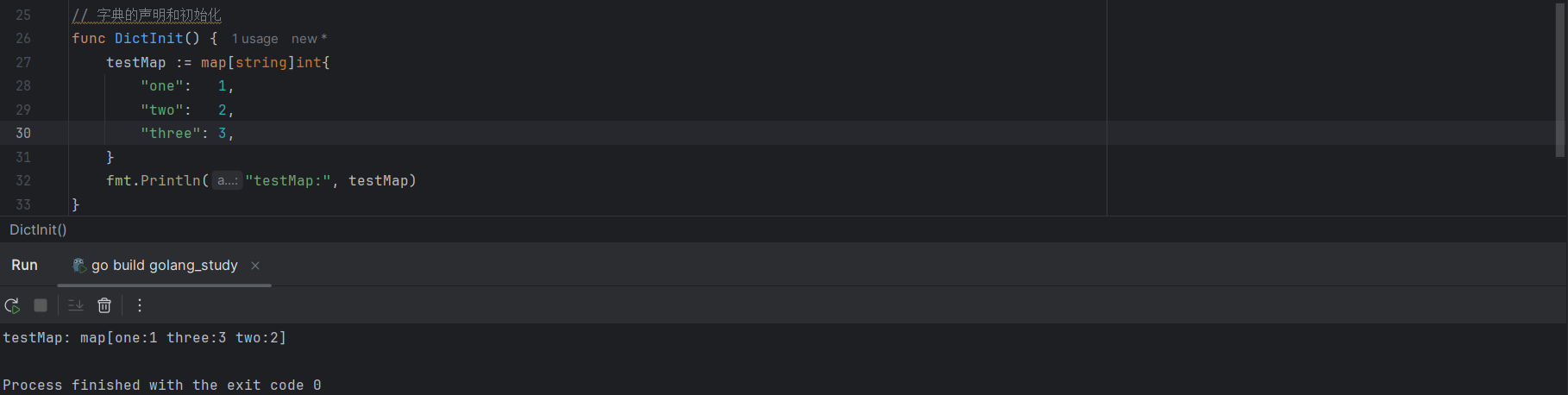
在Go语言中,字典的初始化通常要和初始化在一起进行,如果分开了出现编译的报错,如下所示:
var tempMap map[string]int
tempMap["one"] = 1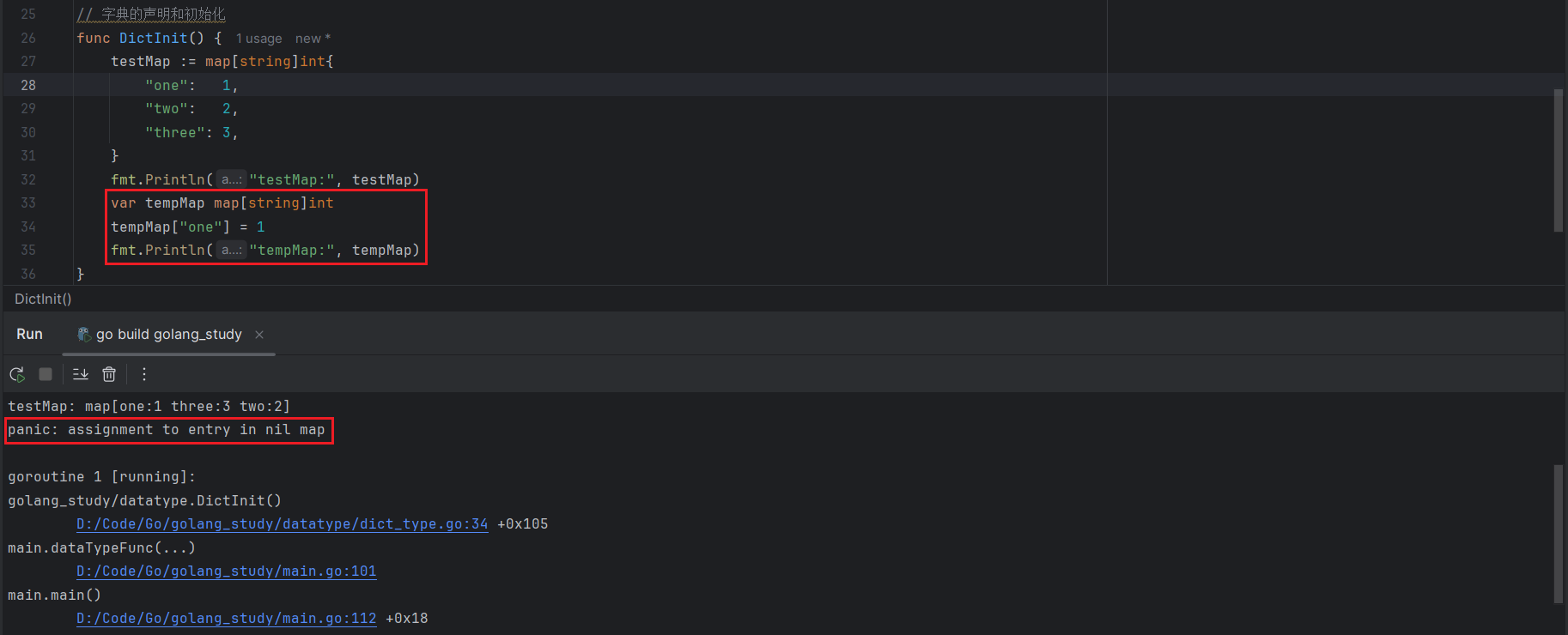
如果需要初始化一个空的字典,需要使用Go语言内置的 make() 函数:
var tempMap = make(map[string]int)
tempMap["one"] = 1
还可以通过 make() 函数的第二个参数选择是否在创建的时候指定该字典的初始化存储容量(超出会自动扩容):
testMap = make(map[string]int, 100)4.2.8.3 元素赋值
字典的赋值指定键值对即可,如下所示:
testMap["one"] = 14.2.8.4 查找元素
Go语言中,通过如下的代码查找特定的键值对:
value, ok := testMap["one"]
if ok {
// 字典中存储键"one"对应的值
}
// 如上代码,value是真正返回的键值,ok是是否在字典中找到key对应值的标识,这是一个布尔值,如果查找成功,返回true,否则返回false4.2.8.5 删除元素
Go语言中,使用delete() 用于删除容器内的元素,也能够用来删除字典元素,如下所示:
delete(testMap,"one")执行删除时,如果“one”不存在或者字典尚未进行初始化,也不会产生报错。
4.2.8.6 遍历元素
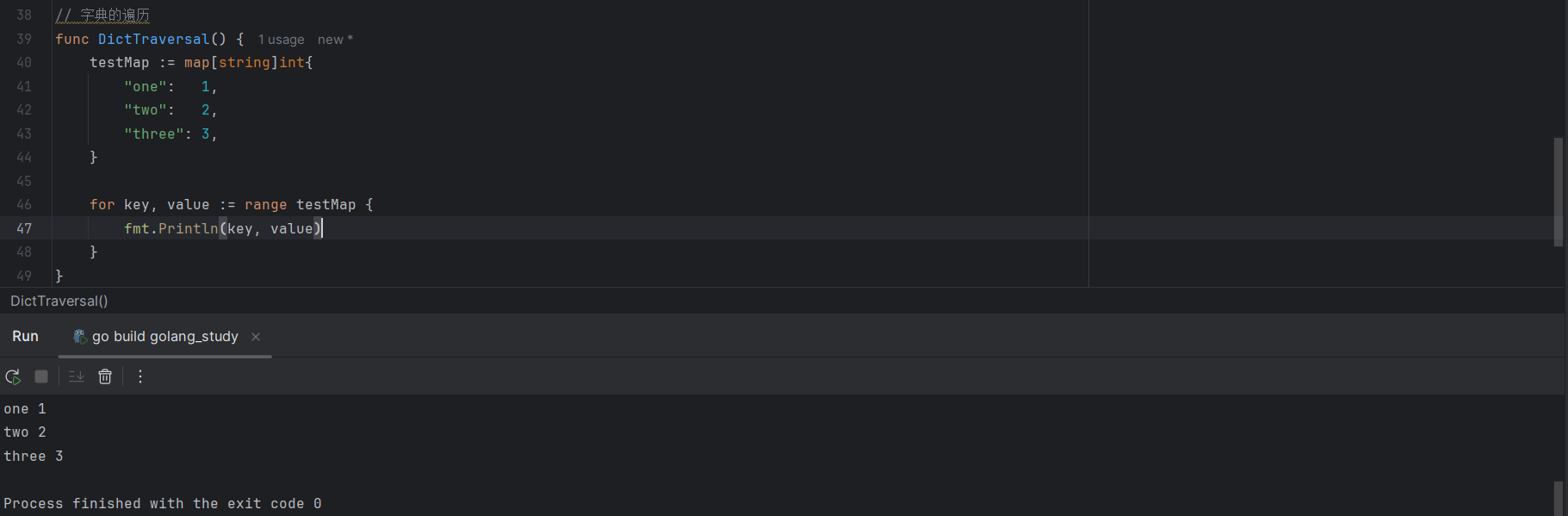
Go语言中,可以像遍历数组一样对字典进行遍历,如下所示:
testMap := map[string]int{
"one":1,
"two":2,
"three":3
}
for key,value := range testMap {
fmt.Println(key, value)
}
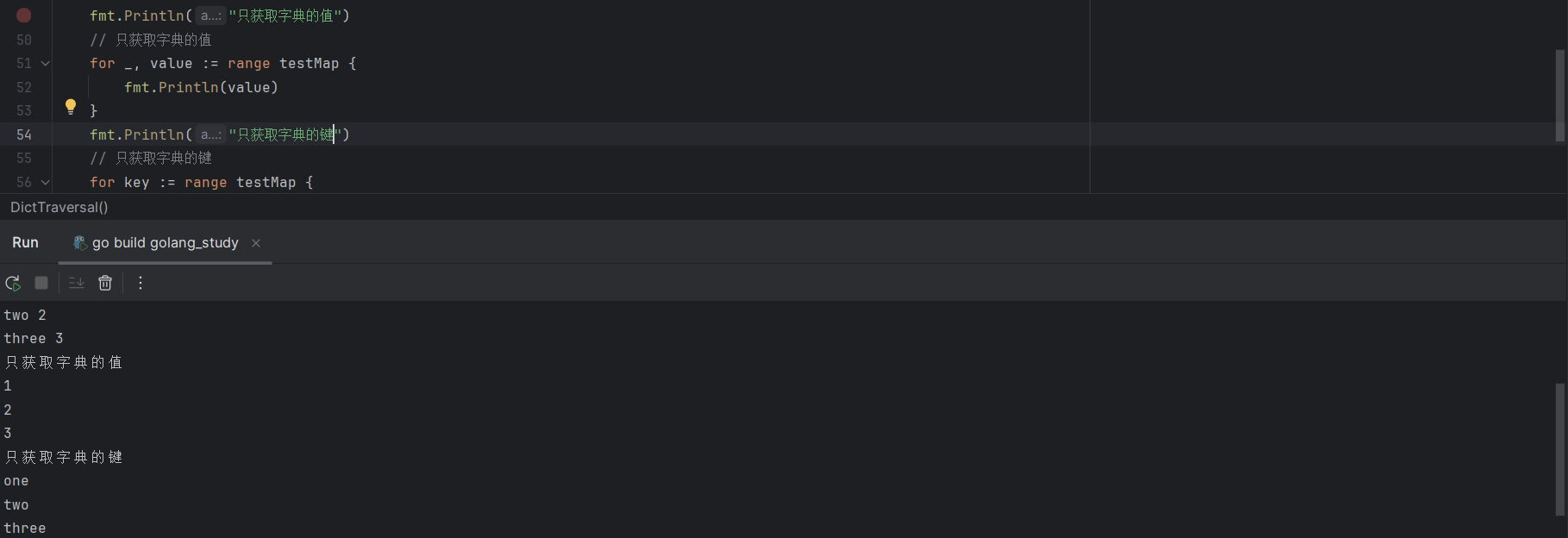
也可以使用匿名变量,只获取字典的值:
for _,value := range testMap {
fmt.Println( value)
}或者只获取字典的键:
for key := range testMap {
fmt.Println(key)
}
4.2.8.7 键值对调
testMap := map[string]int{
"one": 1,
"two": 2,
"three": 3,
}
newMap := make(map[int]string)
for k, v := range testMap {
newMap[v] = k
}
for k, v := range newMap {
fmt.Println(k, v)
}
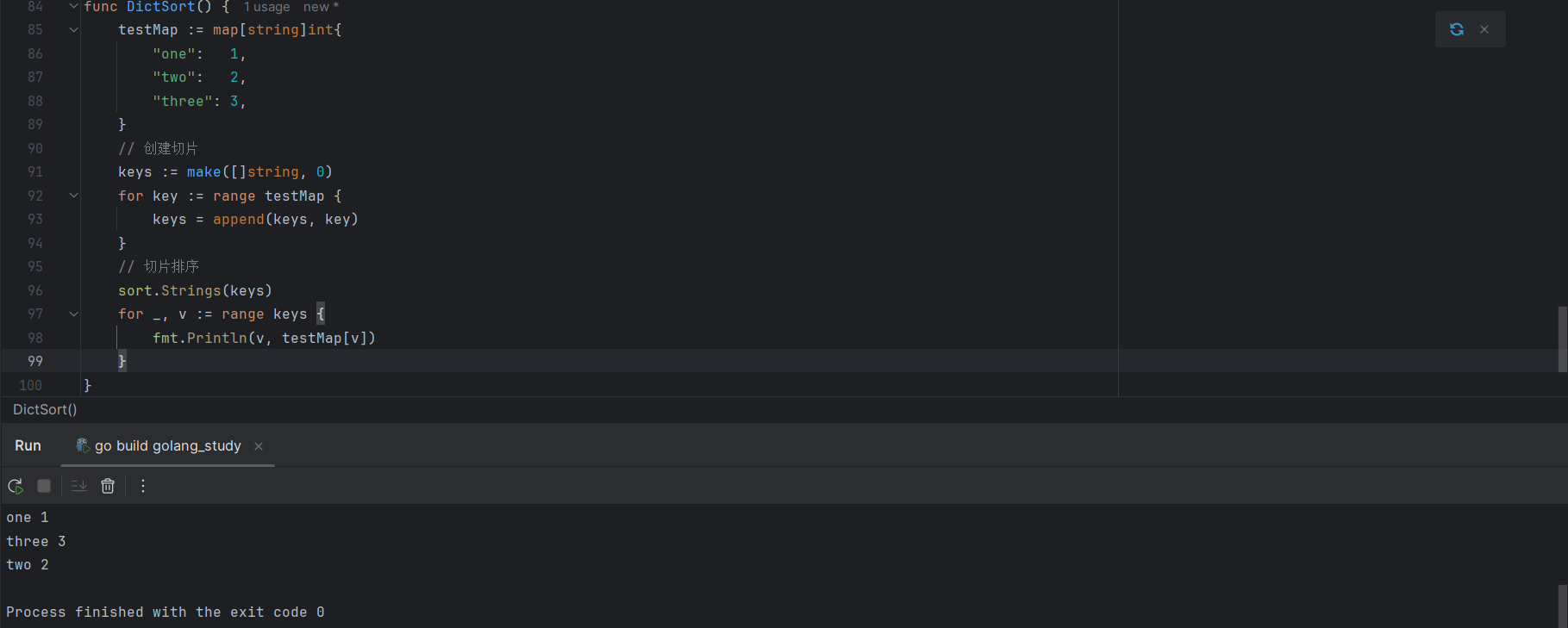
4.2.8.8 字典排序
Go语言中的字典是个无序集合,如果想要对字典进行排序,可以通过分别为字典的键或值创建切片,然后通过对切片进行排序实现。
按照键进行排序:
testMap := map[string]int{
"one": 1,
"two": 2,
"three": 3,
}
// 创建切片
keys := make([]string, 0)
for key := range testMap {
keys = append(keys, key)
}
// 切片排序
sort.Strings(keys)
for _, v := range keys {
fmt.Println(v, testMap[v])
}
按照值进行排序:
testMap := map[string]int{
"one": 1,
"two": 2,
"three": 3,
}
// 创建切片
values := make([]int, 0)
for _, value := range testMap {
values = append(values, value)
}
// 对字典的值进行排序
sort.Ints(values)
for _, v := range values {
fmt.Println(v)
}
4.2.9 指针
变量的本质是对一块内存空间的命名,我们可以通过引用变量名来使用这块内存空间存储的值,而指针则是用来指向这些变量值所在内存地址的值。
注:变量值所在内存地址的值不等于该内存地址存储的变量值。
Go语言中,如果一个变量是指针类型的,可以用这个变量来存储指针类型的值。
以下是Go语言中,指针的简单使用:
a := 100
var ptr *int // 声明指针类型
ptr = &a // 初始化指针类型值为变量 a
fmt.Println(ptr)
fmt.Println(*ptr)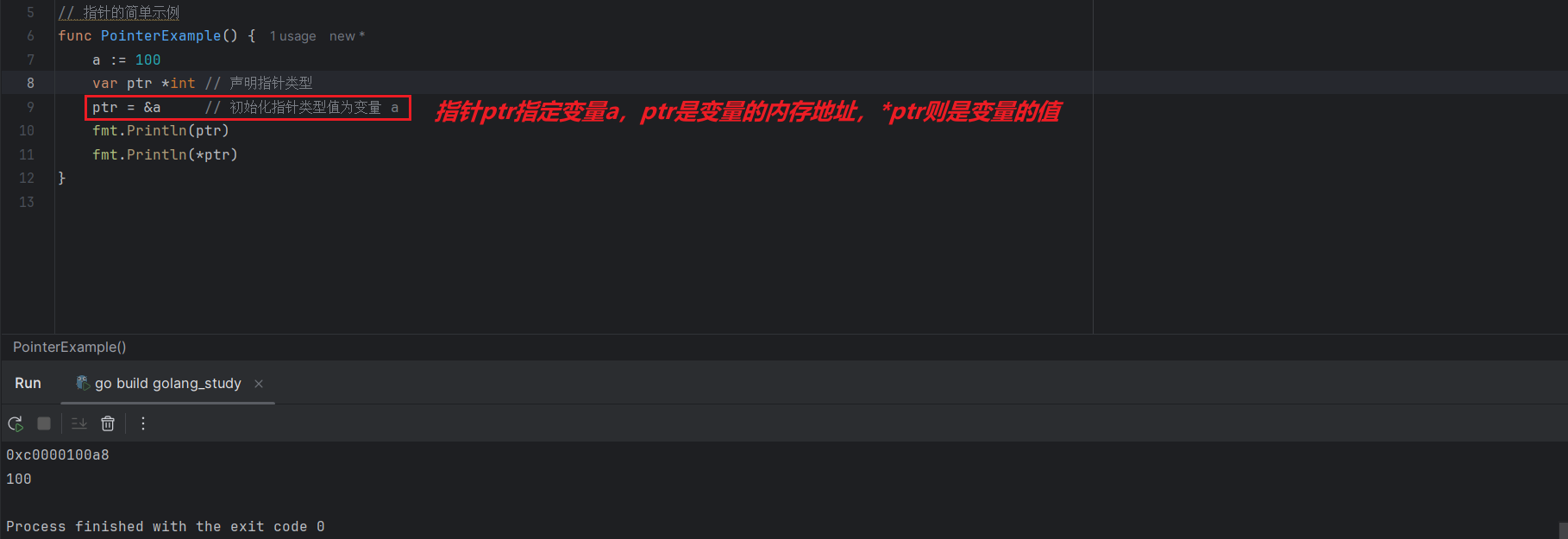
如上代码中,变量 ptr 就是一个指针类型,表示指向存储 int 类型值的指针,ptr本身是一个内存地址,因此需要通过内存地址进行赋值(通过 &a 获取变量 a 所在的内存地址),赋值之后,可以通过 *ptr 获取指针指向内存地址所存储的变量值,这种操作称为“间接引用”。
4.2.9.1 指针类型的声明和初始化
指针变量在传值时之所以可以节省内存空间,是因为指针指向的内存地址的大小是固定的,在32位机器上占4个字节,在64位机器上占8个字节,这与指针指向内存地址存储的值类型无关。
var ptr *int
fmt.Println(ptr)
fmt.Println(*ptr)
a := 100
var ptr *int
ptr = &a
fmt.Println(ptr)
fmt.Println(*ptr)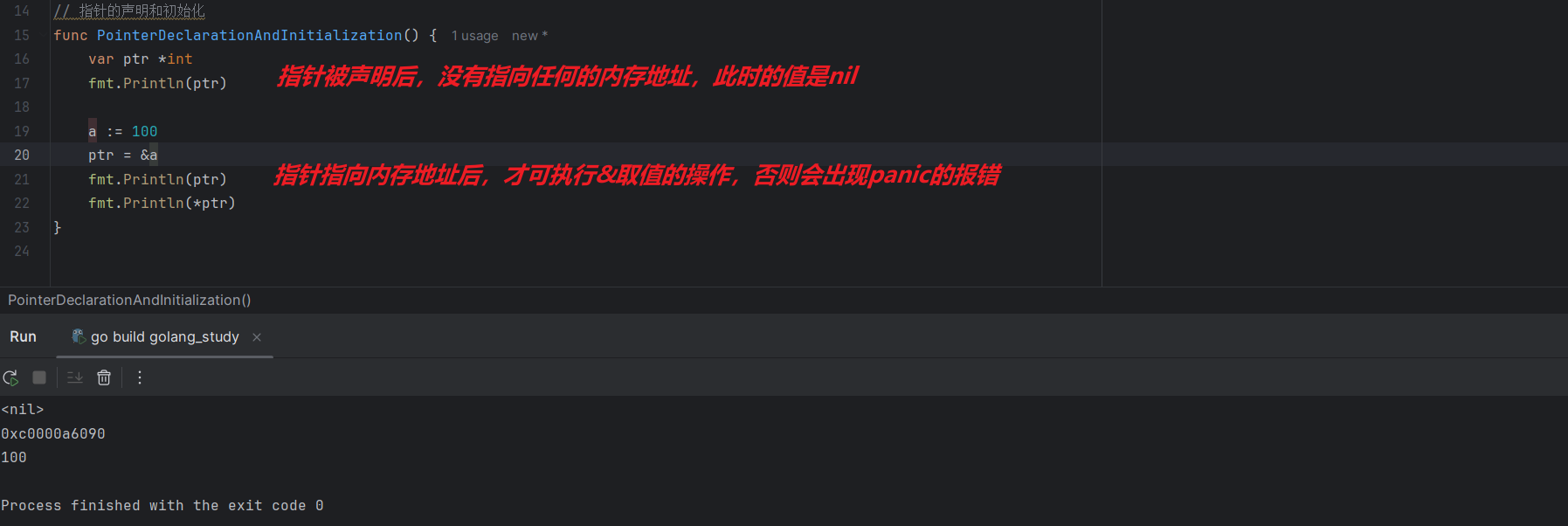
指针被声明后,没有指向任何的内存空间,此时指针的值是零值nil,可以通过&变量名的方式获取变量对应的内存地址,再将其赋值给指针,这样就完成指针的初始化操作。
也能够通过 := 实现指针类型的初始化,代码如下所示:
b := 100
ptr2 := &b
fmt.Printf("%p\n", ptr2)
fmt.Printf("%d\n", *ptr2)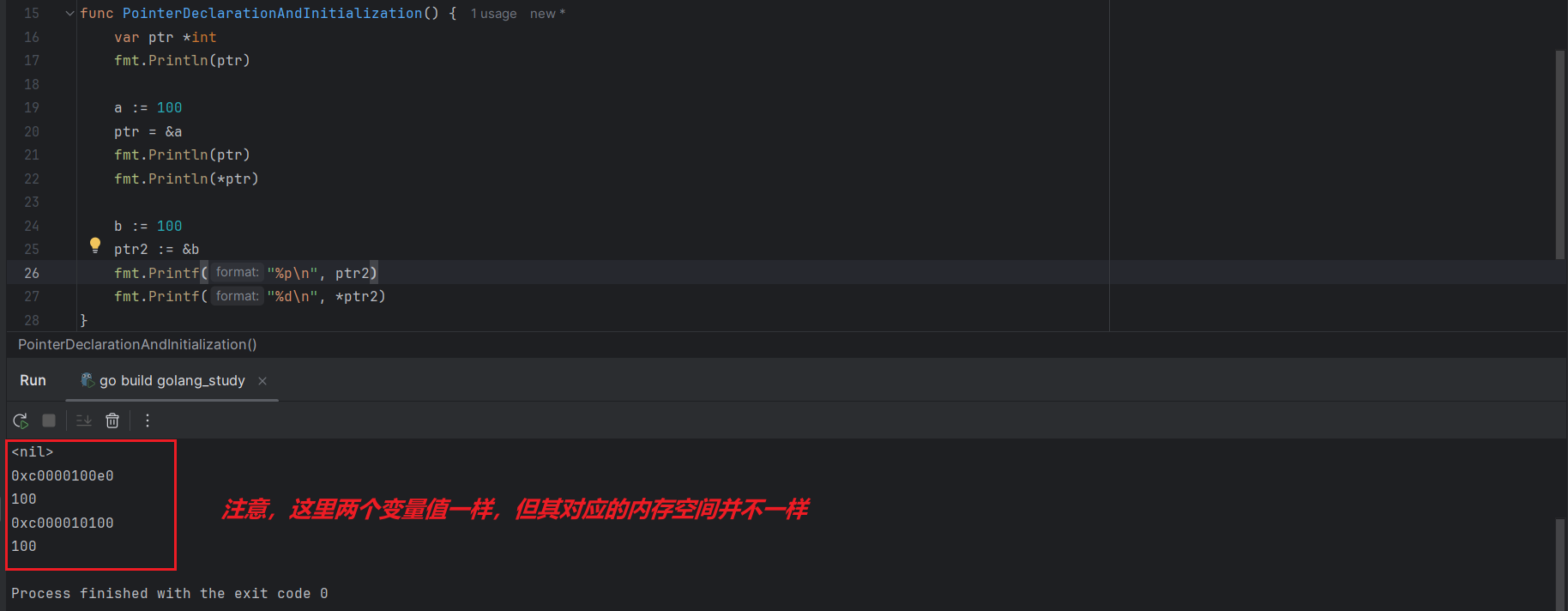
通过 := 进行指针的初始化,无需声明指针类型,底层会自动判断。
此外,也可以通过内置函数 new 声明指针:
ptr3 := new(int)
*ptr3 = 100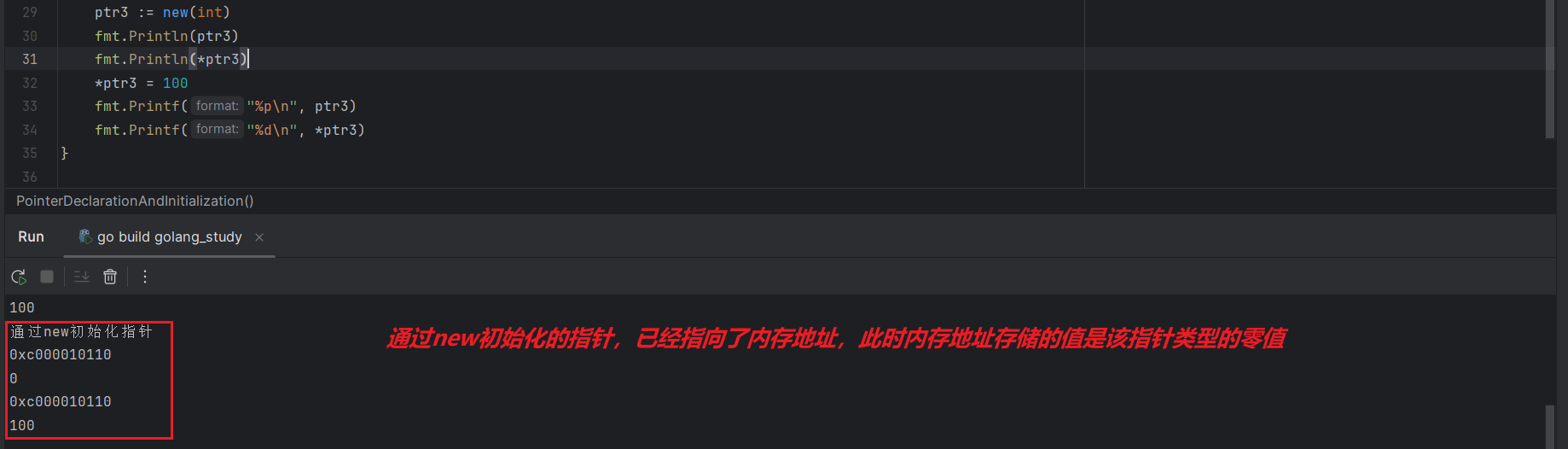
通过 new 初始化的指针,已经指向的内存地址,此时内存地址中存储的值是该指针类型的零值。
4.2.9.2 通过指针传值
通过指针传值能够节省内存空间,此外还能够在调用函数中实现对变量值的修改,因为直接修改了内存地址上存储的值,而不是值拷贝。
func swap(a, b int) {
a, b = b, a
fmt.Println(a, b)
}
func pointerSwap(a, b *int) {
*a, *b = *b, *a
fmt.Println(*a, *b)
}
// 值拷贝
func PointerValueCopyExample() {
a := 10
b := 20
fmt.Println("直接进行值拷贝")
swap(a, b)
fmt.Println(a, b)
fmt.Println("通过指针进行值交换")
pointerSwap(&a, &b)
fmt.Println(a, b)
}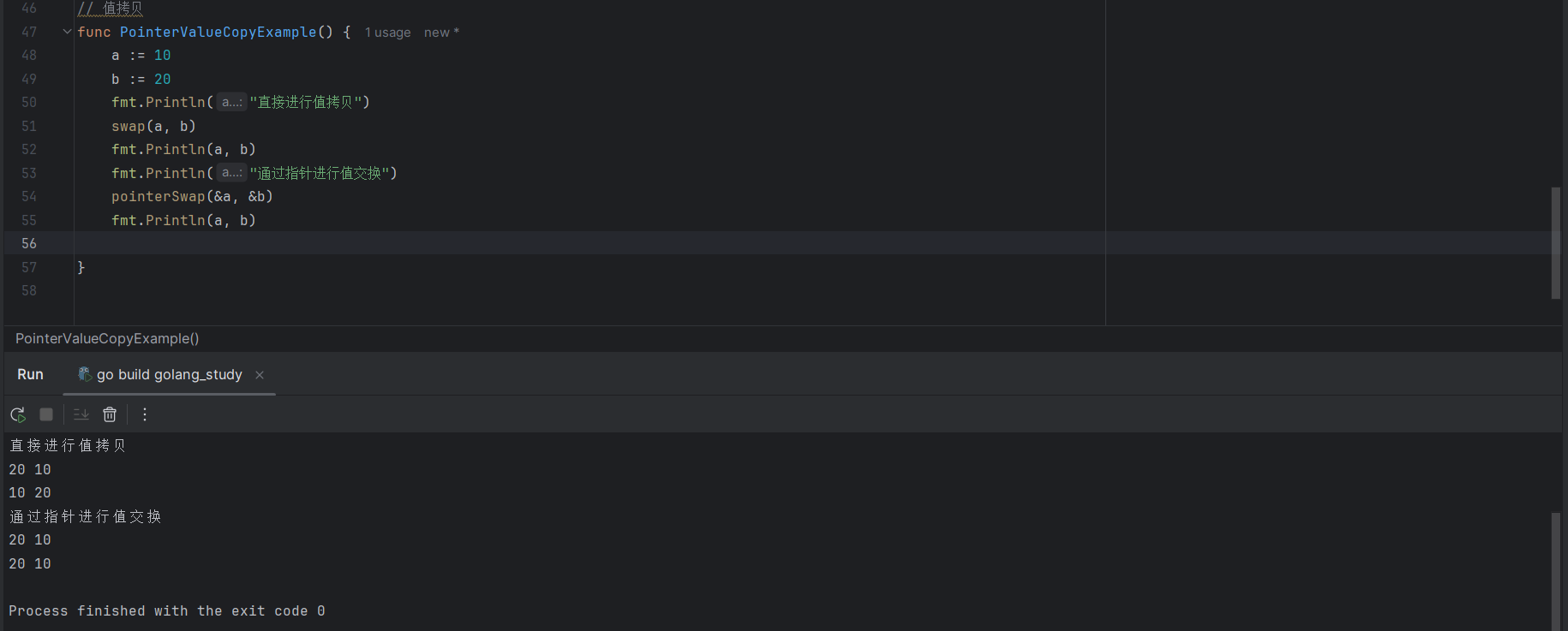
如上运行结果,可以发现通过指针进行值交换,变量的值也会发生变化,这里是因为指针的交换是直接修改内存地址上存储的值,调用完交换函数后,对应的内存空间值也进行了交换,因此外部的指针指向变量地址存储的值也发生了变化。
4.2.9.3 unsafe.Pointer
unsafe.Pointer 是特别定义的一种指针类型,能够包含任意类型变量的地址,以下是Go语言官方的定义:
- 任何类型的指针都可以被转化为 unsafe.Pointer;
- unsafe.Pointer 可以被转化位任何类型的指针;
- unintpr 可以被转化为 unsafe.Pointer;
- unsafe.Pointer 可以被转化为 uintptr。
因此,unsafe.Pointer 可以在不同的指针类型之间做转化,从而可以表示任意可寻址的指针类型:
i := 10
var p *int = &i
var fp *float32 = (*float32)(unsafe.Pointer(p))
*fp = *fp * 10
fmt.Println(i)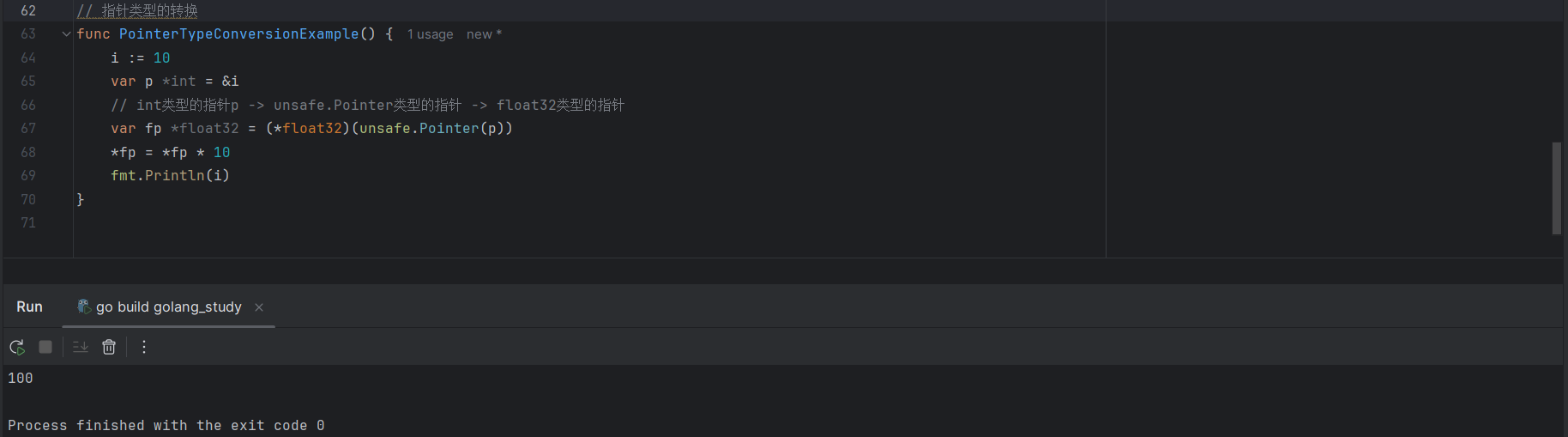
如上代码中,首先是声明了一个int类型的指针 p 指向变量 i ,然后int类型的指针转化为unsafe.Pointer再转化为float32类型的指针,最终对p指向内存地址的变量进行修改,打印出来i的地址发生了变化。
unsafe.Pointer 是一个万能指针,可以在任何指针类型之间进行转化,绕过了Go语言的类型安全机制,因此是一个不安全的操作。
unsafe.Pointer 还可以与 uintptr 类型之间相互转化,uintptr 是 Go语言内置的可以用于存储指针的整型,而整型是可以进行运算的,因此将 unsafe.Pointer 转化为 uintptr 类型后,就可以让本不具备运算能力的指针具备了指针运算能力:
arr := [3]int{1, 2, 3}
ap := &arr
// unsafe.Sizeof 数组元素偏移量
// ap由unsafe.Pointer -> uintptr -> unsafe.Pointer
sp := (*int)(unsafe.Pointer(uintptr(unsafe.Pointer(ap)) + unsafe.Sizeof(arr[0])))
*sp += 3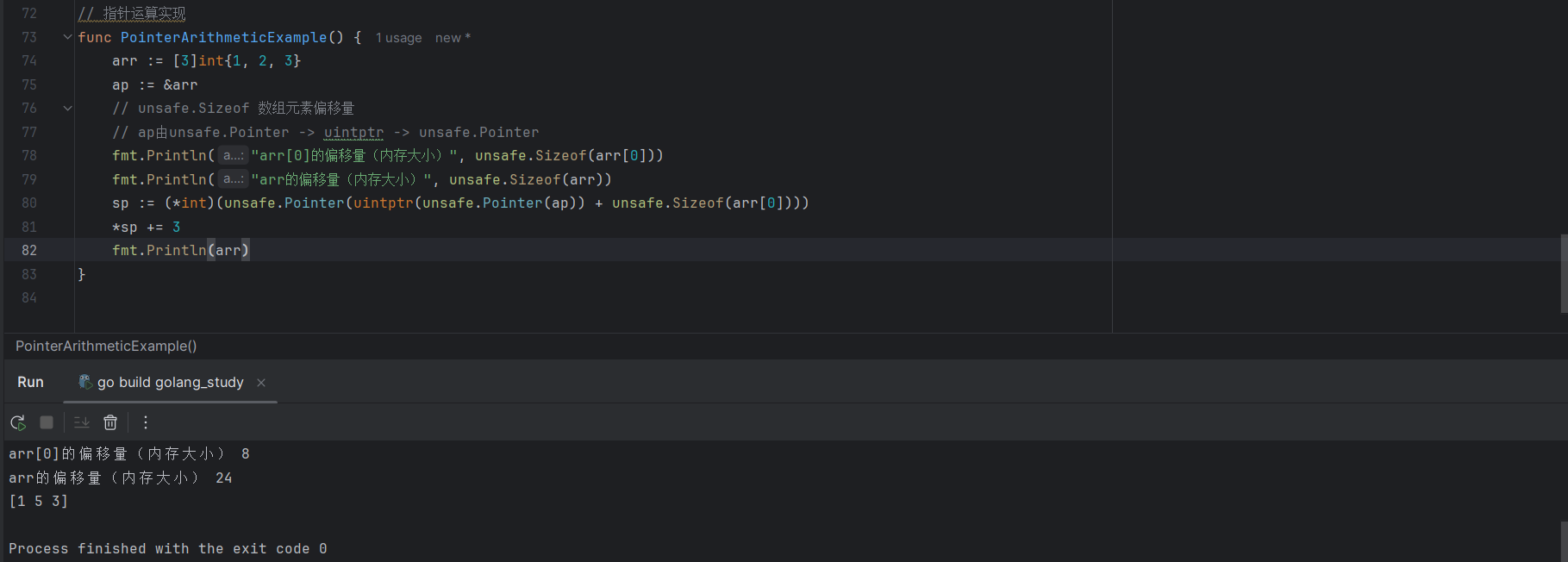
这里,将arr数组的内存地址赋值给指针ap,通过unsafe.Pointer转化为uintptr类型,再加上数组中第一个元素的偏移量,就可以得到该数组中第二个元素的内存地址,最后通过unsafe.Pointer将其转化为int类型指针赋值给sp,修改sp指针指向内存地址的变量值。
通过如上操作,能够绕过Go语言中指针的安全限制,实现对指针的动态偏移和计算,但这样操作,如果数组发生了越界也不会报错,而是返回下一个内存地址的值,破坏了内存的安全限制,因此这个操作也是不安全的操作,尽量避免unsafe.Pointer的相关使用,必须使用时需要非常谨慎。
5.Go语言中的流程控制
流程控制主要用于设定计算执行的顺序,简历程序的逻辑结果,Go语言的流程控制语句与其他语言类似,支持如下几种流程控制语句:
- 条件语句:用于条件判断,对应的关键字有if、else和else if;
- 分支语句:用于分支选择,对应的关键字有switch、case和select(用于通道);
- 循环语句:用于循环迭代,对应的关键字有for和range;
- 跳转语句:用于代码跳转,对应的关键字有goto。
5.1 条件语句
条件语句的示例模板:
// if
if condition {
// do something
}
// if...else...
if condition {
// do something
} else {
// do something
}
// if...else if...else...
if condition1 {
// do something
} else if condition2 {
// do something else
} else {
// catch-all or default
}注意以下几点:
- 条件语句不需要使用括号
()将条件包含起来; - 无论语句体内有几条语句,花括号
{}都是必须存在的; - 左花括号
{必须与 if 或者 else 处于同一行; - 在 if 之后,条件语句之前,可以添加变量初始化语句,使用
;间隔,例如:if score := 100;score > 90 {。
以下是一个简单的条件语句代码示例:
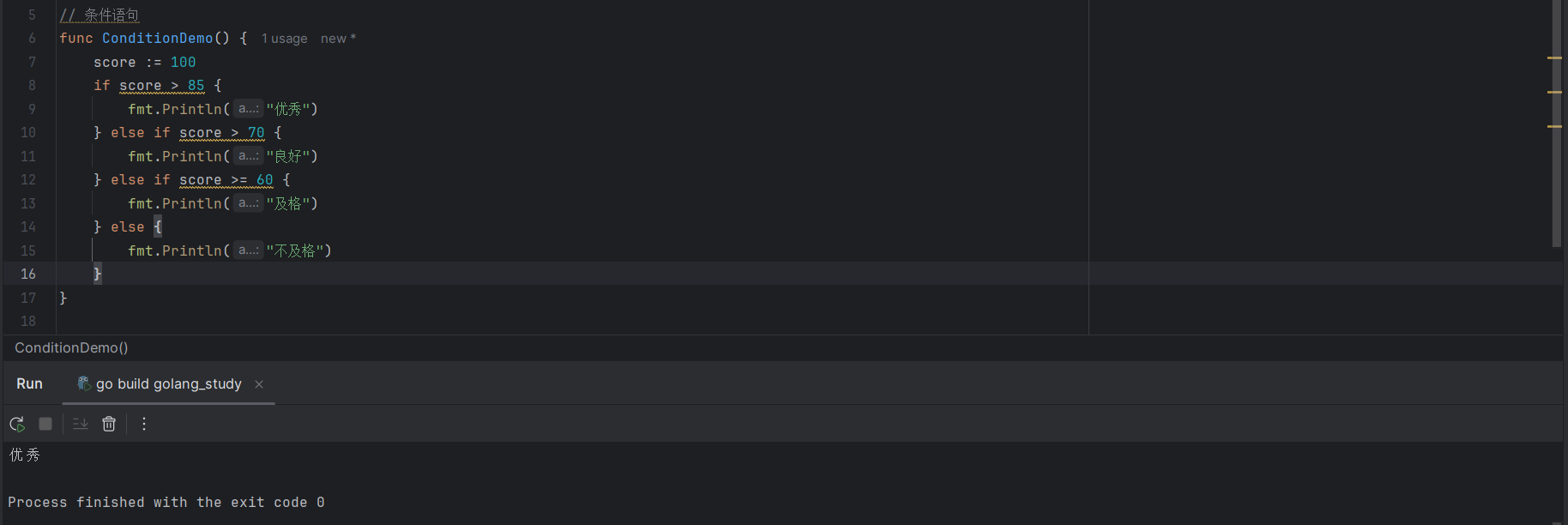
score := 100
if score > 85 {
fmt.Println("优秀")
} else if score > 70 {
fmt.Println("良好")
} else if score >= 60 {
fmt.Println("及格")
} else {
fmt.Println("不及格")
}
5.2 分支语句
分支语句会根据传入条件的不同,选择不同的分支代码执行。
分支语句的示例模板:
switch var1 {
case val1:
...
case val2:
...
case val3,val4:
...
case val5:
...
fallthrough // 添加该语句
default:
...
}注意以下几点:
- 和条件语句一样,左花括号
{必须与switch处于一行; - 单个
case中,可以出现多个结果选项(通过逗号分隔); - Go语言中的分支语句不需要break来明确退出一个case;
- 只有在case中明确添加 fallthrough 关键字,才会继续执行紧跟着的下一个case语句;
- 可以不设定 switch 之后条件表达式,这种情况下,整个 switch 结构与多个if...else...的逻辑作用等同。
一个简单的分支语句示例:
score := 100
switch {
case score > 85:
fmt.Println("优秀")
case score > 70 && score <= 85:
fmt.Println("良好")
case score >= 60 && score <= 70:
fmt.Println("及格")
default:
fmt.Println("不及格")
}Go语言中,可以通过逗号分隔不同的分支条件达到合并分支的目的,如 case 90,100,而不能像其他语言一样,通过相邻的case语句来进行分支的合并,这是因为Go语言不需要通过break退出某个分支,上一个case分支语句执行结束后,会自动进行退出,如果一定要执行后续的case语句,可以通过fallthrough语句来声明。
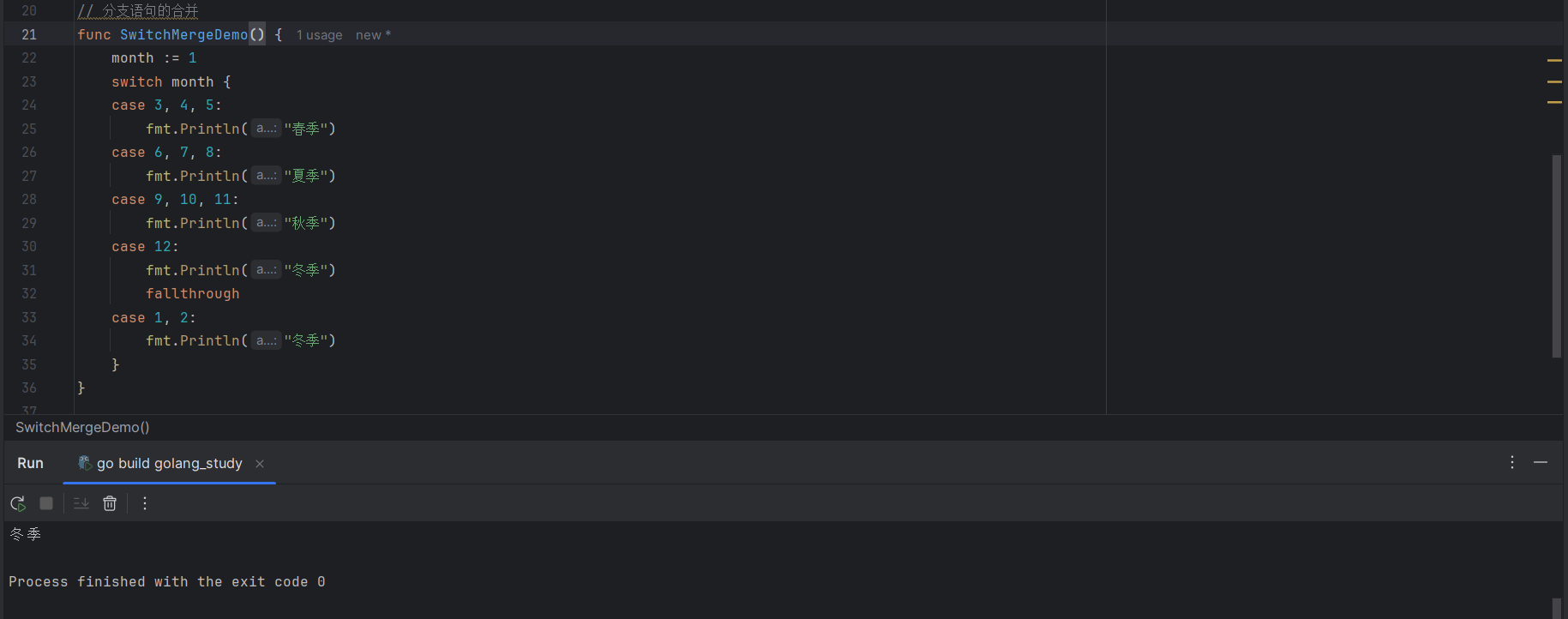
month := 1
switch month {
case 3, 4, 5:
fmt.Println("春季")
case 6, 7, 8:
fmt.Println("夏季")
case 9, 10, 11:
fmt.Println("秋季")
case 12:
fmt.Println("冬季")
fallthrough
case 1, 2:
fmt.Println("冬季")
}
5.3 循环语句
Go语言中使用循环语句,需要注意以下几点:
- 和条件语句、分支语句一样,左花括号
{必须与for处于同一行; - 只支持for关键字循环语句,不支持while和do-while结构的循环语句;
- 可以通过for-range结构对可迭代的集合进行遍历;
- 支持基于条件判断进行循环迭代;
- 允许在循环条件中定义和初始化变量,且支持多重赋值;
- Go语言的for循环同样支持continue和break来控制循环,但是它提供了一个更高级的break,可以选择中断哪一个循环。
5.3.1 for循环
Go语言的循环语句只支持 for 关键字,而不支持 while 和 do-while 结构,Go语言中,for循环的循环条件不包含括号,示例代码如下:
sum := 0
for i :1; i <= 100; i++ {
sum += i
}
fmt.Println(sum)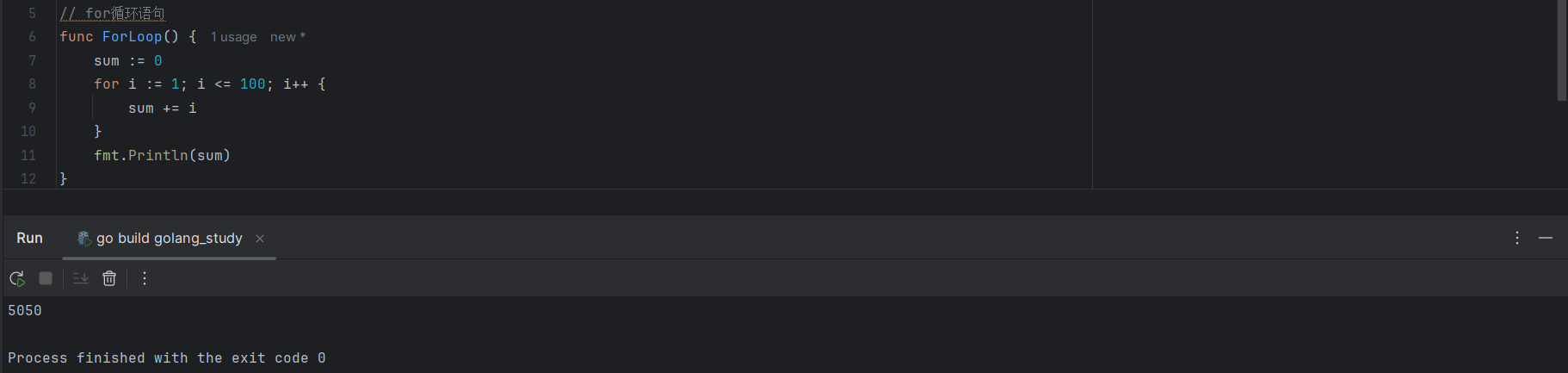
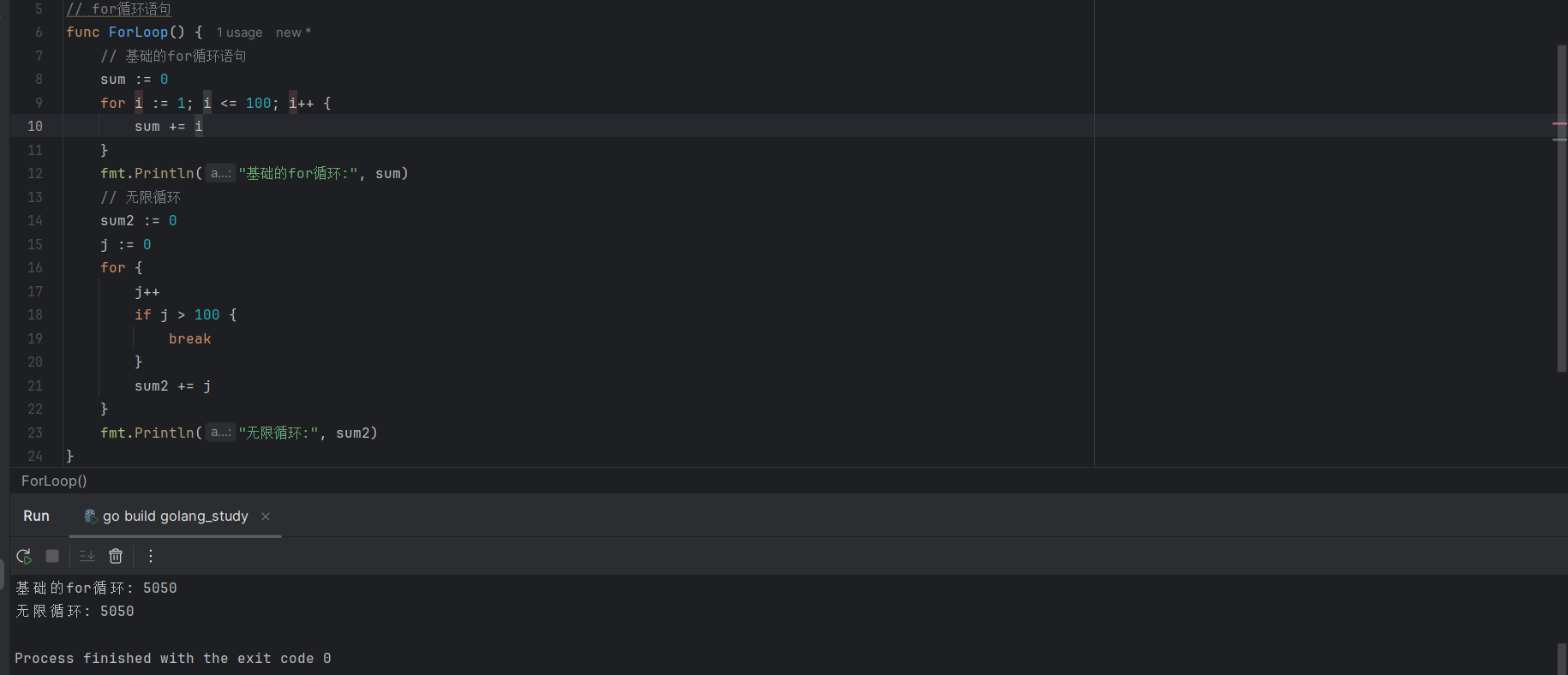
5.3.2 无限循环
Go语言仅支持for循环,针对无限循环的场景,可以通过不带循环条件的for循环实现,代码如下:
// 不指定循环语句,直接进行for循环,通过break退出循环语句
sum2 := 0
j := 0
for {
j++
if j > 100 {
break
}
sum2 += j
}
5.3.3 多重循环
for 循环的条件表达式也支持多重赋值,可以实现数组/切片首尾元素的交换,代码如下:
array := []int{1, 2, 3, 4, 5, 6}
for i, j := 0, len(array)-1; i < j; i, j = i+1, j-1 {
array[i], array[j] = array[j], array[i]
}
fmt.Println(array)
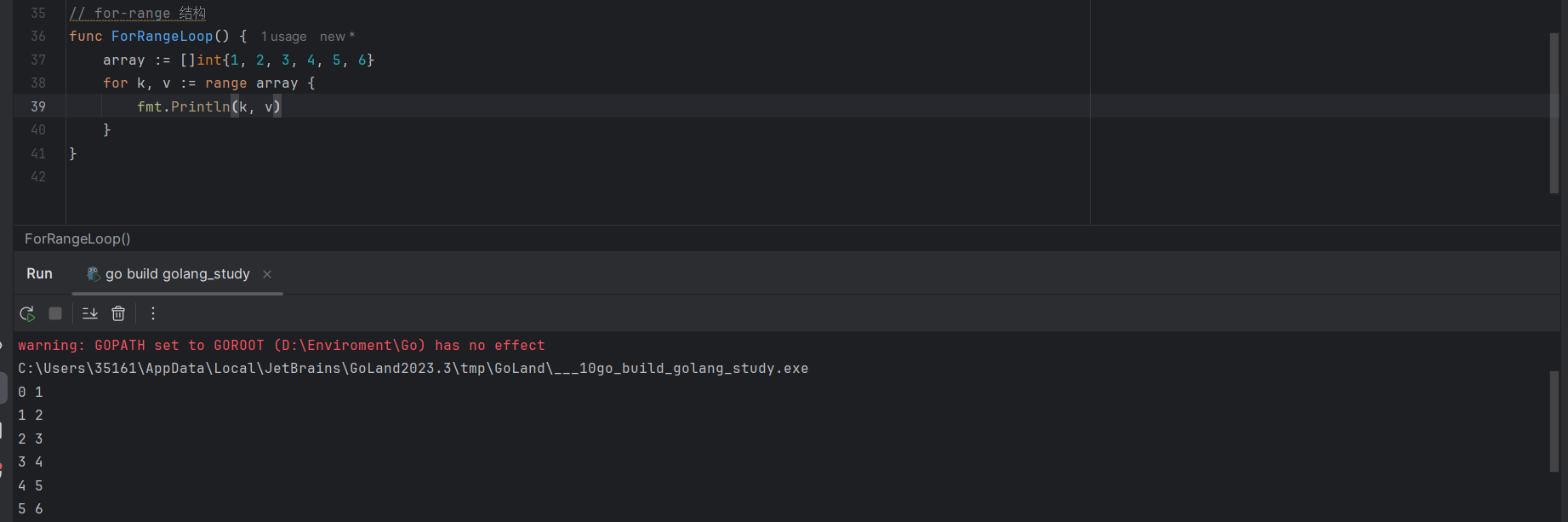
5.3.4 for-range结构
Go语言中支持通过for-range结构对于可迭代的集合(数组、切片、字典)进行循环遍历,使用方式如下:
array := []int{1, 2, 3, 4, 5, 6}
for k, v := range array {
fmt.Println(k, v)
}
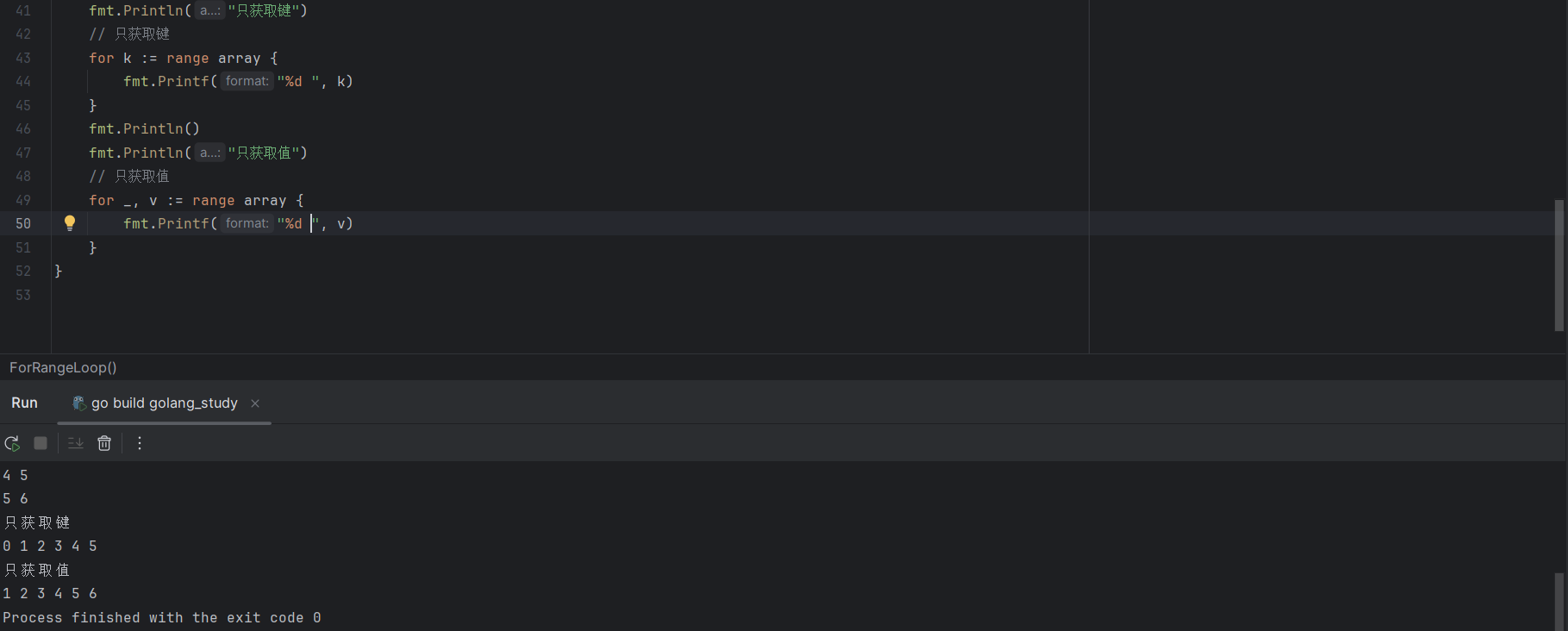
也可以只获取键,或者只获取值,代码示例如下:
// 只获取键
for k := range array {
fmt.Printf("%d ", k)
}
// 只获取值
for _, v := range array {
fmt.Printf("%d ", v)
}
5.3.5 基于条件判断循环
只有满足指定的条件才会执行循环体中的代码,代码示例如下:
sum := 0
i := 0
for i < 100 {
i++
sum += i
}
fmt.Println(sum)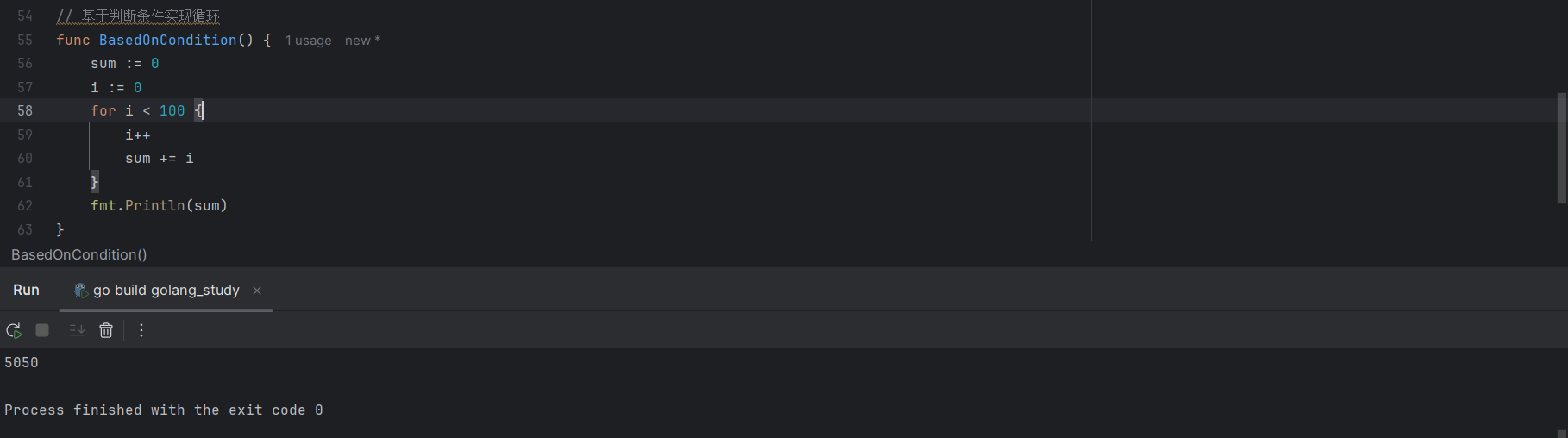
5.4 跳转语句
5.4.1 break与continue语句
Go语言支持在循环语句中通过break语句跳出循环,通过continue语句进入下一个循环。
break语句代码示例:
sum := 0
i := 0
for {
i++
if i > 100 {
break
}
sum += i
}
continue语句代码示例:
for i = 0; i < 5; i++ {
if i%2 == 0 {
continue
}
fmt.Printf("%d ", i)
}
5.4.2 标签
Go语言中的break和continue支持与标签结合跳转到指定的标签语句,标签通过 标签名 : 进行声明:
break 标签代码示例:
arr := [][]int{{1, 2, 3}, {4, 5, 6}, {7, 8, 9}}
ITERATOR1:
for i := 0; i < 3; i++ {
for j := 0; j < 3; j++ {
num := arr[i][j]
if j > 1 {
break ITERATOR1
}
fmt.Println(num)
}
}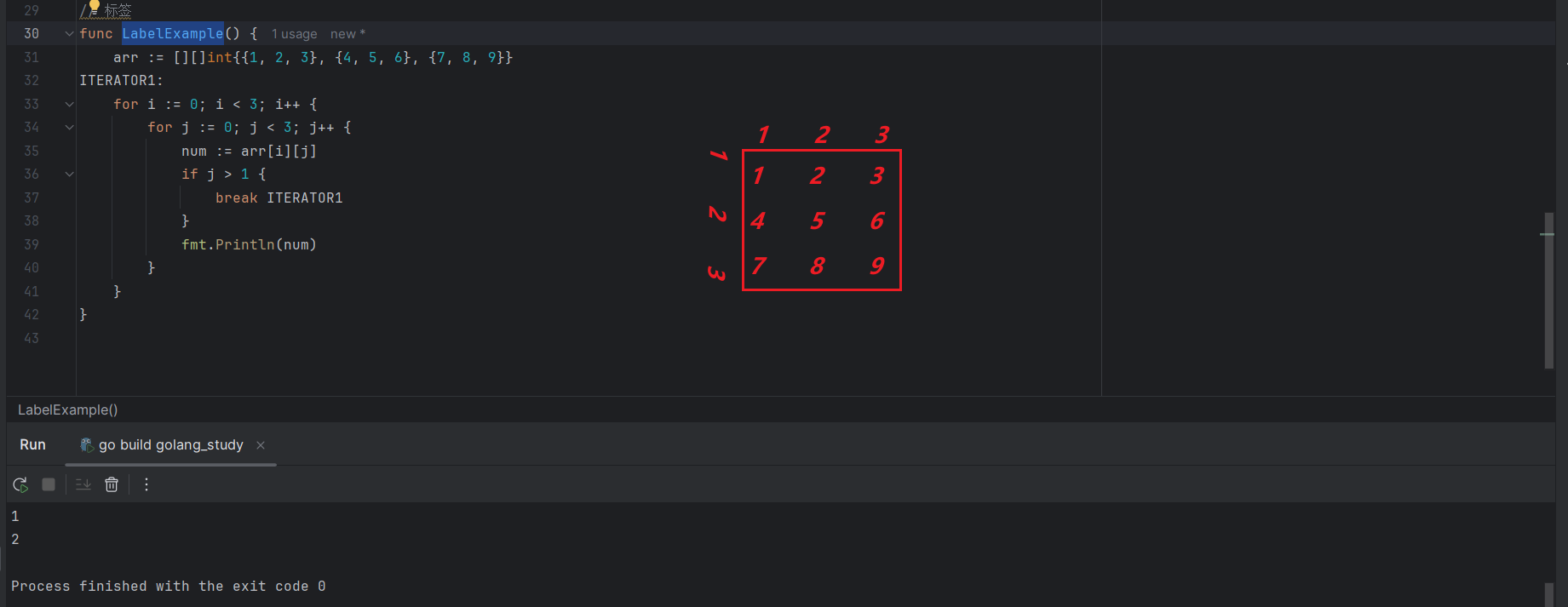
如上所示,当j>1,此时循环执行到arr[0,2],直接跳到标签ITERATOR1的位置,也即跳出了外层循环,同样的语句换成continue再次执行:
arr := [][]int{{1, 2, 3}, {4, 5, 6}, {7, 8, 9}}
ITERATOR1:
for i := 0; i < 3; i++ {
for j := 0; j < 3; j++ {
num := arr[i][j]
if j > 1 {
continue ITERATOR1
}
fmt.Println(num)
}
}
5.4.3 goto语句
goto语句并不建议使用,因为很容易造成代码的逻辑混乱,导致难以发现的Bug,代码示例如下:
arr := [][]int{{1, 2, 3}, {4, 5, 6}, {7, 8, 9}}
for i := 0; i < 3; i++ {
for j := 0; j < 3; j++ {
num := arr[i][j]
if j > 1 {
goto EXIT
}
fmt.Println(num)
}
}
EXIT:
fmt.Println("EXIT.")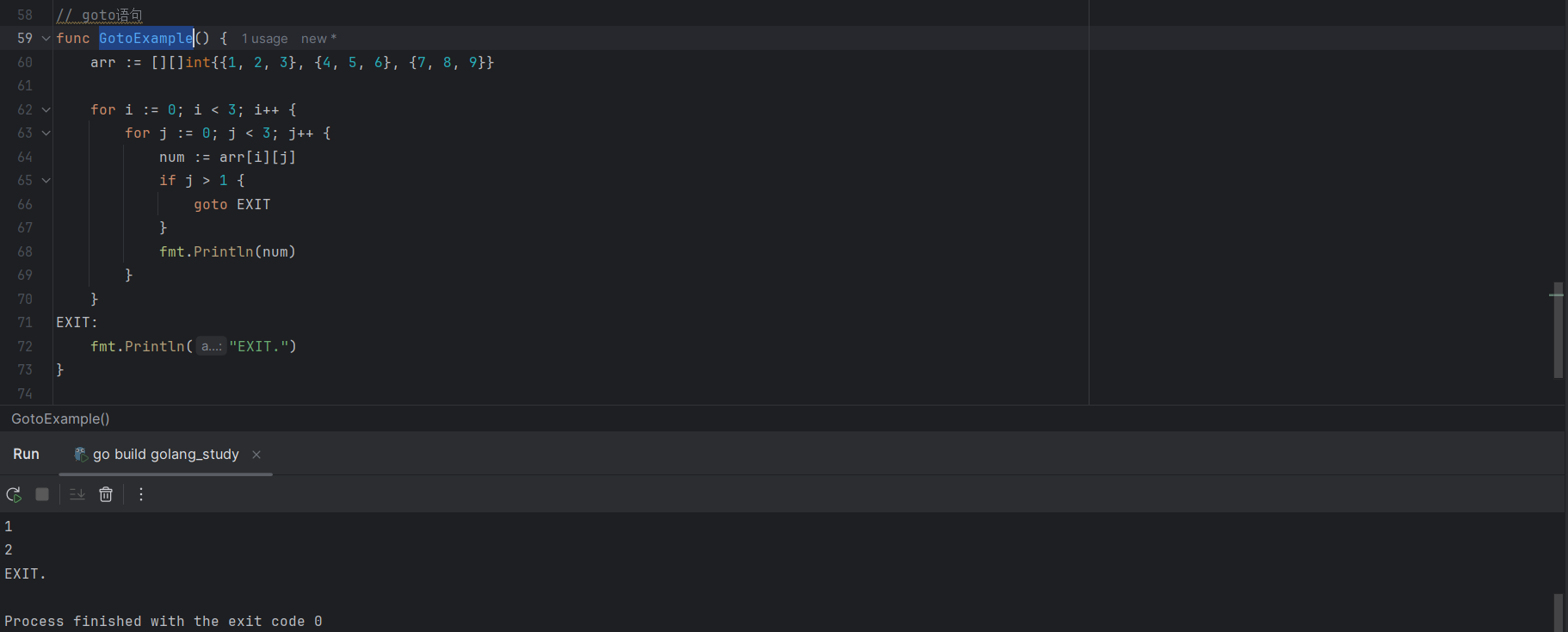
6.Go语言中的函数
Go语言中,函数主要有三种类型:
- 普通函数
- 匿名函数(闭包)
- 类方法
6.1 函数定义
Go语言函数的基本组成包括:关键字func、函数名、参数列表、返回值、函数体和返回语句。Go语言是强类型语言,无论是参数还是返回值,在定义函数时,都需要声明其类型。
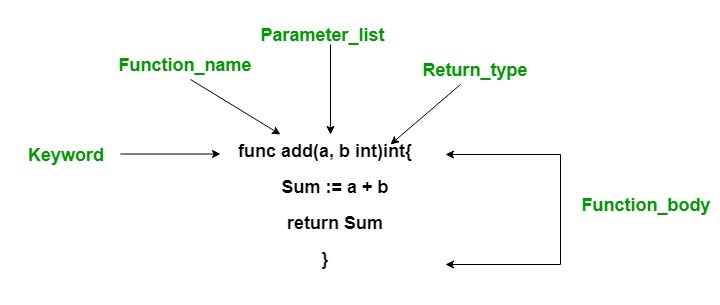
如下是Go语言中函数的一个简单示例:
// 参数类型 int
// 返回类型 int
func add(a, b int) int {
return a + b
}6.2 函数调用
6.2.1 调用同一个包定义的函数
如果函数在同一个包中,只需要直接调用即可:
func add(a, b int) int {
return a + b
}
func main() {
fmt.Println(add(1, 2)) // 3
}6.2.2 调用其他包定义的函数
如果函数是在不同的包中,需要先导入该函数所在的包,然后才能调用该函数,例如 Add 函数在 calculator 包中。
package calculator
func Add(a, b int) int {
return a + b
}在 main 包中调用Add函数。
package main
import (
"fmt"
"calculator"
)
func main() {
fmt.Println(calculator.Add(1, 2)) // 3
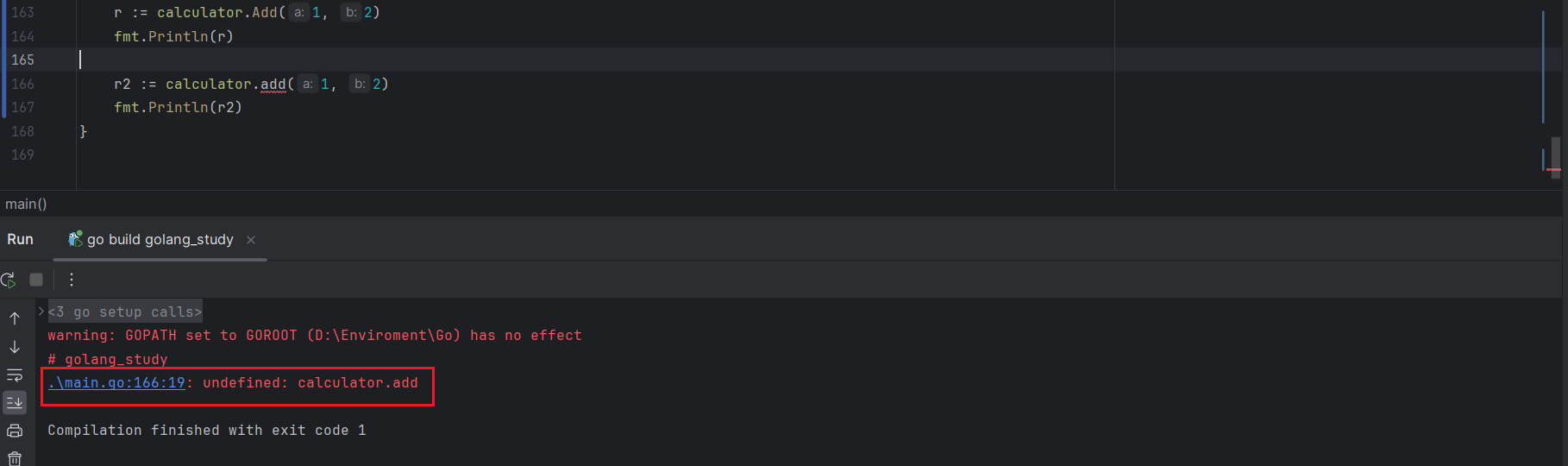
}注意:在调用其他包定义的函数时,只有这个函数名首字母大写的才可以被调用,例如函数名为add就会出现如下情况:
6.2.3 系统内置函数
Go语言中内置了常用的函数,如下所示
| 名称 | 说明 |
|---|---|
close | 用于在管道通信中关闭一个管道 |
len、cap | len 用于返回某个类型的长度(字符串、数组、切片、字典和管道),cap 则是容量的意思,用于返回某个类型的最大容量(只能用于数组、切片和管道) |
new、make | new 和 make 均用于分配内存,new 用于值类型和用户自定义的类型(类),make 用于内置引用类型(切片、字典和管道)。它们在使用时将类型作为参数:new(type)、make(type)。new(T) 分配类型 T 的零值并返回其地址,也就是指向类型 T 的指针,可以用于基本类型:v := new(int)。make(T) 返回类型 T 的初始化之后的值,所以 make 不仅分配内存地址还会初始化对应类型。 |
copy、append | 分别用于切片的复制和动态添加元素 |
panic、recover | 两者均用于错误处理机制 |
print、println | 打印函数,在实际开发中建议使用 fmt 包 |
complex、real、imag | 用于复数类型的创建和操作 |
6.3 参数传递
6.3.1 按值传参
Go语言默认使用按值传参来传递参数,也就是传递参数值的一个副本,函数收到传递进来的参数后,会将参数值拷贝给声明该参数的变量(也叫做形式参数,简称形参),如果在函数体中有对参数值做修改,实际上修改的是形参值,这不会影响到实际传递进来的参数值(也叫实际参数,简称实参)。
示例代码如下:
// a,b 是形式参数
func add(a, b int) int {
a *= 2
b *= 3
return a + b
}
func main() {
x, y := 1, 2
// x,y 是实际参数
z := add(x, y)
// z的值是x*2+y*3=8,但x,y的值并未改变
fmt.Printf("add(%d, %d) = %d\n", x, y, z)
}6.3.2 引用传参
如果需要实现在函数中修改形参值的同时改变实参,需要引用传参来实现,此时传递给函数的参数是一个指针,而指针代表的是实参的内存地址,修改指针引用的值即修改变量内存地址中存储的值,因此实参的值也会被修改。
示例代码如下:
// a,b 是形式参数
func add(a, b *int) int {
*a *= 2
*b *= 3
return *a + *b
}
func main() {
x, y := 1, 2
// x,y 是实际参数
z := add(&x, &y)
// z的值是x*2+y*3=8,由于我们直接修改了内存超出地址的值,因此x变为2,y变为6
fmt.Printf("add(%d, %d) = %d\n", x, y, z)
}在函数调用时,像切片(slice)、字典(map)、接口(interface)、通道(channel)这样的引用类型默认使用引用传参。
6.4 变长参数
变长参数指的是函数参数的数量不确定,可以按照需要传递任意数量的参数到函数。
6.4.1 基本定义和传值
只需要在参数类型前加上 ... 前缀,就可以将该参数声明为变长参数。
// 函数Myfunc()接受任意数量的参数,这些参数的类型全部是int
func Myfunc(numbers ...int){
for _,number := range numbers {
fmt.Println(number)
}
}
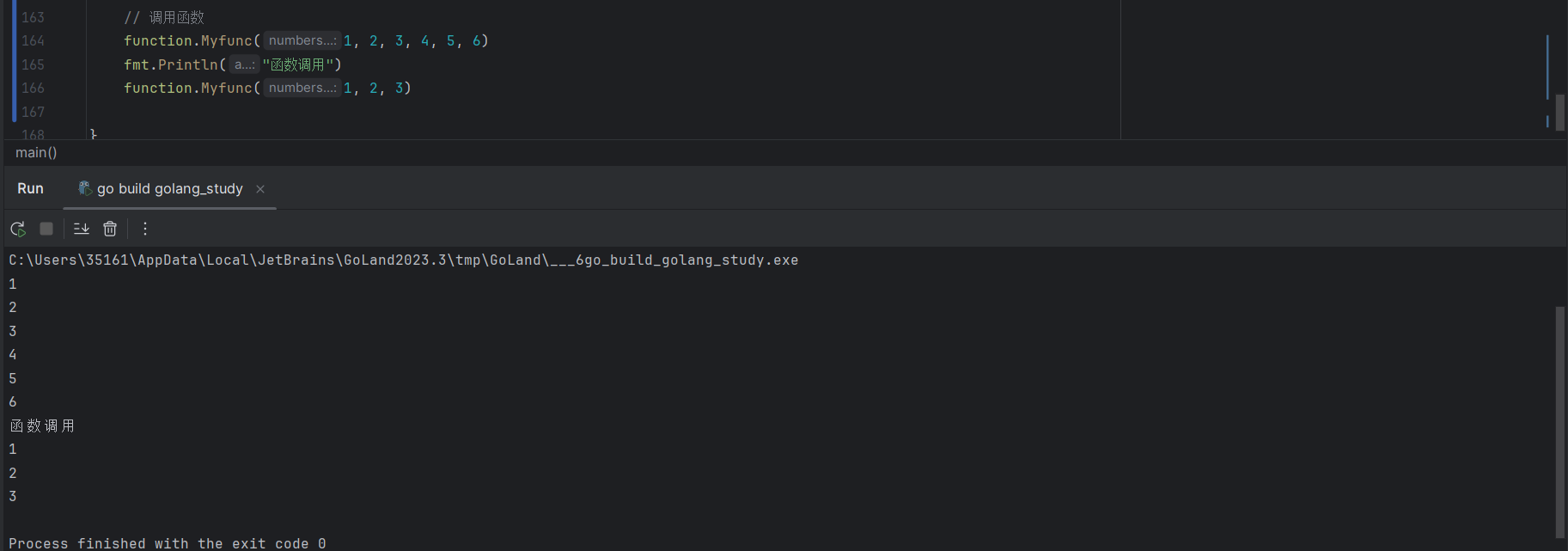
// 函数可以按照如下方式调用:
Myfunc(1,2,3,4,5,6)
Myfunc(1,2,3)函数调用测试:
变长参数还支持传递一个 []int 类型的切片,传递切片时需要在末尾加上 ... 作为标识,标识对应的参数类型是变长参数:
slice := []int{1,2,3,4,5,6}
Myfunc(slice...)
Myfunc(slice[1:3]...)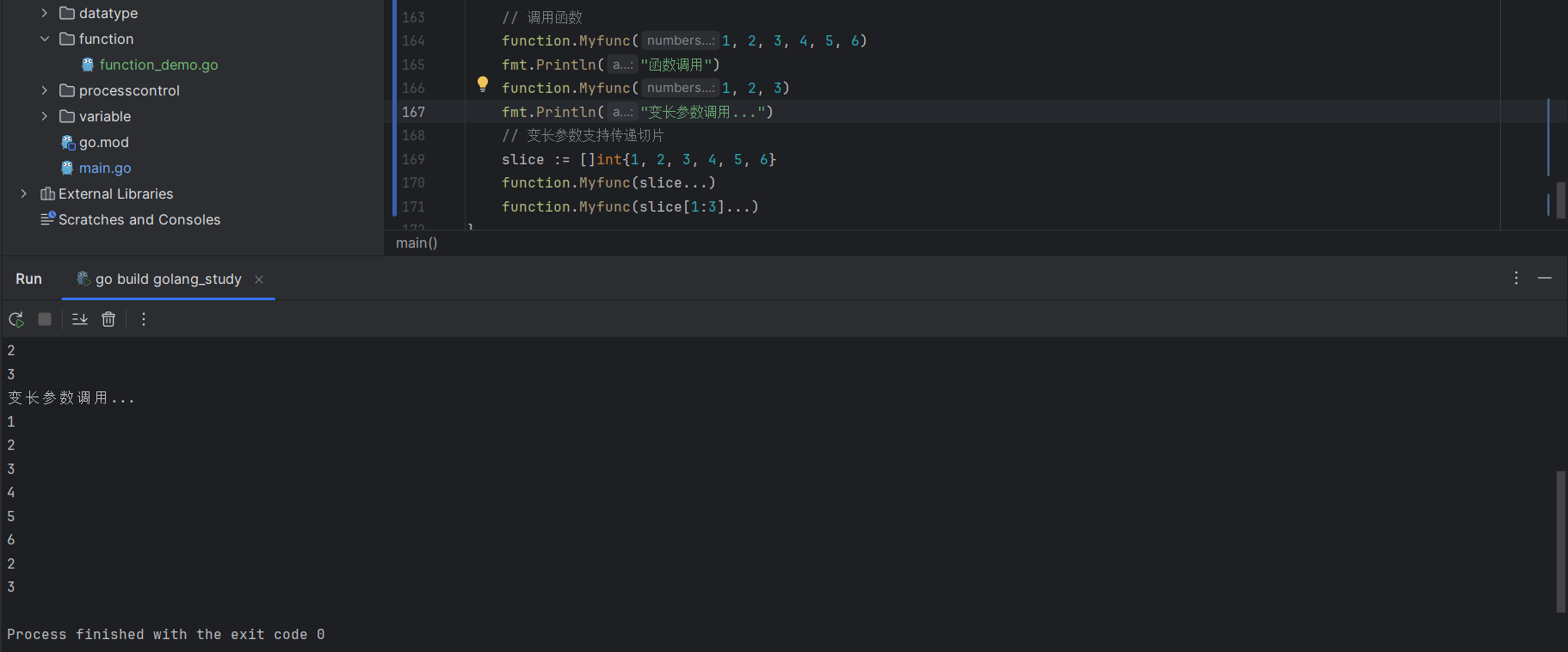
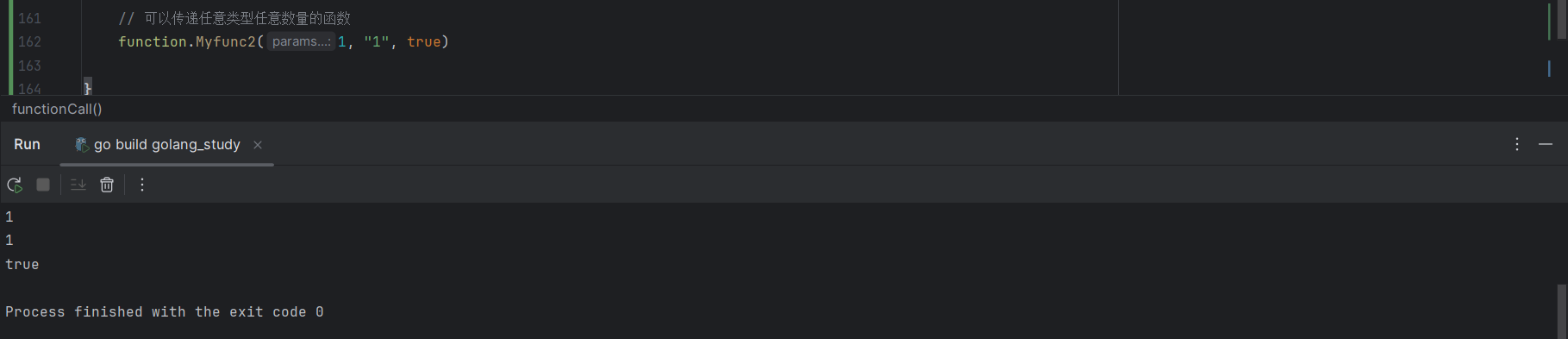
6.4.2 任意类型的变长参数(泛型)
Go语言中,可以通过指定变长参数类型为 interface{} 来实现参数的任意类型传递。
代码实现如下:
// 变长参数,可以传递任意个数的参数,类型无要求
func Myfunc2(params ...interface{}) {
for _, param := range params {
fmt.Println(param)
}
}
6.5 多返回值
6.5.1 多返回值
Go语言中,函数能够支持多返回值,经常用在程序出错的时候。
代码示例如下:
// 函数定义
func AddFunc(a, b *int) (int, error) {
if *a < 0 || *b < 0 {
err := errors.New("仅支持非负整数的相加")
return 0, err
}
return *a + *b, nil
}
// 函数调用
x, y := -1, 2
z, err := function.AddFunc(&x, &y)
if err != nil {
fmt.Println(err.Error())
return
}
fmt.Printf("%d + %d = %d", x, y, z)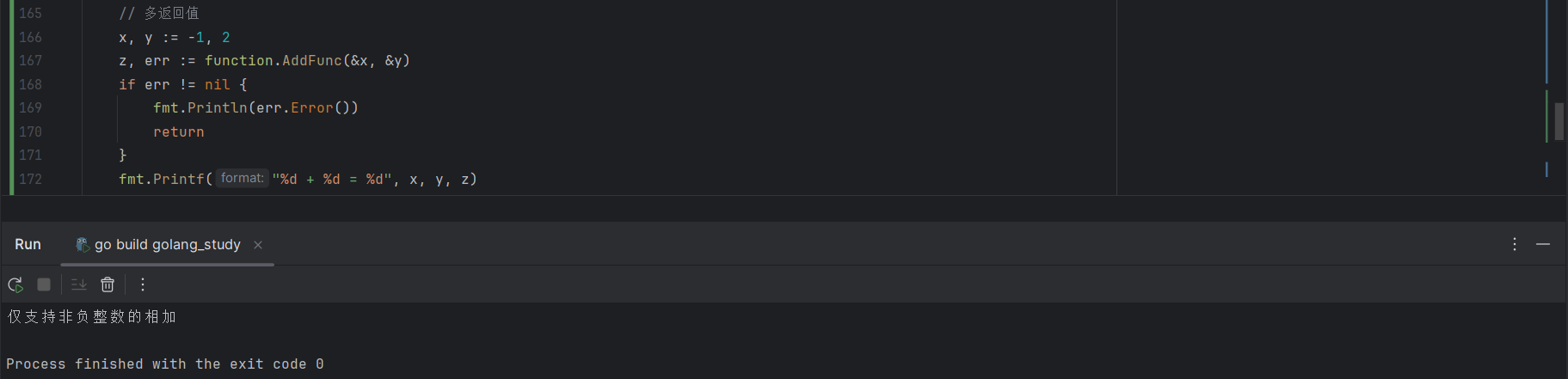
6.5.2命名返回值
函数设置多返回值时,还可以对返回值进行变量命名,这样就可以直接在函数中对返回值变量进行赋值,而不需要按照指定的返回值格式返回多个变量。
代码示例:
// 函数定义
func AddFunc2(a, b *int) (c int, err error) {
if *a < 0 || *b < 0 {
err = errors.New("仅支持非负整数的相加")
return
}
c = *a + *b
return
}
// 函数调用
x, y := -1, 2
z, err := function.AddFunc2(&x, &y)
if err != nil {
fmt.Println(err.Error())
return
}
fmt.Printf("%d + %d = %d", x, y, z)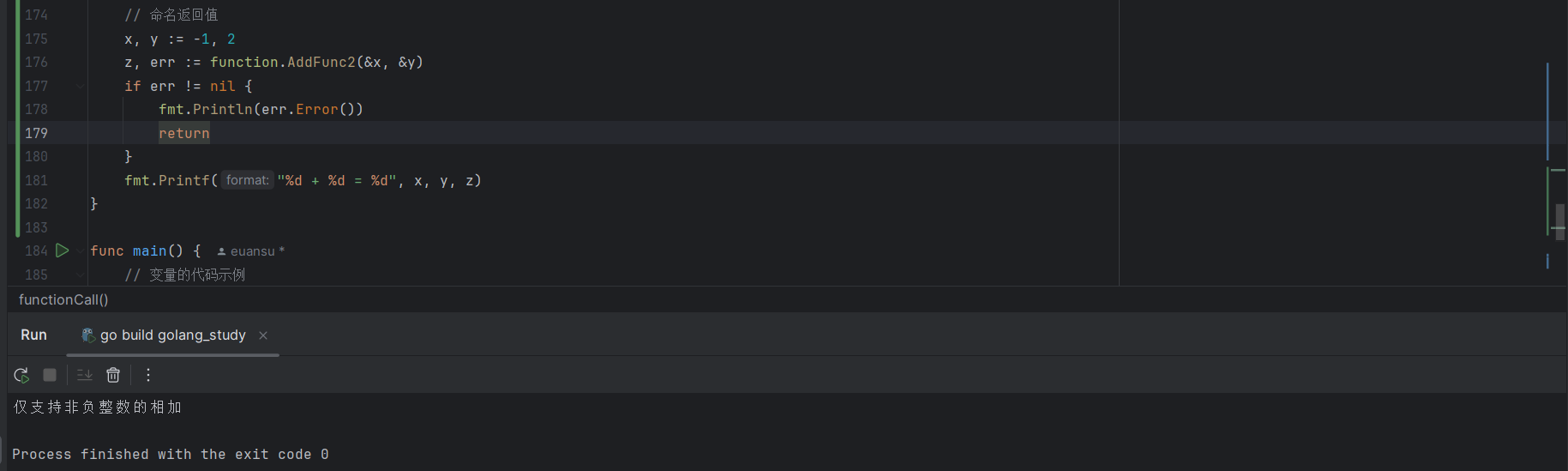
6.6 匿名函数与闭包
6.6.1 匿名函数的定义和使用
匿名函数是一种没有指定函数名的函数声明方式。
代码示例如下:
func(a,b int) int {
return a+b
}Go语言中,匿名函数也可以赋值给一个变量或者直接执行:
// 将匿名函数赋值给变量
sum := func(a,b int) int {
return a+b
}
// 调用匿名函数 add
fmt.Print(sum(1,2))
// 也可以在定义的时候,直接调用匿名函数
func(a,b int){
fmt.Println(a+b)
} (1,2)
6.6.2 匿名函数与闭包
**闭包:**指引用了外部函数作用域中的变量的函数。也即,闭包是一个函数及其相关引用环境的组合。
**匿名函数和闭包的关系:**匿名函数可以用来创建闭包,当一个匿名函数引用了外部函数作用域中的变量时,该匿名函数就成了一个闭包。
6.6.3 匿名函数的使用场景
6.6.3.1 保证局部变量的安全性
匿名函数内部声明的局部变量无法从外部修改,从而确保了安全性(类似类的私有属性)。
代码示例如下:
var j int =1
f := func(){
var i int = 1
fmt.Println(i,j)
}
f()
j += 2
f()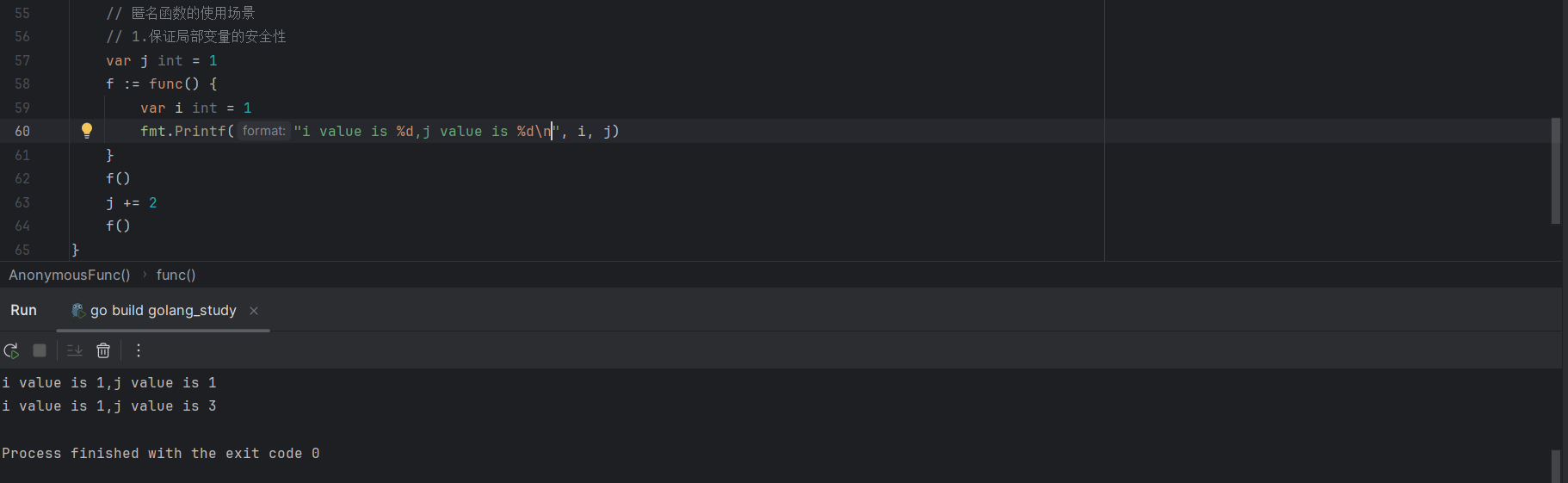
如上代码运行所示,匿名函数引用了外部变量j,所以同时也是个闭包,变量f指向的闭包引用了局部变量i和j,i在闭包内定义,其值被隔离,不能从外部修改变量,j在闭包外定义,所以可以从外部修改,闭包只是引用了变量j的值。
6.6.3.2 将匿名函数作为函数参数
匿名函数除了可以赋值给普通变量外,还可以作为函数参数传递到函数中进行调用,就像普通数据类型一样。
代码示例:
add := func(a, b int) int {
return a + b
}
func(call func(int, int) int) {
fmt.Println(call(1, 2))
}(add)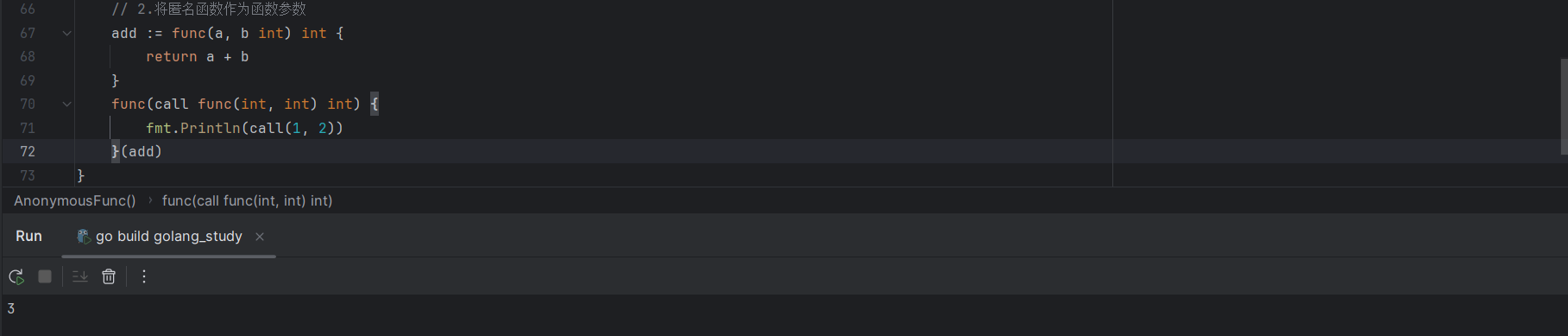
6.6.3.3 将匿名函数作为函数返回值
Go语言中,匿名函数也能够作为返回值使用。
代码示例:
func defaultAdd(a, b int) func() int {
return func() int {
return a + b
}
}
// 此时返回的是匿名函数
addFunc := defaultAdd(1, 2)
// 这里才会真正的执行加法操作
fmt.Println(addFunc())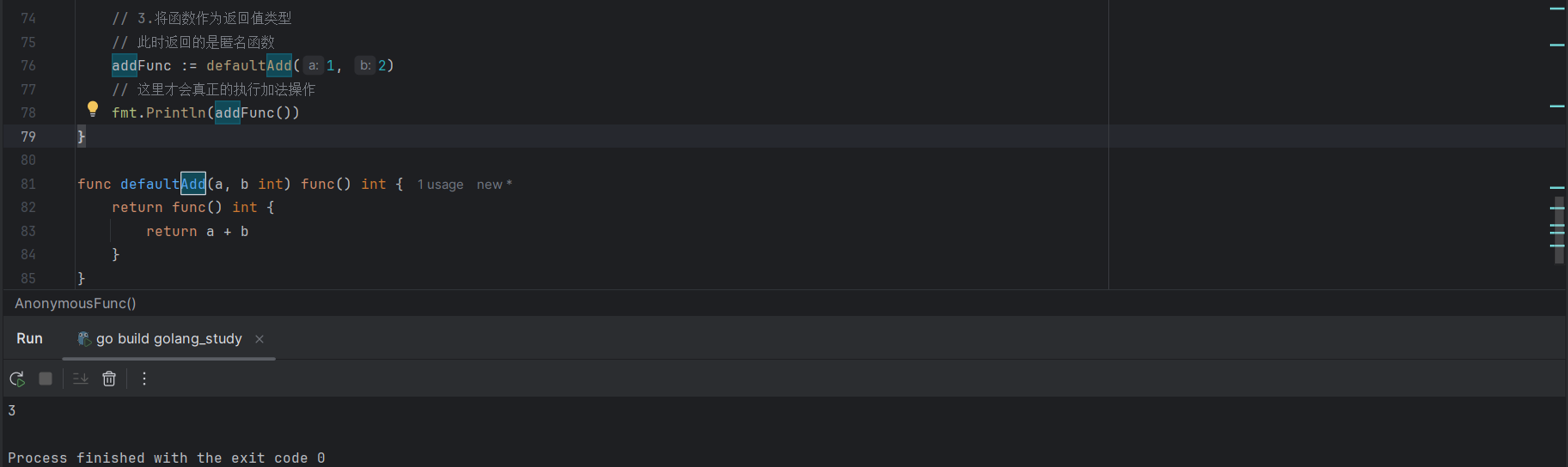
6.7 通过高阶函数实现装饰器模式
高阶函数
高阶函数,就是接收其他函数作为参数传入,或者把其他函数作为结果返回的函数。因此,之前提到的用匿名函数作为函数参数和将匿名函数作为函数返回值的示例都是高阶函数。
装饰器模式
装饰器模式(Decorator)是一种软件设计模式,其应用场景是为某个已经存在的功能模块(类或者函数)添加一些 装饰 功能,而又不会侵入和修改原有的功能模块。
通过高阶函数实现装饰器模式
编写一个基础的函数
// 实现一个简单的乘法运算 func Multiply(a, b int) int { return a * b }装饰器模式实现
// 为函数设置别名提高代码可读性 type MultiPlyFunc func(a, b int) int // 高阶函数实现装饰器 func ExecTime(f MultiPlyFunc) MultiPlyFunc { return func(a, b int) int { start := time.Now() // 开始时间 fmt.Println(start) c := f(a, b) //执行函数运算 end := time.Since(start) fmt.Println("执行耗时:", end) return c } }函数调用执行
// 高阶函数实现装饰器 a := 2 b := 8 // 装饰器 := 装饰器函数(基本函数) decorator := ExecTime(Multiply) c := decorator(a, b) fmt.Printf("%d x %d = %d\n", a, b, c)
7.面向对象式编程
7.1 类的定义、初始化和成员方法
7.1.1 类的定义和初始化
Go 语言的面向对象编程没有 class 、 extends 、implements 之类的关键字和相应的概念,而是借助结构体来实现类的声明,如下是定义一个学生类的方法:
type Student struct{
id uint
name string
male bool
score float64
}类名为 Student,并且包含了 id 、name、male、score 这四个属性。
相应的,Go 语言中也不支持构造函数、析构函数,需要我们自定义形如 Newxxx 这样的全局函数(首字母大写)作为类的初始化函数方法:
// 初始化方法(全量定义)
func NewStudent(id uint, name string, male bool, score float64) *Student {
return &Student{id, name, male, score}
}在如上函数中,通过传入 NewStudent 方法的字段对 Student 类进行初始化,并返回一个指向该类的指针。此外,还能够初始化指定字段,如下所示:
// 初始化方法(部分定义)
func NewStudentPart(id uint, name string, score float64) *Student {
return &Student{id: id, name: name, score: score}
}在 main 方法中调用初始化的方法,打印如下:
// 类的初始化
student := GoClass.NewStudent(1, "南歌", false, 100)
fmt.Println(student)
// male未定义,会默认为male的零值false
student2 := GoClass.NewStudentPart(1, "南歌", 100)
fmt.Println(student2)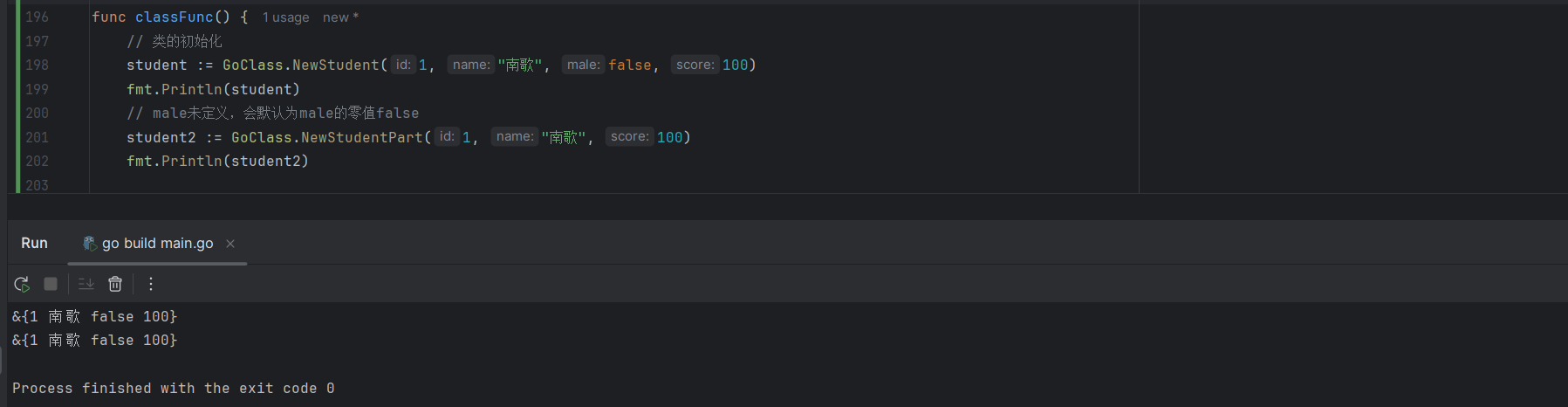
7.1.2 成员方法
同上所述,Go 语言中的成员方法也需要编写函数方法来实现,主要有 值方法 和 指针方法,两种方法的使用分别如下:
值方法
func (s Student) GetName() string {
return s.name
}通过定义的 GetName() 方法,就可以在初始化 Student 类后,调用 GetName() 成员方法,使用如下:
student := GoClass.NewStudent(1, "南歌", false, 100)
fmt.Println("Name:", student.GetName())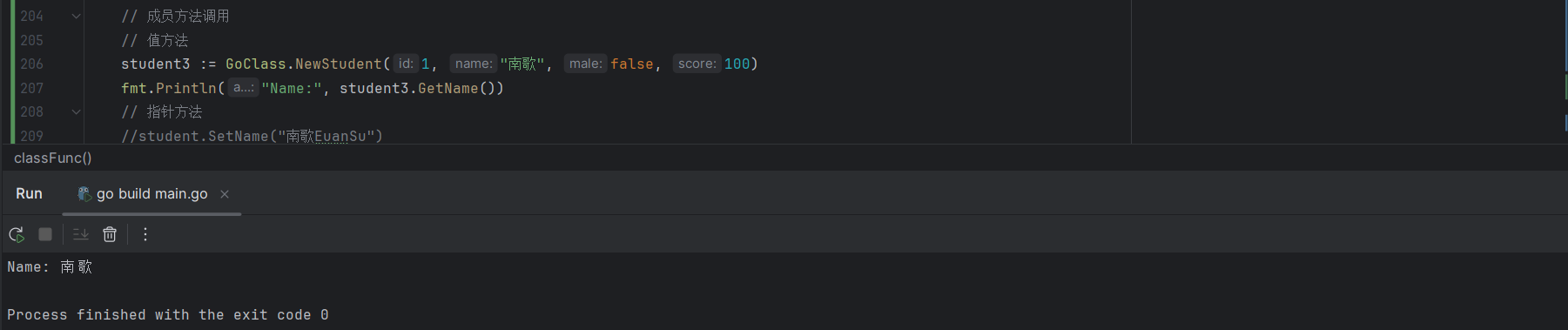
指针方法
上面的 值方法 只能够进行函数属性的读取,而不能做修改,可以使用如下方法简单进行测试。
func (s Student) SetName(name string) {
fmt.Println(s)
s.name = name
fmt.Println(s)
}在 main 函数中调用 SetName 方法,如下所示:
student3 := GoClass.NewStudent(1, "南歌", false, 100)
fmt.Println("Name:", student3.GetName())
student3.SetName("euansu")
fmt.Println("Name:", student3.GetName())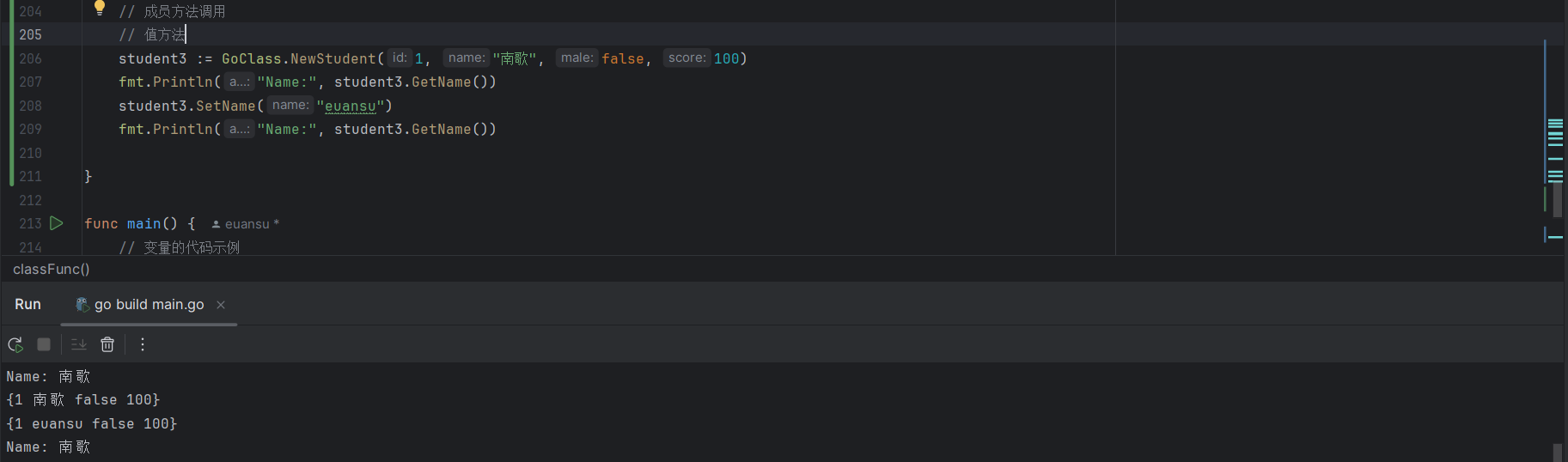
如上所示,在调用 SetName() 的时候,Student 并未接收函数的返回,因此即使修改了 s.name,但是类 Student 的属性也未被修改,如果要修改类 Student 的属性,就需要通过指针方法对其进行修改,如下所示:
func (s *Student) SetName(name string) {
s.name = name
}在 main 函数中按照如下方法进行调用。
student4 := GoClass.NewStudent(1, "南歌", false, 100)
fmt.Println("Name:", student4.GetName())
student4.SetName("euansu")
fmt.Println("Name:", student4.GetName()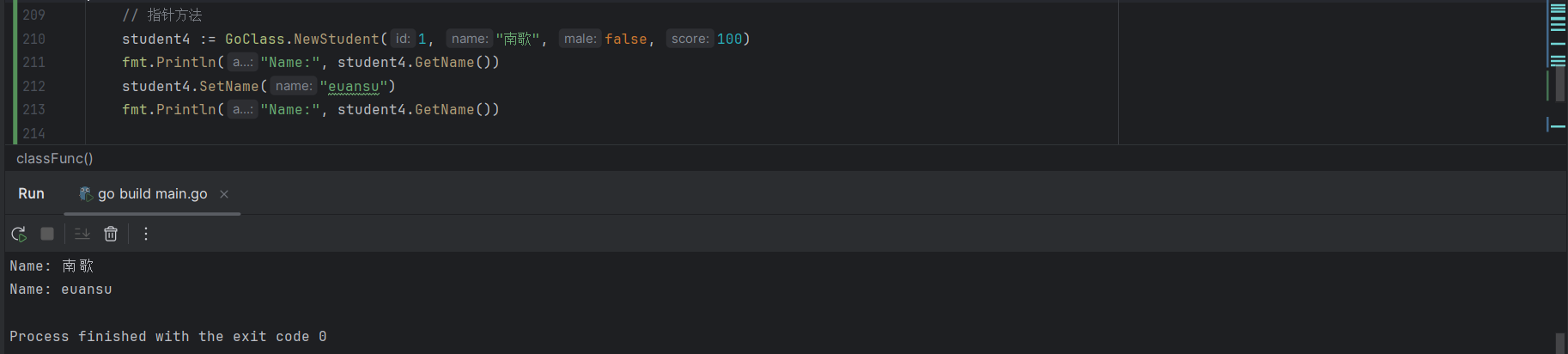
7.1.3 总结
- Go 语言与其他编程语言相比,弱化了类的概念,而是使用结构体定义类,类内部的数据类型与普通的数据类型一样,内置的数据类型也可以通过关键字指定为包含自定义成员方法的类。
- Go 语言中,类的成员方法有两种,分别是值方法和指针方法,其中值方法主要是用做读取类成员属性的场景,而指针方法则是用作修改类成员属性的场景。
7.2 通过组合实现类的继承和方法重写
要实现面向对象的编程,就必须实现面向对象编程的三大特性:封装、继承和多态。
7.2.1 封装
类的定义及其内部数据的定义可以看作是类的属性,基于类定义的函数方法则是类的成员方法。
7.2.2 继承
Go 语言中,没有直接提供继承相关的语法实现,可以通过 组合 的方式间接实现类似的功能,所谓组合,就是将一个类型嵌入到另一个类型,从而构建新的类型结构。
具体实现如下所示:
定义一个基础的类
Animal,其中定义了Name属性以及Call、FavorFood和GetName成员方法。type Animal struct { Name string } func (a Animal) Call() string { return "动物的叫声..." } func (a Animal) FavorFood() string { return "爱吃的食物..." } func (a Animal) GetName() string { return a.Name }定义一个新的类
Dog,继承Animal类的属性和成员方法。type Dog struct { Animal }在
main方法中对Animal和Dog进行调用测试。animal := GoClass.Animal{"中华田园犬"} dog := GoClass.Dog{animal} fmt.Println(dog.GetName()) fmt.Println(dog.Call()) fmt.Println(dog.FavorFood())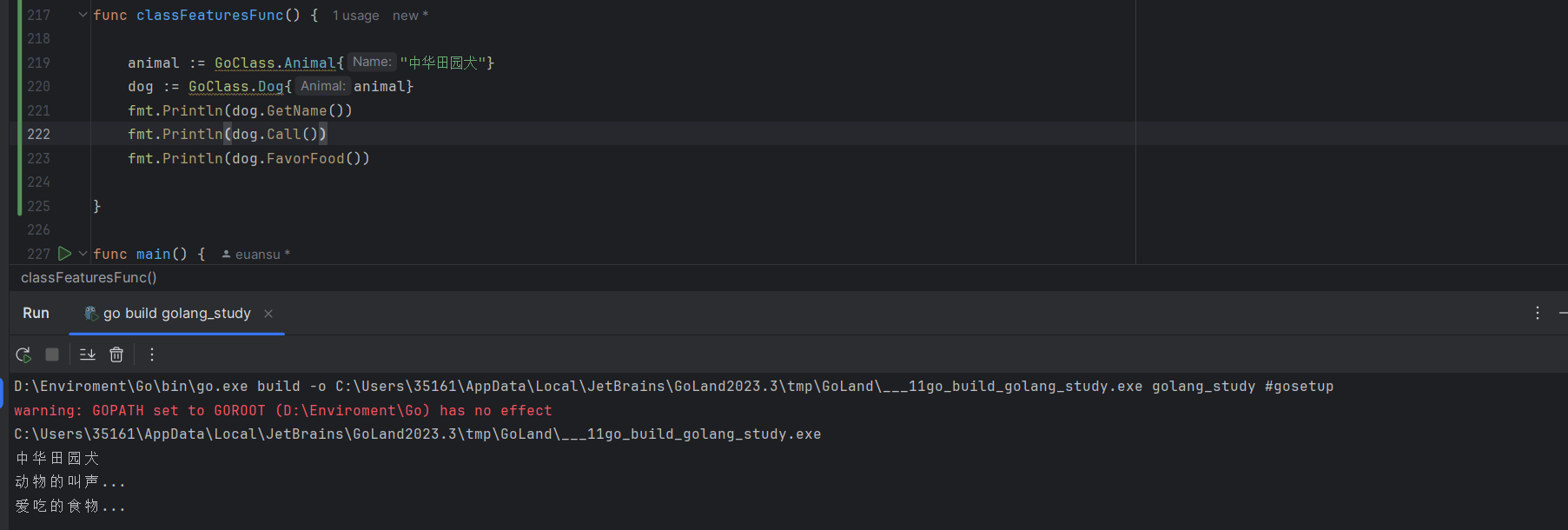
7.2.3 多态
这里重写方法 FavorFood 和 Call,如下所示:
func (d Dog) FavorFood() string {
return "骨头"
}
func (d Dog) Call() string {
return "汪汪汪"
}在 main 方法中进行调用,如下所示:
fmt.Print(dog.Animal.Call())
fmt.Println(dog.Call())
fmt.Print(dog.Animal.FavorFood())
fmt.Println(dog.FavorFood())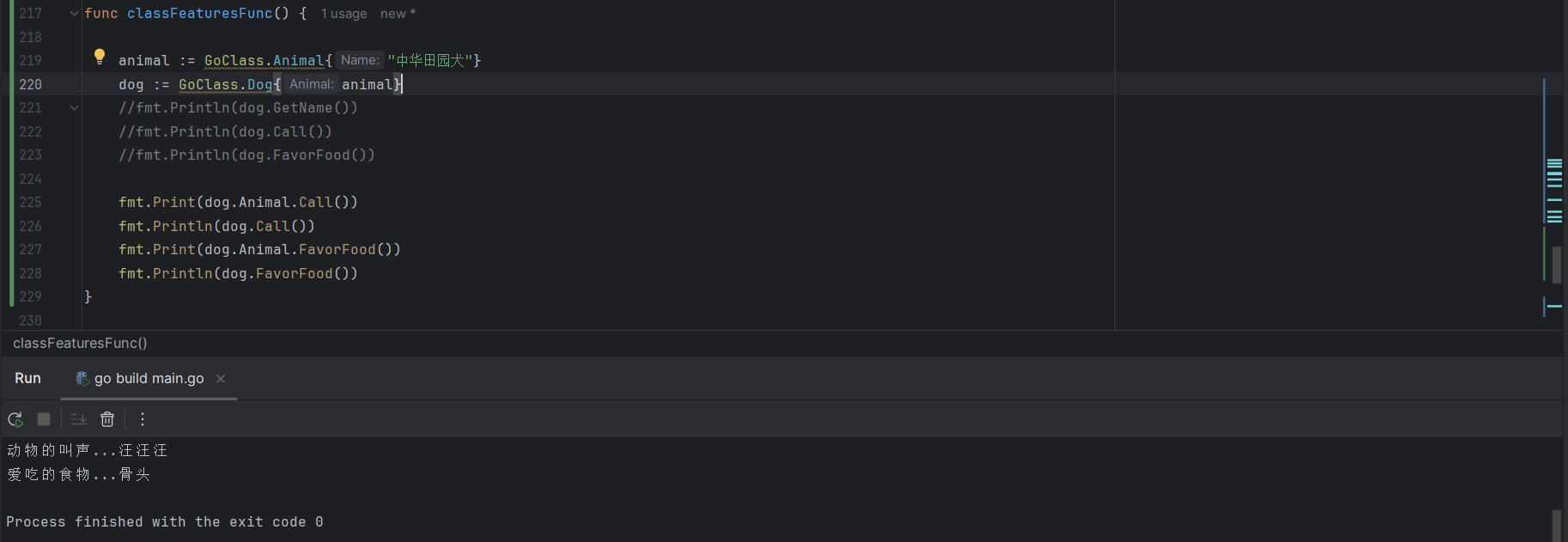
7.2.4 其他问题
7.2.4.1 多继承同名方法冲突处理
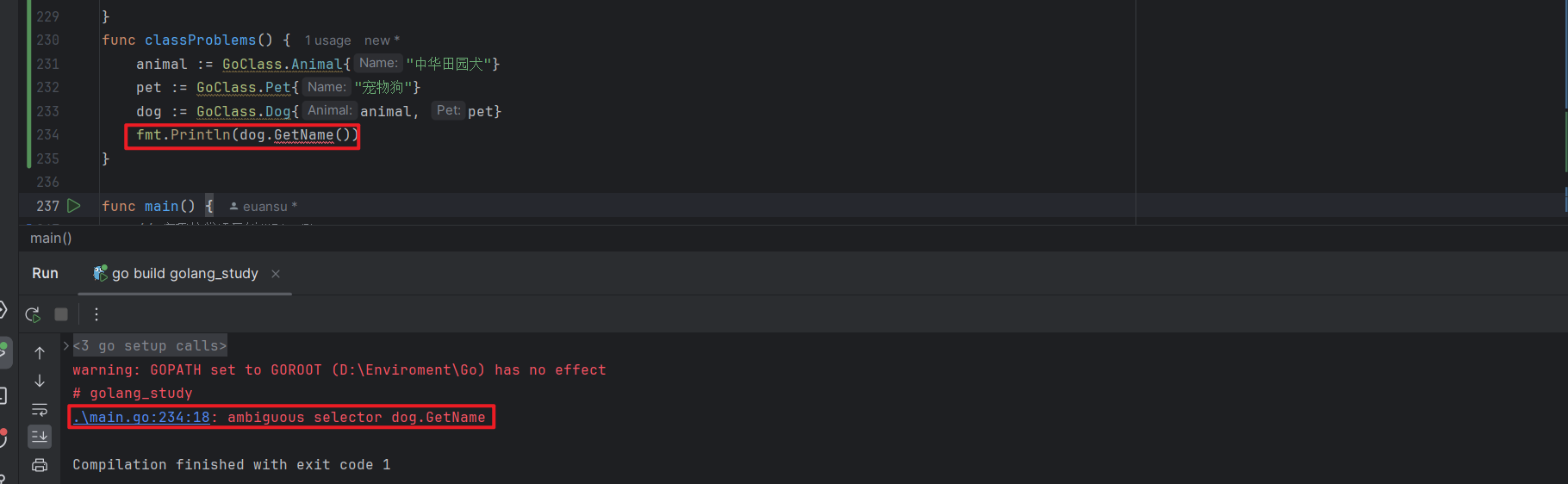
需要注意组合的不同类型之间包含同名方法,比如 Animal 和 Pet 都包含了 GetName 方法,如果子类 Dog 没有重写该方法,直接在 Dog 实例上调用的话会报错:
func main() {
animal := Animal{"中华田园犬"}
pet := Pet{"宠物狗"}
dog := Dog{animal, pet}
fmt.Println(dog.GetName())
}
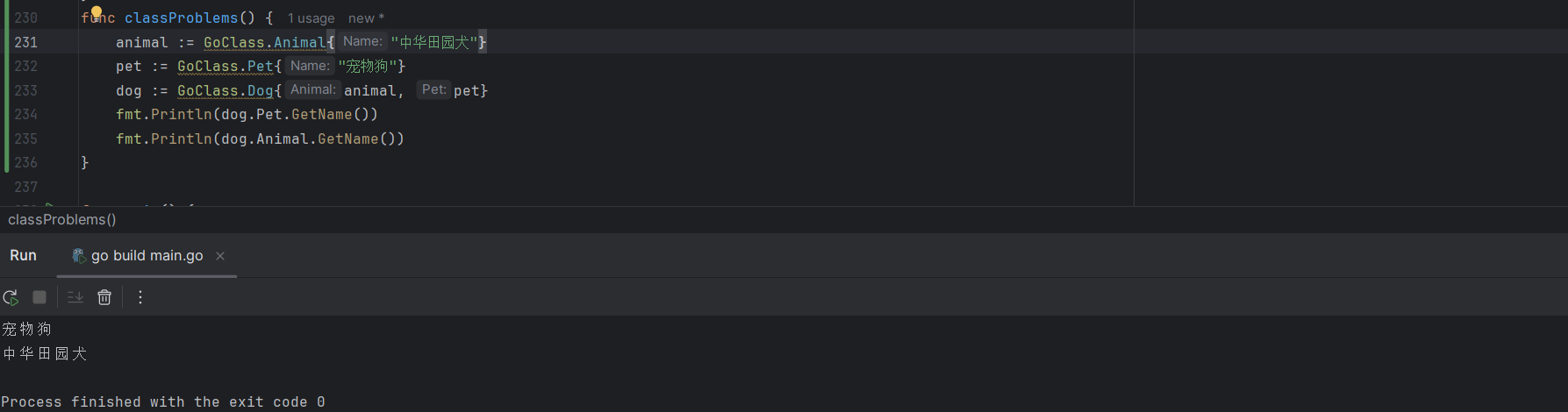
需要显式的指定调用那个父类的方法,修改如下则不报错:
func main() {
animal := Animal{"中华田园犬"}
pet := Pet{"宠物狗"}
dog := Dog{animal, pet}
fmt.Println(dog.GetName())
}
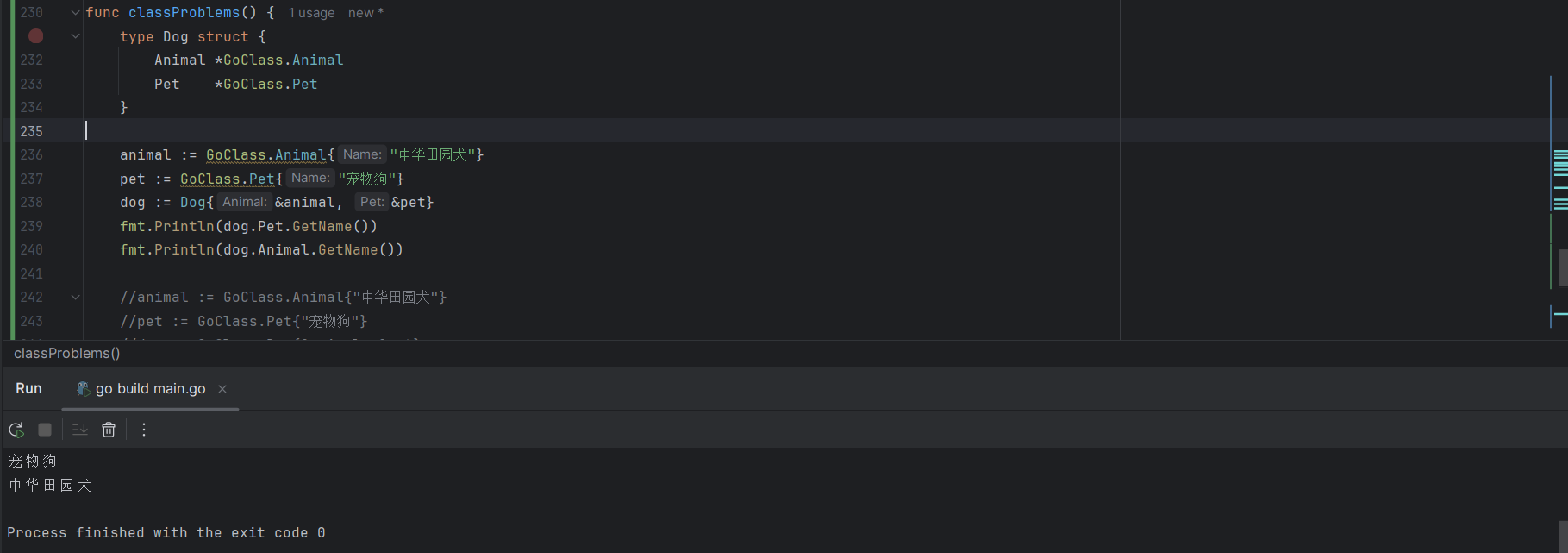
7.2.4.2 为组合类型设置别名
能够设置继承父类的名称,示例如下:
type Dog struct {
Animal *GoClass.Animal
Pet *GoClass.Pet
}
animal := GoClass.Animal{"中华田园犬"}
pet := GoClass.Pet{"宠物狗"}
dog := Dog{&animal, &pet}
fmt.Println(dog.Pet.GetName())
fmt.Println(dog.Animal.GetName())